LMM-Grounding-Collection1
Grounding LMM
面向grounding的多模态大模型large multimodal models。
FROMAGe
Grounding Language Models to Images for Multimodal Inputs and Outputs. CMU. ICML 2023
We propose an efficient method to ground pretrained text-only language models to the visual domain, enabling them to process arbitrarily interleaved image-and-text data, and generate text interleaved with retrieved images. Our method leverages the abilities of language models learnt from large scale text-only pretraining, such as in-context learning and free-form text generation. We keep the language model frozen, and finetune input and output linear layers to enable crossmodality interactions. This allows our model to process arbitrarily interleaved image-and-text inputs, and generate free-form text interleaved with retrieved images. We achieve strong zero-shot performance on grounded tasks such as contextual image retrieval and multimodal dialogue, and showcase compelling interactive abilities. Our approach works with any off-the-shelf language model and paves the way towards an effective, general solution for leveraging pretrained language models in visually grounded settings.
Issue:纯文本LLM不具备处理multimodal输入和输出的能力。
Solution: 作者基于纯文本LLM,加入额外输入投影层和输出投影层进行微调,在image caption和image-text retrieval两个任务上进行训练。
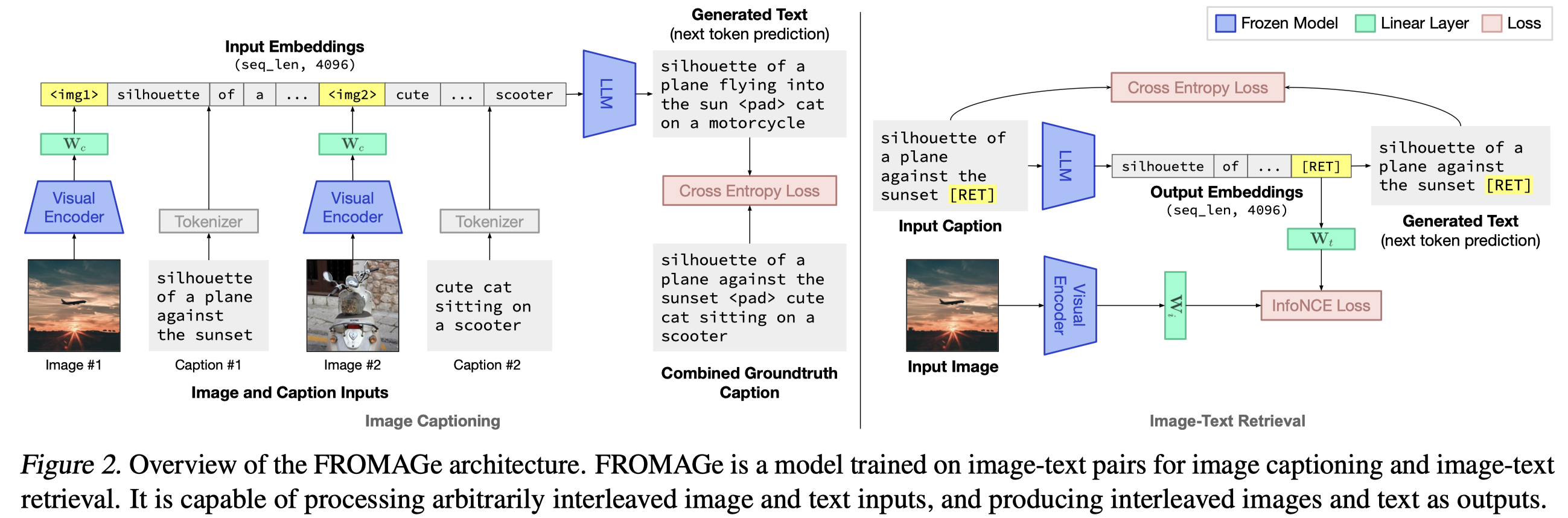
- 训练数据来源于Conceptual Captions (CC3M) dataset (Sharma et al., 2018),3.3 million图文对。
- OPT 6.7B作为LLM
- CLIP ViT-L/14作为visual encoder
- 对于图文检索,在输入text最后插入了一个特殊token
[RET],使用其输出embedding来检索图片,检索的图片数据来源是Visual Storytelling (VIST) dataset (Huang et al., 2016). 作者的方法并不具备生成图片能力,只有检索现有图片能力
这篇论文训练得到的LMM只有image-level的grounding能力,只能够把整个text匹配到对应的image上。
Shikra
Shikra: Unleashing Multimodal LLM’s Referential Dialogue Magic. arXiv 2023. 北航-上交. 代码.
In human conversations, individuals can indicate relevant regions within a scene while addressing others. In turn, the other person can then respond by referring to specific regions if necessary. This natural referential ability in dialogue remains absent in current Multimodal Large Language Models (MLLMs). To fill this gap, this paper proposes an MLLM called Shikra, which can handle spatial coordinate inputs and outputs in natural language. Its architecture consists of a vision encoder, an alignment layer, and a LLM. It is designed to be straightforward and simple, without the need for extra vocabularies, position encoder, pre-/post-detection modules, or external plugin models. All inputs and outputs are in natural language form. Referential dialogue is a superset of various vision-language (VL) tasks. Shikra can naturally handle location-related tasks like REC and PointQA, as well as conventional VL tasks such as Image Captioning and VQA. Experimental results showcase Shikra’s promising performance. Furthermore, it enables numerous exciting applications, like providing mentioned objects’ coordinates in chains of thoughts and comparing user-pointed regions similarities. Our code and model are accessed at https://github.com/shikras/ shikra.
Issue:作者认为之前的LMM忽略了多模态指向式的对话:

作者使用LLaVA-13B,尝试让其回答下面的问题来探究其是否具有空间位置理解的能力:
Which part is in if the picture is divided equally into four 2 by 2 parts? Choose from: (A) Top-left (B) Top-right (C) Bottom-left (D) Bottom-right.
使用LVIS数据集中的测试数据,结果发现,llava的回答正确率只有25.96%,近乎随机猜测。
Solution: 作者基于Vicuna-7/13B,利用CLIP ViT-L/14作为视觉编码器,让LLM直接学会输出bounding box的坐标。bounding box的坐标被缩放到\(0-1\)。属于比较早的grounding LMM工作。
作者的task instruction通过在不同task中加入grounding坐标来强化模型能力。

MiniGPT-v2
MiniGPT-v2: Large Language Model As a Unified Interface for Vision-Language Multi-task Learning. arXiv 2023. KAUST-Meta. 代码.
Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. Towards this objective, we introduce MiniGPT-v2, a model that can be treated as a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to better distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After the three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual questionanswering and visual grounding benchmarks compared to other vision-language generalist models. Our model and codes are available at https://minigpt-v2.github.io/.
Issue:作者认为不同task之间的差距导致训练适应各种task的LMM变得困难。
Solution: 作者设计了task-oriented instruction training scheme来减小指令的ambiguity。
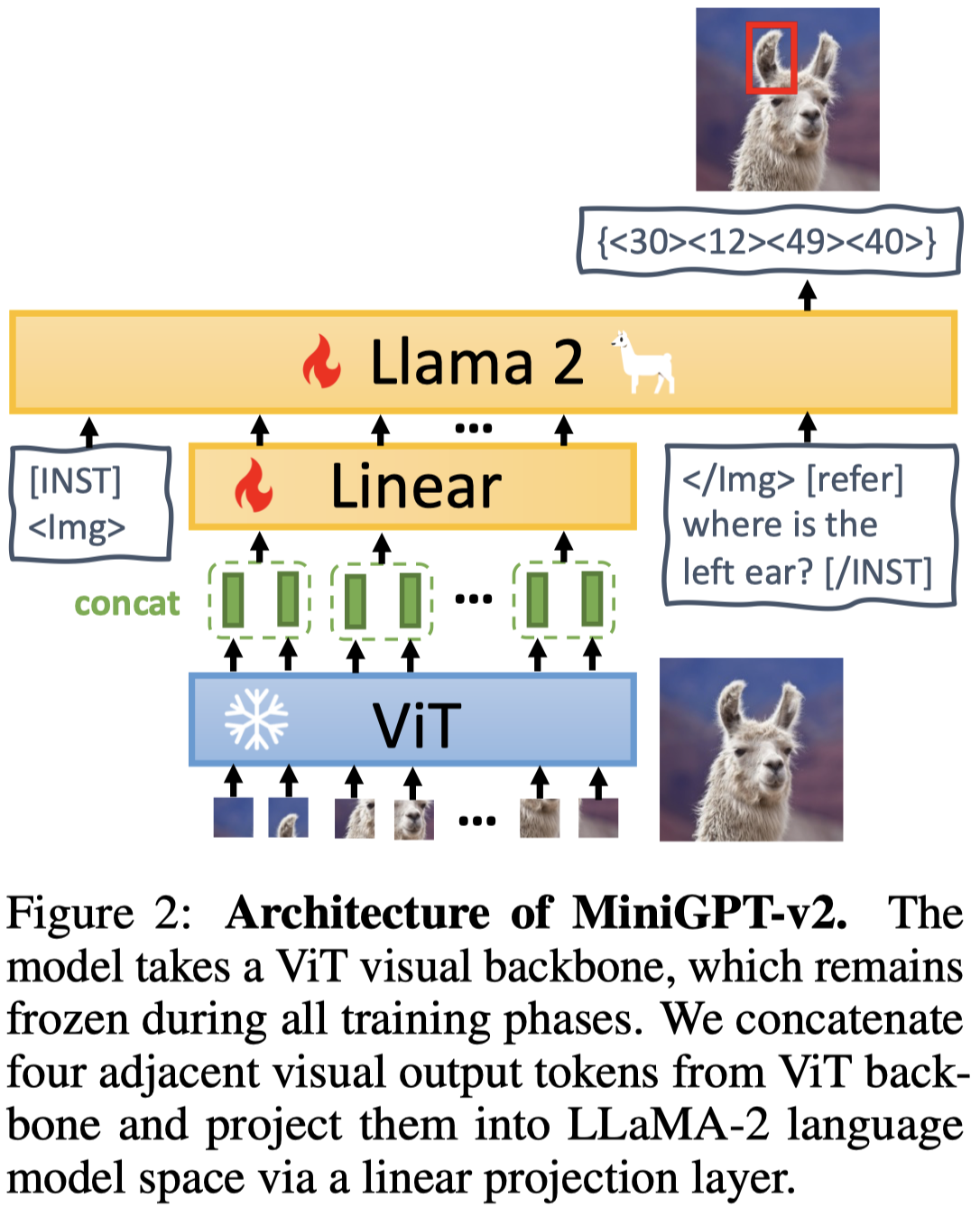
LLM采用LLaMA2-chat (7B),visual encoder采用EVA模型。有个小trick是由于作者把image的分辨率提升到448x448,为了减小visual tokens数量,作者拼接4个邻接tokens,再利用linear projection投影到1个embedding。坐标缩放到\(0-100\)。
作者的task模板:

不同的task identifier:

Kosmos-2
Grounding Multimodal Large Language Models to the World. 中科大-微软. ICLR 2024. 代码.
We introduce Kosmos-2, a Multimodal Large Language Model (MLLM), enabling new capabilities of perceiving object descriptions (e.g., bounding boxes) and grounding text to the visual world. Specifically, we represent text spans (i.e., referring expressions and noun phrases) as links in Markdown, i.e., “[text span] (bounding boxes)”, where object descriptions are sequences of location tokens. To train the model, we construct a large-scale dataset about grounded image-text pairs (GrIT) together with multimodal corpora. Kosmos-2 integrates the grounding capability to downstream applications, while maintaining the conventional capabilities of MLLMs (e.g., perceiving general modalities, following instructions, and performing in-context learning). Kosmos-2 is evaluated on a wide range of tasks, including (i) multimodal grounding, such as referring expression comprehension and phrase grounding, (ii) multimodal referring, such as referring expression generation, (iii) perception-language tasks, and (iv) language understanding and generation. This study sheds a light on the big convergence of language, multimodal perception, and world modeling, which is a key step toward artificial general intelligence. Code can be found in https://aka.ms/kosmos-2.
作者在Kosmos-1的基础上训练Kosmos-2,增强了其grounding和referring的能力,即在输入和输出都可以进行带有bounding box:

为了训练,首先作者基于LAION-2B (Schuhmann et al., 2022) and COYO-700M (Byeon et al., 2022)数据集中的图文对构造了a web-scale dataset of grounded image-text pairs (GrIT)。这个数据集中的数据标记text spans和对应的bounding box类似于markdown标记超链接的格式。包括91M images, 115M text spans, and 137M associated bounding boxes。
下面是创建数据集的pipeline:
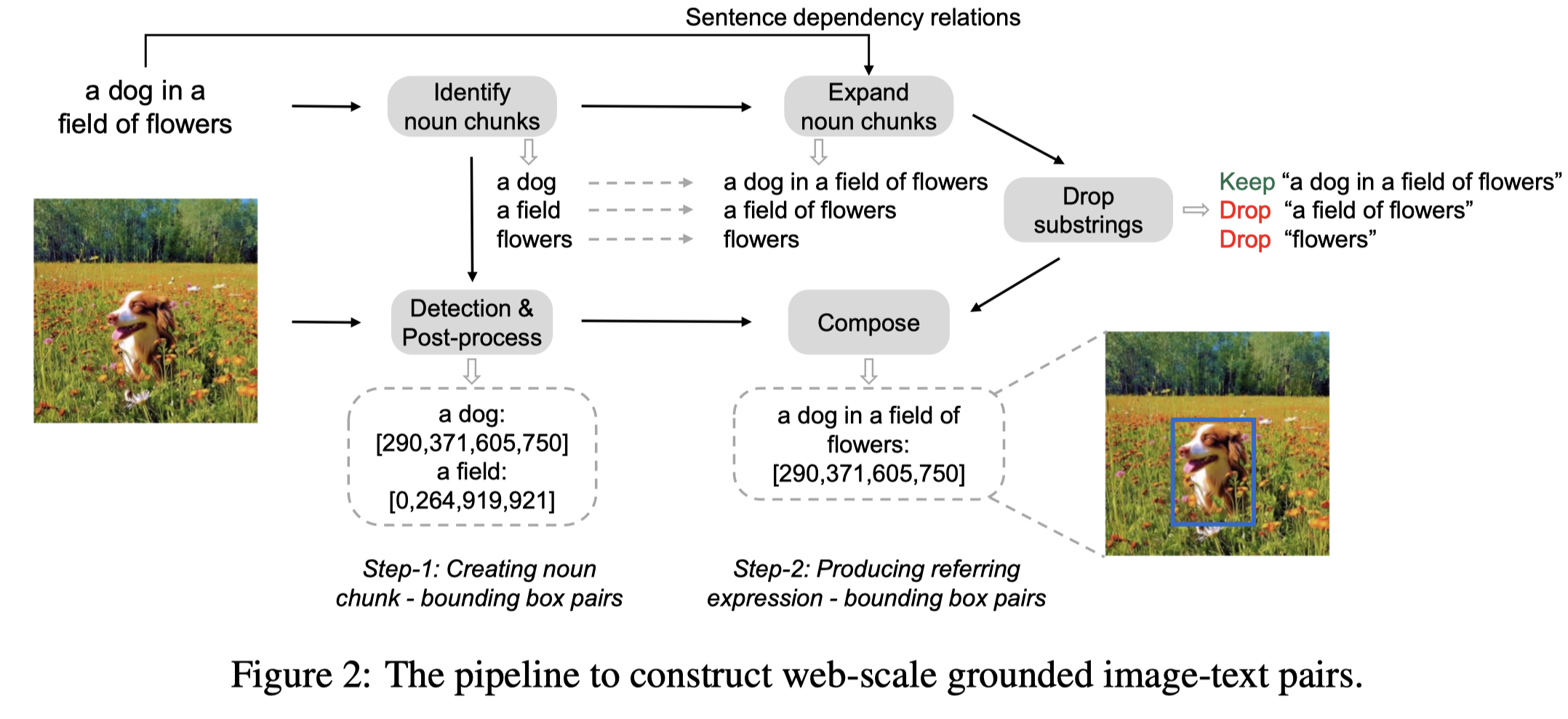
利用了GLIP识别对应短语的bounding box,具体构造细节参考论文。
为了处理bounding box,作者首先把连续数值形式的bounding box转化为离散形式。
一个image划分为\(P\times P\)个bin,每个bin有对应的location token;从location token返回坐标表示时,使用每个bin的中心pixel的坐标。bin和ViT里的patch概念的区别不大,个人认为仅仅是在论文里区分这是两种不同size划分。
每个bin有对应的位置编号,这样一个bounding box原始使用top-left point (\(x_{tl}\), \(y_{tl}\)) 和bottom-right point \(x_{br}\), \(y_{br}\))表示,现在直接使用两个角落在哪个bin就可以表示了:
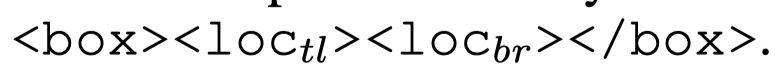
<box>是特殊标记。如果一个text span对应多个bounding box,就使用特殊标记<delim>进行分隔即可:
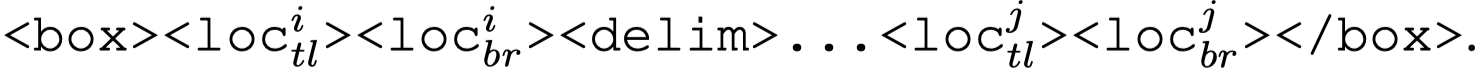
下面是一个具体的输入表示序列:

其中的<grounding>特殊token表示后面的序列包括了text spans以及对应的bounding box。
模型训练过程:
- 在构造的GrIT数据集上训练,256 V100 GPUs for 24 hours。当需要执行grounding输出时,就加上
<grounding>token。基于Magneto Transformers 1.6B,设定的bin是\(32\times 32\)。 - 进行指令微调,We combine vision-language instruction dataset (i.e., LLaVA-Instruct (Liu et al., 2023a)) and language-only instruction datasets (i.e., Unnatural Instructions (Honovich et al., 2022) and FLANv2 (Longpre et al., 2023)) with the training data to tune the model. 同时也进一步利用GrIT数据集构造指令数据
LLaVA-G
LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models. ECCV 2024. 港科大.
With the recent significant advancements in large multimodal models (LMMs), the importance of their grounding capability in visual chat is increasingly recognized. Despite recent efforts to enable LMMs to support grounding, their capabilities for grounding and chat are usually separate, and their chat performance drops dramatically when asked to ground. The problem is the lack of a dataset for grounded visual chat (GVC). Existing grounding datasets only contain short captions. To address this issue, we have created GVC data that allows for the combination of grounding and chat capabilities. To better evaluate the GVC capabilities, we have introduced a benchmark called Grounding-Bench. Additionally, we have proposed a model design that can support GVC and various types of visual prompts by connecting segmentation models with language models. Experimental results demonstrate that our model outperforms other LMMs on Grounding-Bench. Furthermore, our model achieves competitive performance on classic grounding benchmarks like RefCOCO/+/g and Flickr30K Entities.
Issue:之前的LMM的grounding能力和chat能力是分离的,当要求进行grounding任务的时候,chat的性能会下降。例如MiniGPT-V2这些模型,当进行grounded caption generation时候只能生成short caption
Solution: 作者首先利用COCO数据集,调用GPT-4,构建了专门用于grounding微调的数据集。

数据集中的数据插入特殊符号<seg>用于获取输出特征,用于grounding:
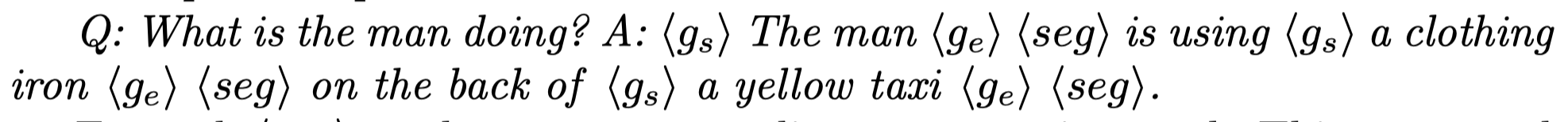
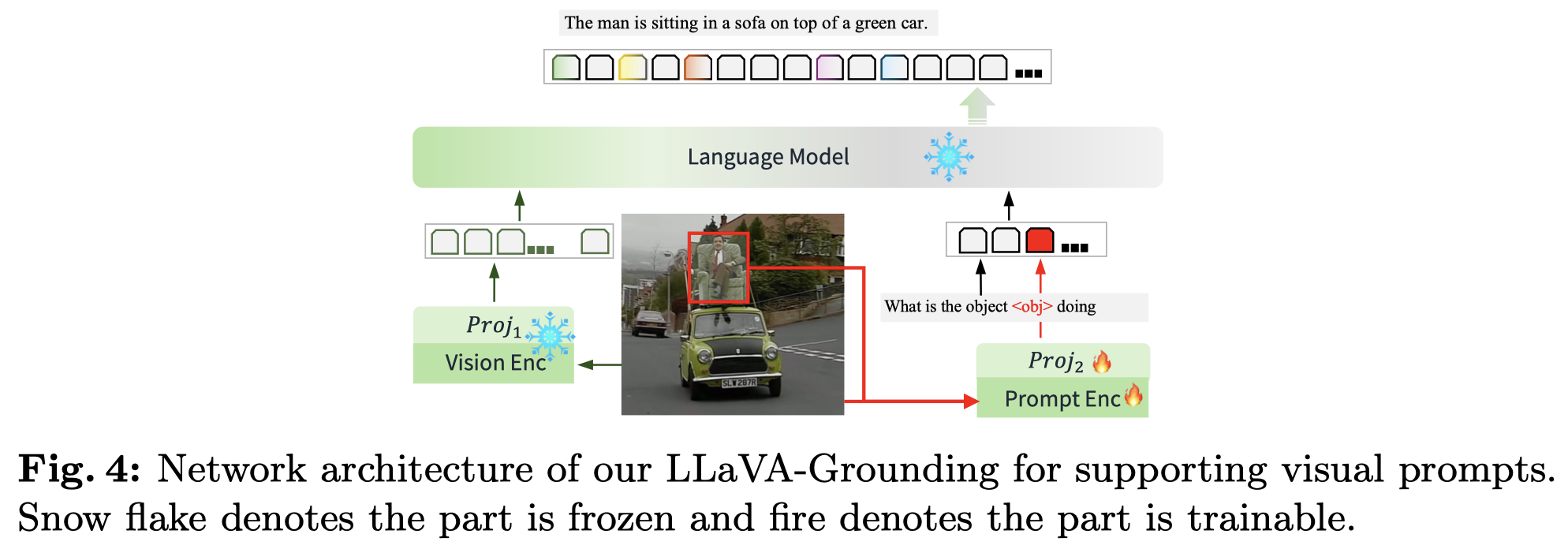
作者的方法结构在LLaVA基础上加入了两个特殊结构,visual prompt encoder和grounding model。
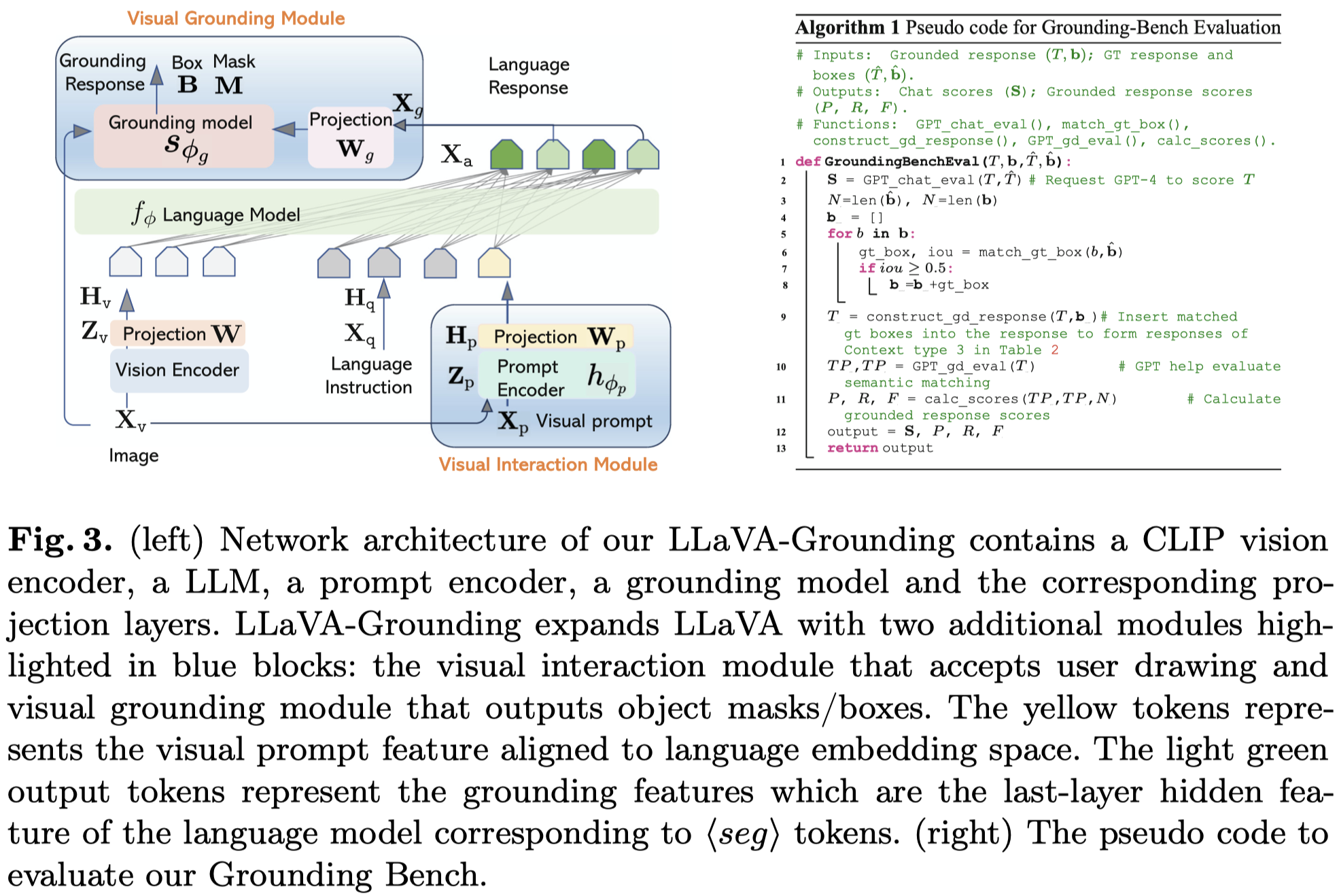
- visual prompt encoder用于处理用户输入的visual prompt,采用pre-trained
Semantic-SAM模型。其接收visaul prompt和image输入,输出加入了额外的投影层用于和language model对齐 - grounding model使用pretrained
OpenSeeD模型,接收<seg>token输出embedding,输出对应的bounding box和masks - LLM部分采用
Vicuna-7b,vision encoder采用CLIP。
由于加入了额外的模型,训练过程更加复杂,分为3个阶段和可选的第4阶段:
Pretraining for Alignment:第一阶段是训练和alignment有关的参数,vision和language之间alignment的投影层;输出
<seg>embedding和grounding model之间的投影层,以及grounding model本身的参数。涉及的参数为\(\{ W,W_g,\phi_g \}\)。Instruction Tuning for Grounded Visual Chat:在作者构建的Grounded Visual Chat (GVC)数据上,训练除了vision encoder之外的参数,包括\(\{ W, W_g, \phi, \phi_g \}\)。
Extension to Visual Prompt:第三阶段引入visual prompt encoder,训练参数包括\(\{ \phi_p, W_p \}\)。
Set-of-Mark (SoM) Prompts (Optional): 针对使用marks作为visual prompt进行训练,通过在image上加入包括标号的标记,让LLM可以根据标记进行回答:
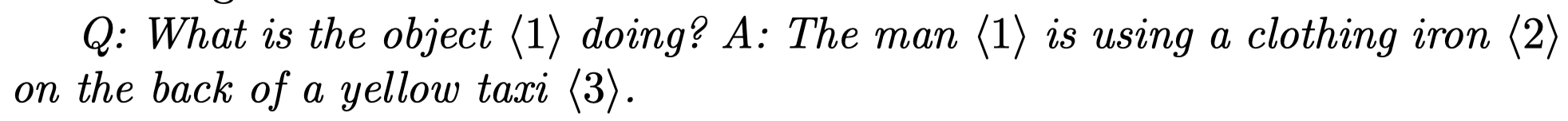
为了进行评估,作者在LLaVA Bench (COCO)的基础上,构建了同时评估grounding和chatting的benchmark,Grounding-Bench。具体构建过程参考论文。
下面是一些使用visual prompt进行输入的例子:


Groma
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models. 香港大学-字节. ECCV 2024. 代码.
We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding. Such capabilities are built upon a localized visual tokenization mechanism, where an image input is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand userspecified region inputs and ground its textual output to images. Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques. Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization. Project page: https://groma-mllm.github.io/.
Issue:之前进行grounding LMM的思路有两种:
一种思路是让LLM直接输出坐标,这种做法在处理高分辨率图片的时候计算量很大,并且LLM的解码策略实际不适合需要dense prediction的task,比如segmentation。这类思路代表如Kosmos-2, Shikra
另一种思路是用外部定位工具,会增加额外的模型复杂度。这类思路代表如LLaVA-G
Solultion:作者的思路是将grounding分为两个子任务,localization和recognization
Drawing inspiration from open-vocabulary object detection [64], we decompose the grounding task into two sub-problems: discovering the object (localization) and relating the object to texts (recognition).
localization更多需要的感知能力,而不是理解,因此可以从任务中解耦。作者的定位不是通过引入外部grounding model,而是在输入部分就把图片划分为不同的ROIs,然后直接选择对应的bounding box:

作者的方法图:
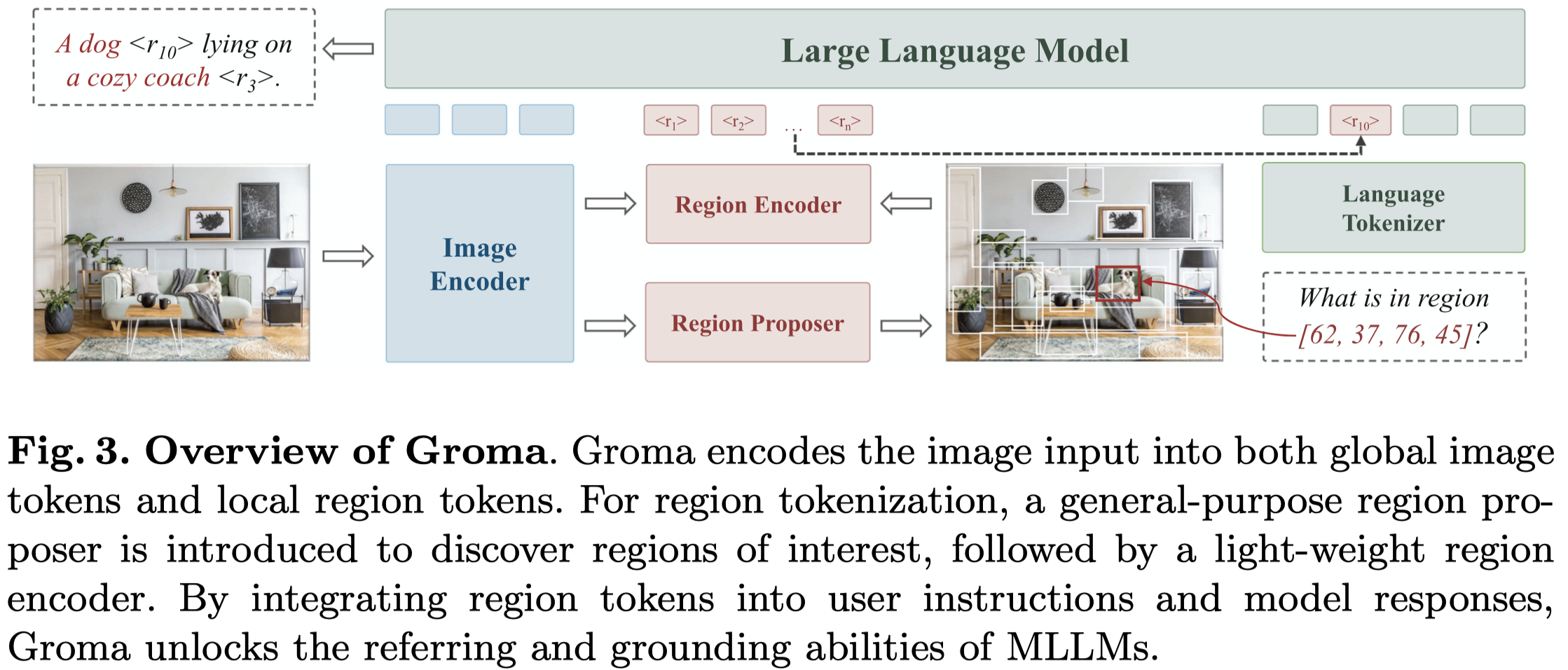
分别包括:
- Image Encoder:采用
DINOv2模型,和常用的CLIP相比,DINOv2更加擅长处理高分辨率image - Region Proposer:采用
Deformable DETR (DDETR) transformer,image encoder的最后四层特征导出作为DDETR输入,输出300个region proposal,再根据NMS和objectness scores进行过滤 - Region Encoder:采用
ROIAlign模型,使用image encoder最后3层的特征,输入RIOAlign中进行融合得到region encoder - LLM:
Vicuna 7b。
接下是如何描述输入和输出。由于region encoder得到的region embedding是连续的embedding,不能够放入到LM的codebook,在输出部分作为reference。因此作者引入一些列的proxy token指代不同bounding box:

上面的\(<r_1>\)就是proxy token。\(<image>\)和\(<region>\)是对应的image encoder和region encoder输出embedding。\(<p>\)框定grounding phrase范围,\(<roi>\)框定proxy token。
对于用户框定的region,同样可以把其作为一个bounding box。
模型训练有3阶段:
- Detection Pretraining:只涉及image encoder和region proposer,不涉及其它模块,冻结image encoder,训练region proposer
- Alignment Pretraining:对齐vision and language feature space,更新对齐投影层
- Instruction Finetuning:更新LLM参数,利用LLaVA Instruct、ShareGPT-4V数据集,以及作者构造的Groma Instruct指令数据。
由于以前的grounding数据局限在粗粒度的图像描述,导致训练出来的LMM不删除生成长文本grounded responses,因此作者利用GPT-4V,在Visual Genome数据集基础上,构建Groma Instruct指令数据。

GroundingGPT
GroundingGPT: Language Enhanced Multi-modal Grounding Model. 字节-复旦. ACL 2024. 代码.
Multi-modal large language models (MLLMs) have demonstrated remarkable performance across various tasks. However, these models often prioritize capturing global information and overlook the importance of perceiving local information. This limitation hinders their ability to effectively understand fine-grained details and handle grounding tasks that necessitate nuanced comprehension. Although some recent works have made strides in this, they have primarily focused on single-modality inputs. Therefore, we propose GroundingGPT, an end-to-end language enhanced multimodal grounding model. It is designed to perform fine-grained grounding tasks for three modalities: image, video and audio. To enhance the model’s performance, we adopt a coarse-to-fine training strategy, utilizing a threestage training approach to progressively enhance the model’s semantic awareness and finegrained understanding capabilities. Additionally, we employ a diversified stage-specific dataset construction pipeline, developing a multi-modal, multi-granularity dataset tailored for training the model in different stages. Extensive experiments conducted on multiple multimodal benchmarks demonstrate that our model achieves impressive fine-grained understanding of multi-modal inputs on grounding tasks while maintaining or improving its global comprehension capabilities. Our code, model, and dataset are available at https://github.com/lzw-lzw/GroundingGPT.
Issue:以前的关注grounding的LMM主要都是单个模态的grounding
Solution: 这篇论文是首个针对多模态grounding的工作。

作者方法很简单,每个模态有自己的encoder,然后通过adapter和LLM的特征空间对齐。
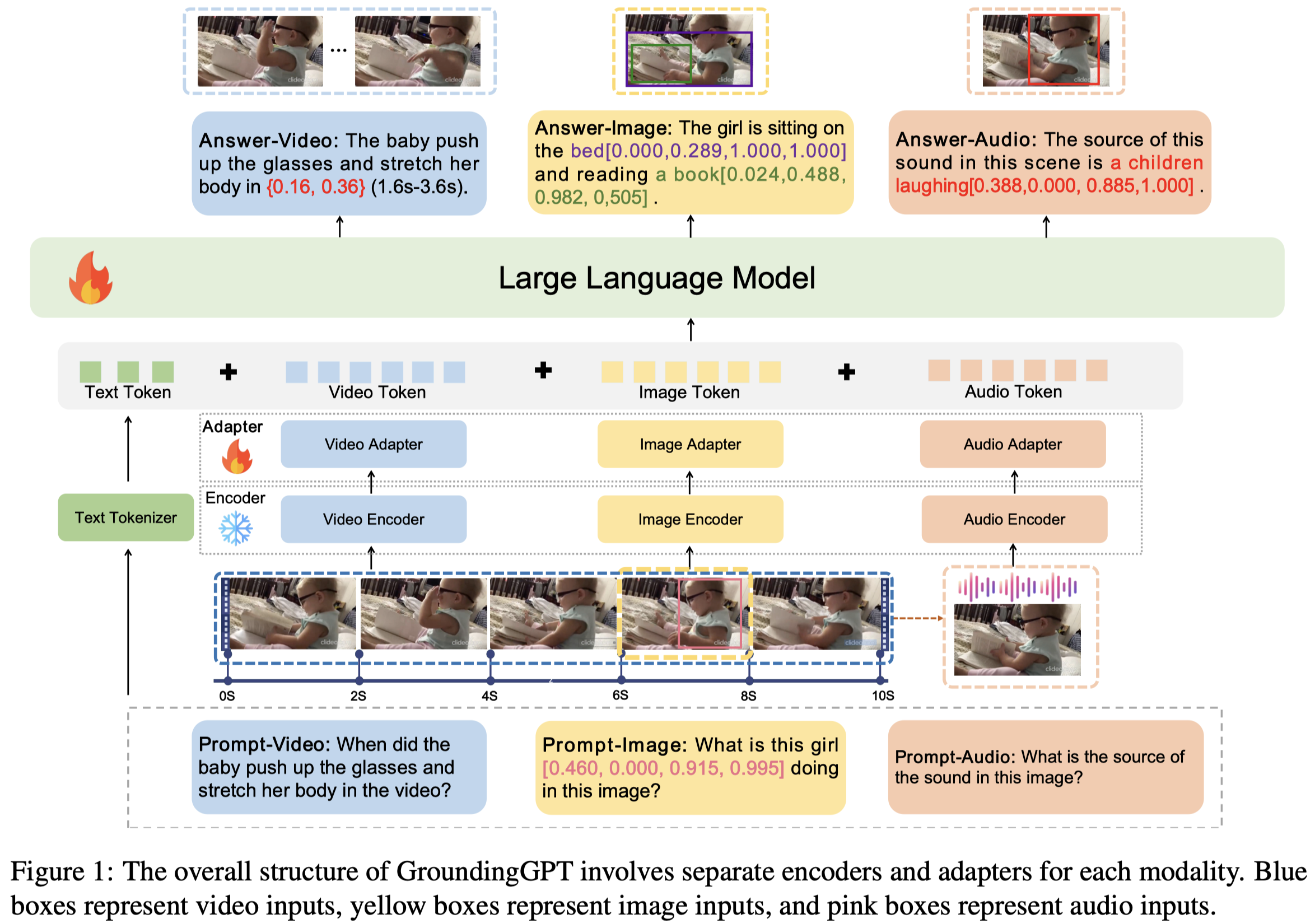
具体实现:
- LLM是
Vicuna-v1.5 - Image encoder采用
CLIP visual encoder ViT-L/14,然后利用MLP和LLM的维度对齐;对于image上的bounding box,直接使用坐标轴拼接到对应的文本描述之后; - Video encoder是对于每一帧的图片,使用image encoder分别编码,然后借助BLIP-2中的Q-Former获得固定数量的video embeddings;使用起始时间放到对应的文本描述之后;
- Audio encoder类似,采用ImageBind处理以2秒为间隔的采样,然后使用Q-Former进行聚合,获得固定数量的audio embeddings;
模型训练有3阶段:
- Multi-modal Pre-training:只利用现有数据集,训练各个模态的adapter
- Fine-grained Alignment Tuning:利用GPT-3.5转换现有数据集,加入坐标或时间戳,构造单轮问答的格式;训练LLM以及adapter
- Multi-granularity Instruction Tuning:利用已有的各个模态指令数据,以及自己构造的以现有数据为示例的新多轮对话数据集;训练LLM以及adapter;
作者实际还额外考虑了灾难性遗忘的问题,会采样前面步骤的数据进行训练:

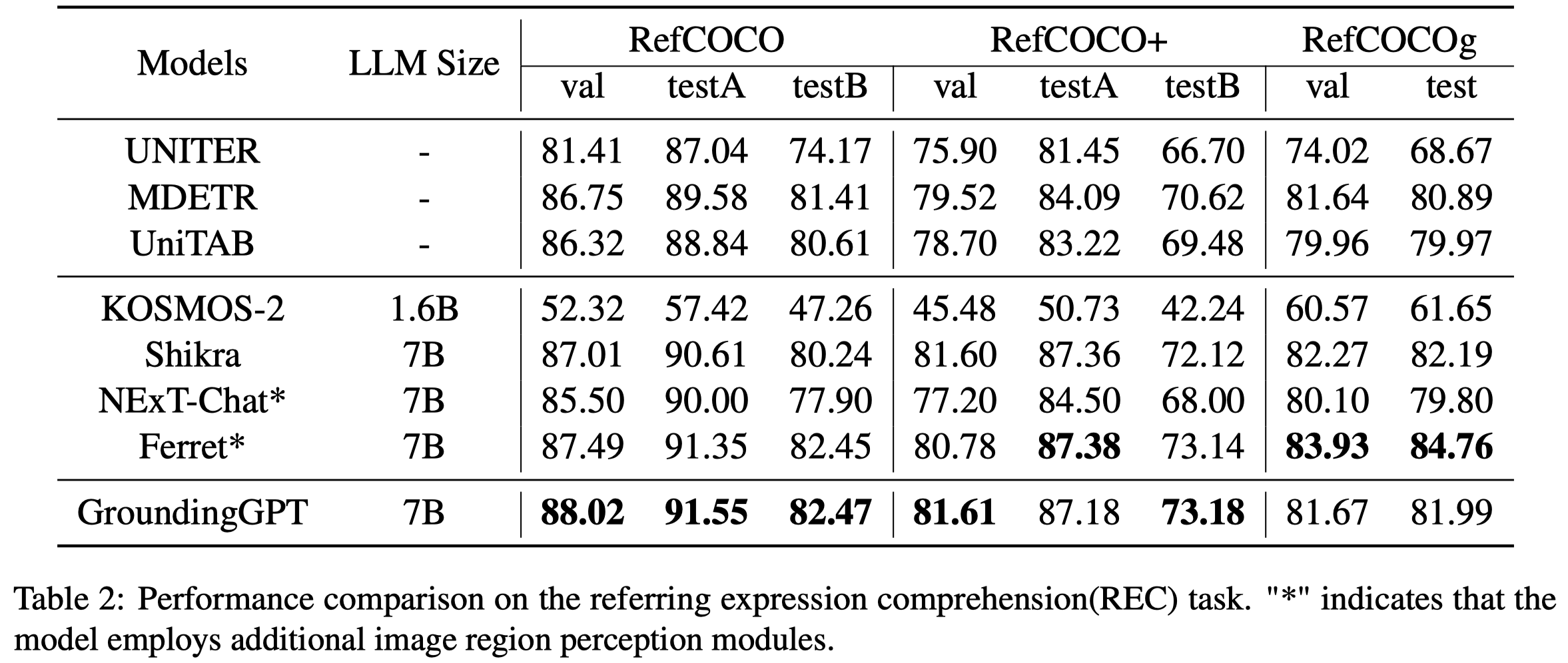
不同LMM在visual grounding任务上的效果:
\(P^2\)G
Plug-and-Play Grounding of Reasoning in Multimodal Large Language Models. 北大. arXiv 2024.06
The rise of Multimodal Large Language Models (MLLMs), renowned for their advanced instruction-following and reasoning capabilities, has significantly propelled the field of visual reasoning. However, due to limitations in their image tokenization processes, most MLLMs struggle to capture fine details of text and objects in images, especially in high-resolution samples. To overcome this limitation, we introduce \(P^2\)G, a novel framework for plug-and-play grounding in MLLMs. \(P^2\)G utilizes the tool-usage potential of MLLMs to employ expert agents for on-the-fly grounding of reasoning into critical visual and textual elements in images, thereby enabling deliberate reasoning through multimodal prompting. Additionally, we develop \(P^2\)GB, a benchmark designed to evaluate MLLMs’ proficiency in understanding inter-object relationships and textual content in challenging high-resolution images. Extensive experiments on visual reasoning tasks demonstrate the superiority of \(P^2\)G, achieving performance comparable to GPT-4V on \(P^2\)GB with a 7B backbone. Our work underscores the potential of grounding reasoning with external agents in MLLMs, presenting a promising alternative to mere model scaling.
把image转化为token存在信息丢失,特别是在处理高精度image或者text-rich image的时候。作者的思路相当于是如果评估发现缺失了信息,就重新回到input寻找缺失信息。作者训练的LMM能够学会判断当前问题是否是简单问题,如果是,就直接输出答案;如果不是,就学会调用external agent来获取缺失信息,再进行推理。
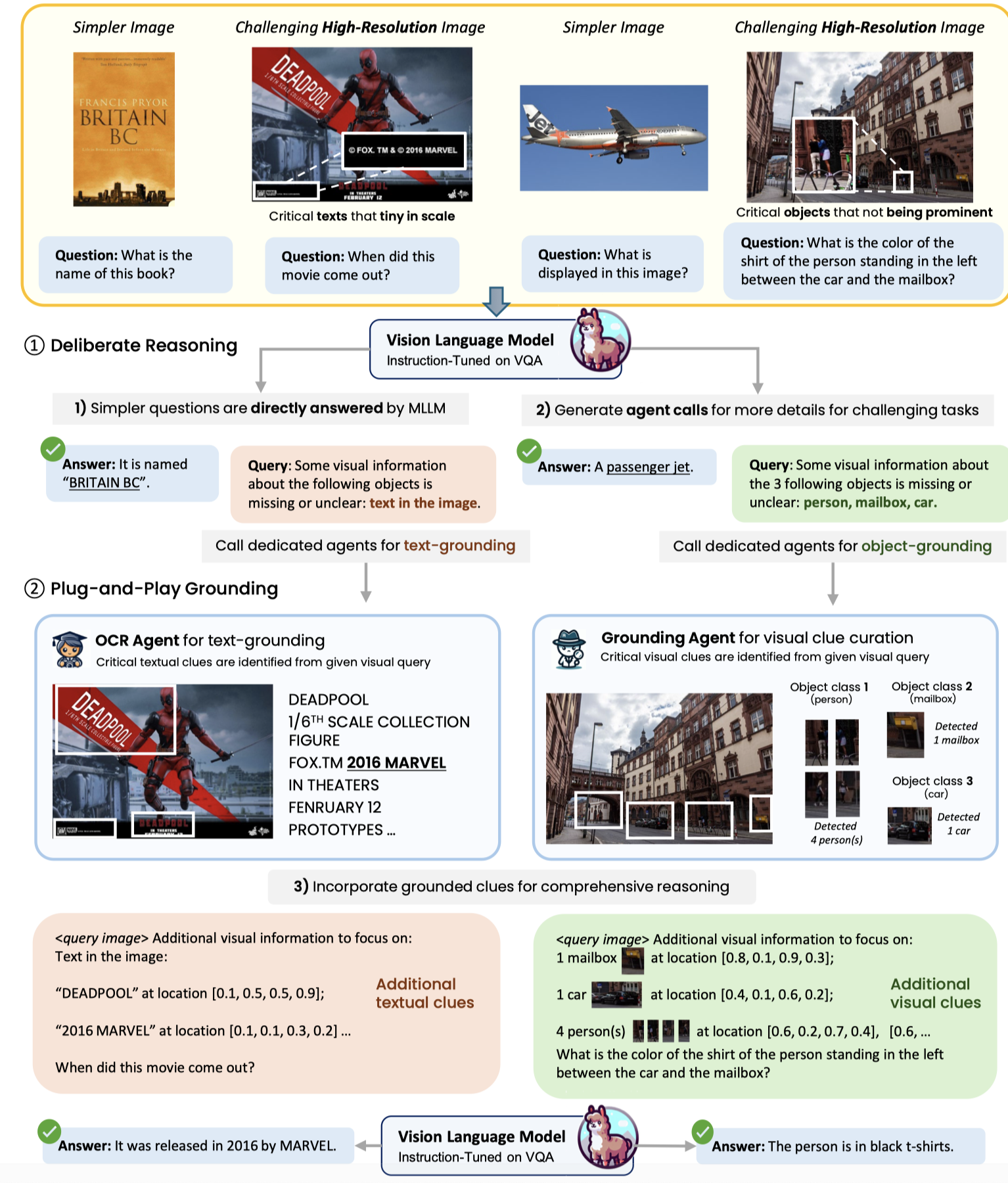
- 作者的LLM模型主要基于
Vicuna-7B-V1.3 - vision encoder是
CLIP ViT-L/14。获取的vision embedding会进行对齐,采用两种投影方式:一种是MLP,只改变维度,不改变token数量;另一种是resampler,其相当于单层跨模态注意力,改变token数量,维持context size。 - 如果只需要处理整个global image图片,只使用MLP处理vision embedding进行维度对齐;如果需要处理额外的1-4个vision objects,使用MLP处理objects,使用resampler负采样global image;如果需要处理超过4个objects,就直接使用resampler处理所有。
- Grounding Agent:Grounding DINO (Liu et al., 2023c)
- OCR Agent:PaddleOCR
作者这种方法的好处是方便集成不同的SOTA模型。
为了让LMM学会判断是否要调用外部工具,以及需要补充什么缺失信息,作者构造了专门的数据和训练阶段。
此外,作者构造了\(P^2\)GB benchmark用于评估处理高精度图片或text-rich图片的能力:

Ferret-v2
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models. Apple-CMU. COLM 2024.
While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model’s ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
Issue: 之前的LMM常常使用CLIP作为vision encoder,通常只能处理低分辨率的image,比如224x224。虽然也有部分工作尝试处理高分辨率image,但是只局限在特定领域,反而在传统的multimodal task表现下降。
Solution: 作者期望能够在保持原有multimodal task性能的同时,让LMM学会处理高分辨率和低分辨率image的grounding与referring任务。

首先,作者对于如何处理high-resolution image的当前两种策略进行了实验分析,以Ferret为基础:
- direct upsampling: In the case of “direct upsampling”, positional embedding interpolation is applied, and the CLIP backbone is adjusted to this new resolution during the fine-tuning phase. 直接把CLIP对应的预处理清晰度增大,即增大要处理的image token数量
- any resolution:For “any resolution”, we predefined a set of resolutions to support up to six grids. Given a image, we first select the optimal resolution by prioritizing fitting the original image’s aspect ratio and size as closely as possible while minimizing wasted resolution, and we resize the input image to the optimal resolution and split the image into these grids. All image patches are encoded by the CLIP encoder separately。提前定义将不同的最优分辨率放到不同的栅格grid比例中,每个grid会被CLIP单独编码。对于输入的image,先缩放到最优的分辨率,然后用CLIP处理grids。
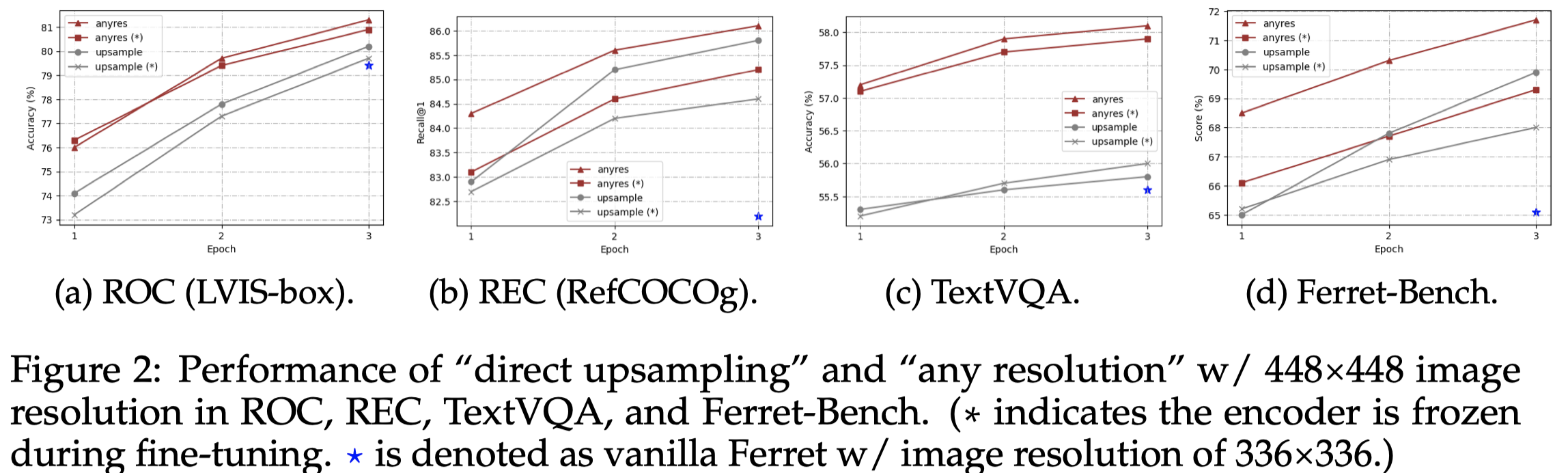
作者实验发现使用any resolution的策略更好,作者推测直接把vision encoder处理不同分辨率的image,导致其处理的token长度偏离了预训练阶段的token长度;此时微调vision encoder,由于微调data数量通常远远少于预训练data数量,反而破坏了预训练过程获得的knowledge。 而any resolution只需要vision encoder单独处理裁剪出来的local patch,更加贴近预训练过程,效果更好。
对于自己的模型设计,作者考虑到在低分辨率全局图像和高分辨率局部图像之间存在粒度的差距,有不同的特征。因此作者采用了两种编码策略。
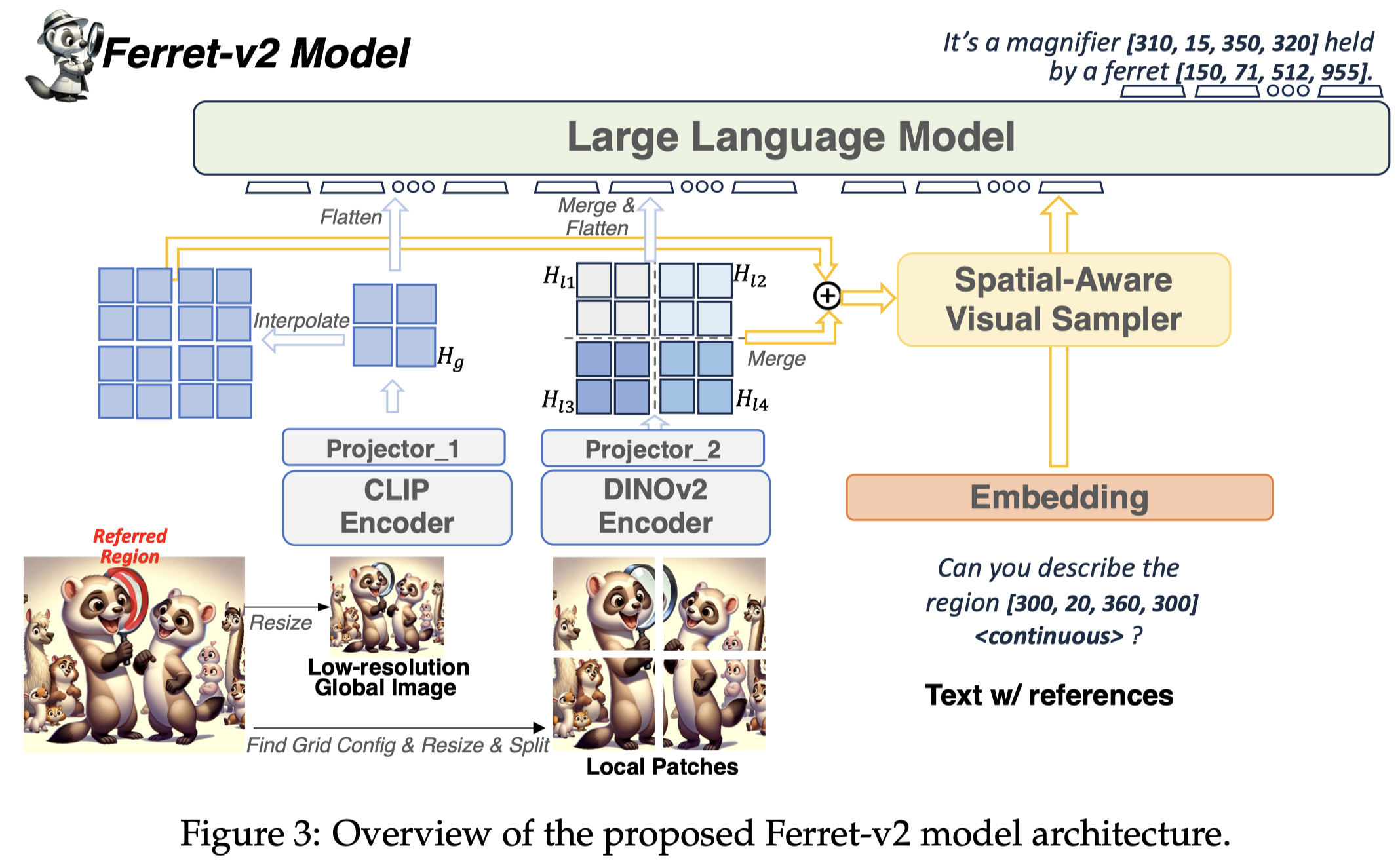
模型设计要点:
- Multi-Granularity Visual Encoding:Ferret-v2对编码region features进行了改进。使用
CLIP编码全局图像;使用DINOv2编码grid中分割的local patches;每个encoder有独立的MLP对齐层。 - Any resolution Referring:在Ferret-v1中,每个image region的表征是混合拼接的,来源包括离散的坐标token、连续的region features以及可能的region name。Ferret-v2同样采用这种混合拼接。DINOv2学习的各个区域的特征拼接到一起,而CLIP学习的全局特征feature map通过上采样扩大到和local patch feature maps一样的size,两者相加。随后利用a spatial-aware visual sampler (You et al., 2023)来学习到对应的continuous region features。
- Any resolution Grounding:直接输出数值型的坐标
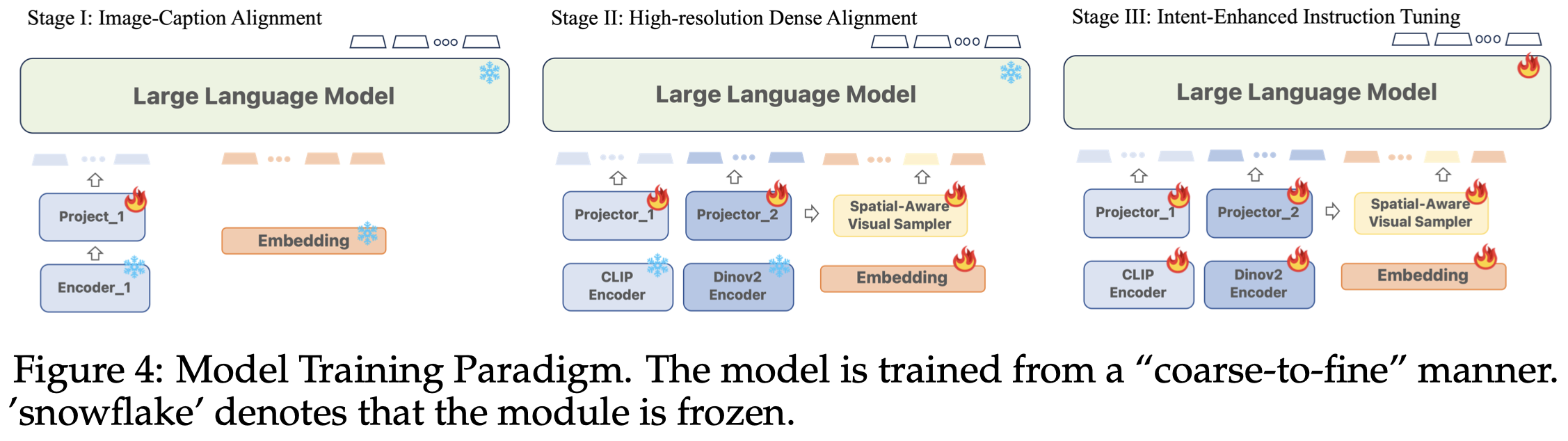
模型训练有三阶段,沿着从粗到细的思路:
- Image-Caption Alignment:image-level的图文特征对齐,利用Sharegpt4v的指令格式
- High-resolution Dense Alignment:在image-level的对齐,和最后的instruction tuning之间还存在gap,部分task instruction需要更加precise的对齐。这一阶段,作者进行两种输入和输出:
- Dense Referring: given the image, the input question refers to regions of all objects one by one, and asks about their categories, the model is required to output the predicted classes accordingly. An example is “Question: Please classify the objects in the following locations. 1: ⟨region 1⟩, 2: ⟨region 2⟩, .... Answer: Here are the categories: 1: cat, 2: dog, ...”. 给定图像上的各个regions,让LMM输出各个region的分类。
- Dense Detection: Given the image, the input question asks to localize all the objects. An example is “Question: Please localize visible objects in the image in a raster scan order. Answer: The objects are: 1: cat ⟨coordinate 1⟩, 2: dog ⟨coordinate 2⟩, ...”. 让LLM按照特定顺序,grounding图像上的各个objects。
- Intent-Enhanced Instruction Tuning: 利用各种现有指令数据进行微调
思考:一般训练阶段的思路都是从粗到细,从通用到特定,先强调对齐再强调指令跟随。需要满足的前提,或基础能力在前一步骤进行训练。
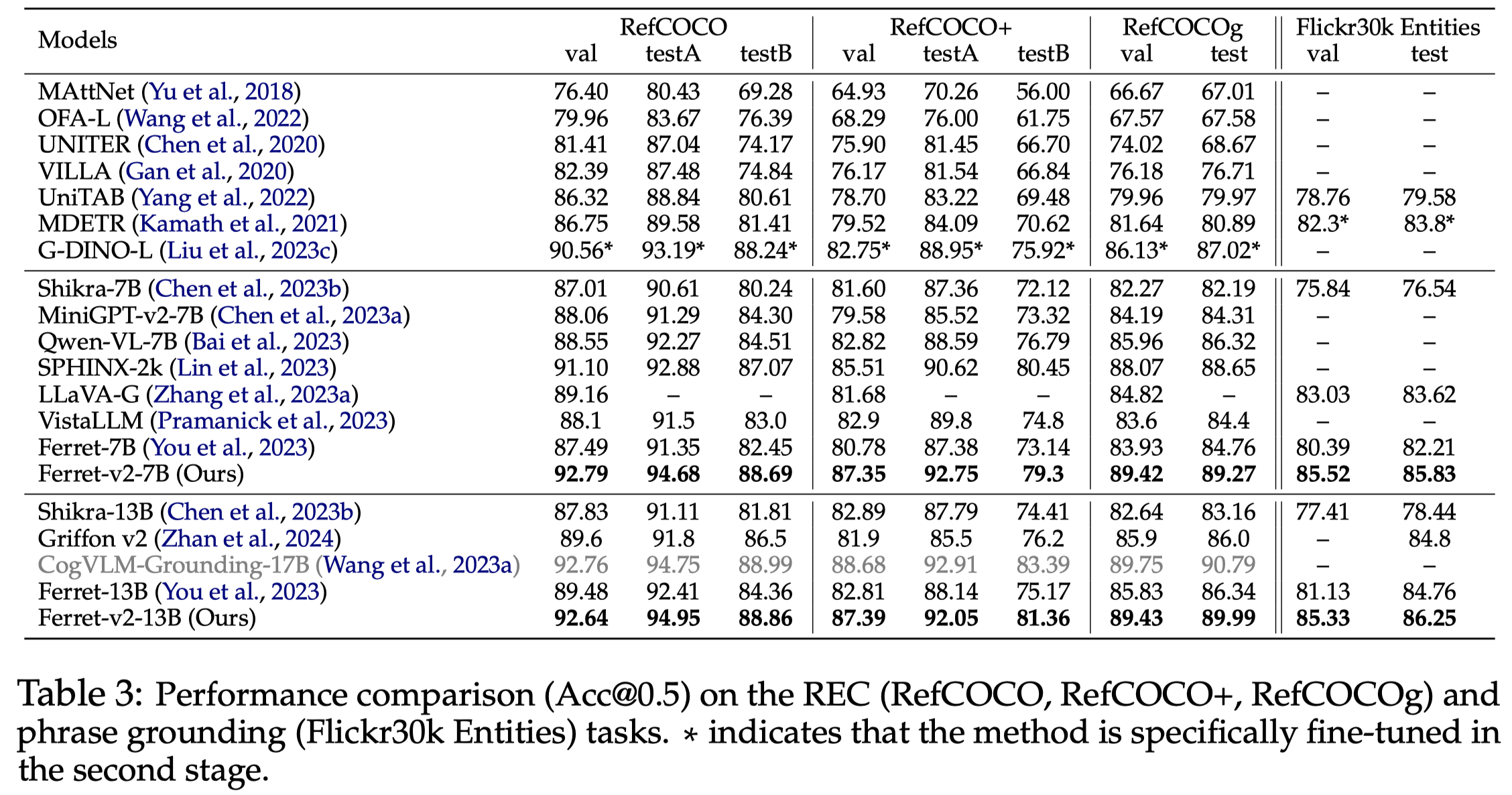
作者模型在grounding任务上的实验:
VL-SAM
Training-Free Open-Ended Object Detection and Segmentation via Attention as Prompts. 北大. NeurIPS 2024.
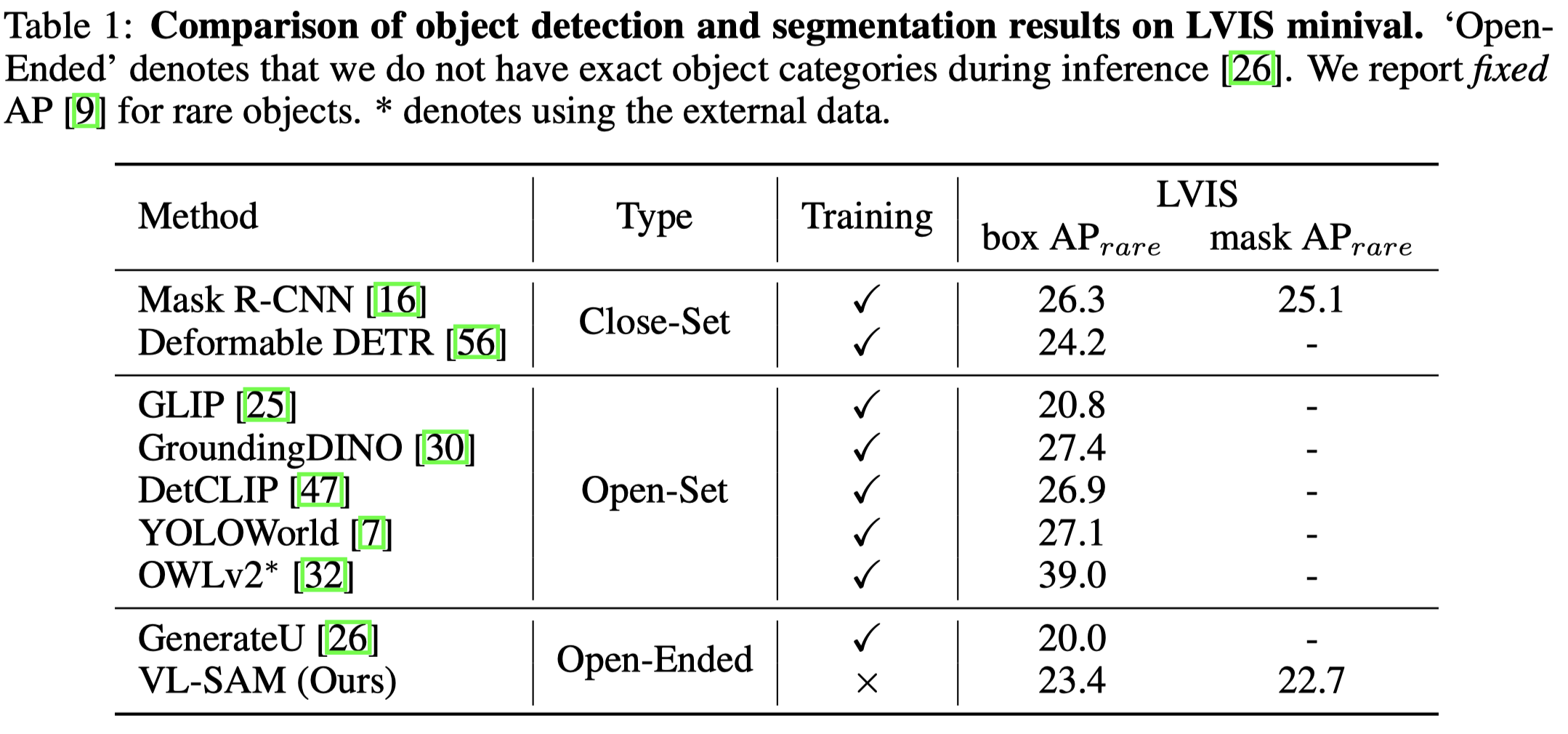
Existing perception models achieve great success by learning from large amounts of labeled data, but they still struggle with open-world scenarios. To alleviate this issue, researchers introduce open-set perception tasks to detect or segment unseen objects in the training set. However, these models require predefined object categories as inputs during inference, which are not available in real-world scenarios. Recently, researchers pose a new and more practical problem, i.e., open-ended object detection, which discovers unseen objects without any object categories as inputs. In this paper, we present VL-SAM, a training-free framework that combines the generalized object recognition model (i.e., Vision-Language Model) with the generalized object localization model (i.e., Segment-Anything Model), to address the open-ended object detection and segmentation task. Without additional training, we connect these two generalized models with attention maps as the prompts. Specifically, we design an attention map generation module by employing head aggregation and a regularized attention flow to aggregate and propagate attention maps across all heads and layers in VLM, yielding high-quality attention maps. Then, we iteratively sample positive and negative points from the attention maps with a prompt generation module and send the sampled points to SAM to segment corresponding objects. Experimental results on the long-tail instance segmentation dataset (LVIS) show that our method surpasses the previous open-ended method on the object detection task and can provide additional instance segmentation masks. Besides, VL-SAM achieves favorable performance on the corner case object detection dataset (CODA), demonstrating the effectiveness of VL-SAM in real-world applications. Moreover, VL-SAM exhibits good model generalization that can incorporate various VLMs and SAMs.
Issue: 开放域的物体识别很难,因为无法提前定义一个囊括所有类型的分类标签。比如在自动驾驶中,可能出现珍惜的东西、一个人穿着动物衣服等。
对于开放域的物体识别,VLM能够识别很稀有的objects,但是它localization的精度弱于传统的方法。另一方面,分割模型SAM(segment-anything model)能够找到不同领域的图像区域分割,但是它无法识别对应的objects。
Solution: 作者的方案就是联合VLM和SAM的通用能力,无需训练的找到objects并且定位。
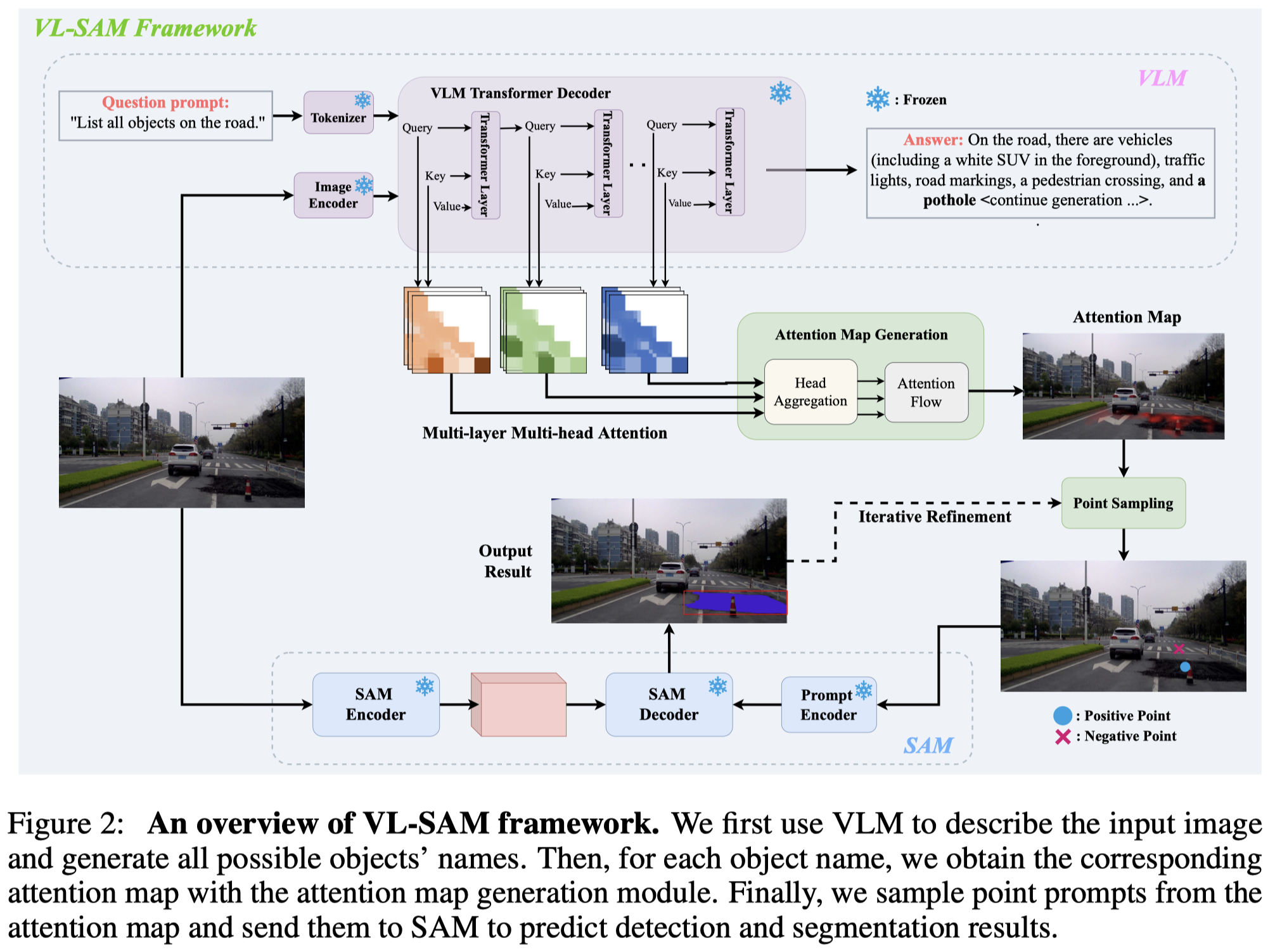
作者的方法是利用现有的MLLM CogVLM-17B,输入prompt让其列出所有的image上的objects。prompts实际上不是一种,作者生成多种不同的prompts,然后把每个prompt对应的风格结果组合。
对于输入图像,为了获得更多细节的objects,作者把原始image分割为4个区域,然后让VLM分别处理。将4个sub-image和整个image的分割结果组合。
生成的结果,作者使用Tag2Text方法解析句子中的objects。然后对于每个object,导出MLLM中的所有层所有注意力头\(S\):
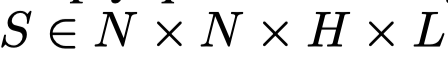
其中,\(N\)是输入的序列长度,\(H\)是注意力头数量,\(L\)是层数。
之后,作者尝试计算各个层中,不同注意力头的权重,采用mean-max操作。先找到一个head中,一个query的最大weight,然后平均,得到这个head的权重。
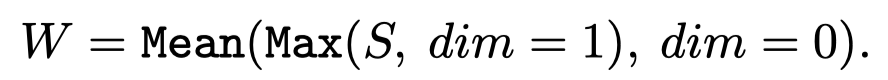
\(W\in 1\times 1\times H\times L\)。把head权重和原来的注意力map \(S\)相乘:
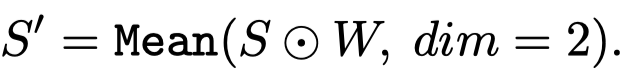
随后,从底向上,相乘attention map,这也是attention rollout method [1]的思路:
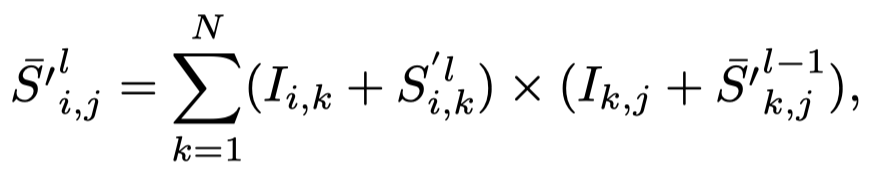
在attention rollout过程中,由于decoder的注意力图是causal mask的,因此,出现在前面的embedding会逐渐的累积权重,而导致最后计算出来的注意力图会倾向于选择左上角的图像区域。下面是作者在openreview上的解释:


为了解决这一点,作者采用了一个简单的正则,假设某一列的非mask的长度是\(L_0\),则这一列的所有权重和正则项\(1 − (L_0−1)/L\)相乘。
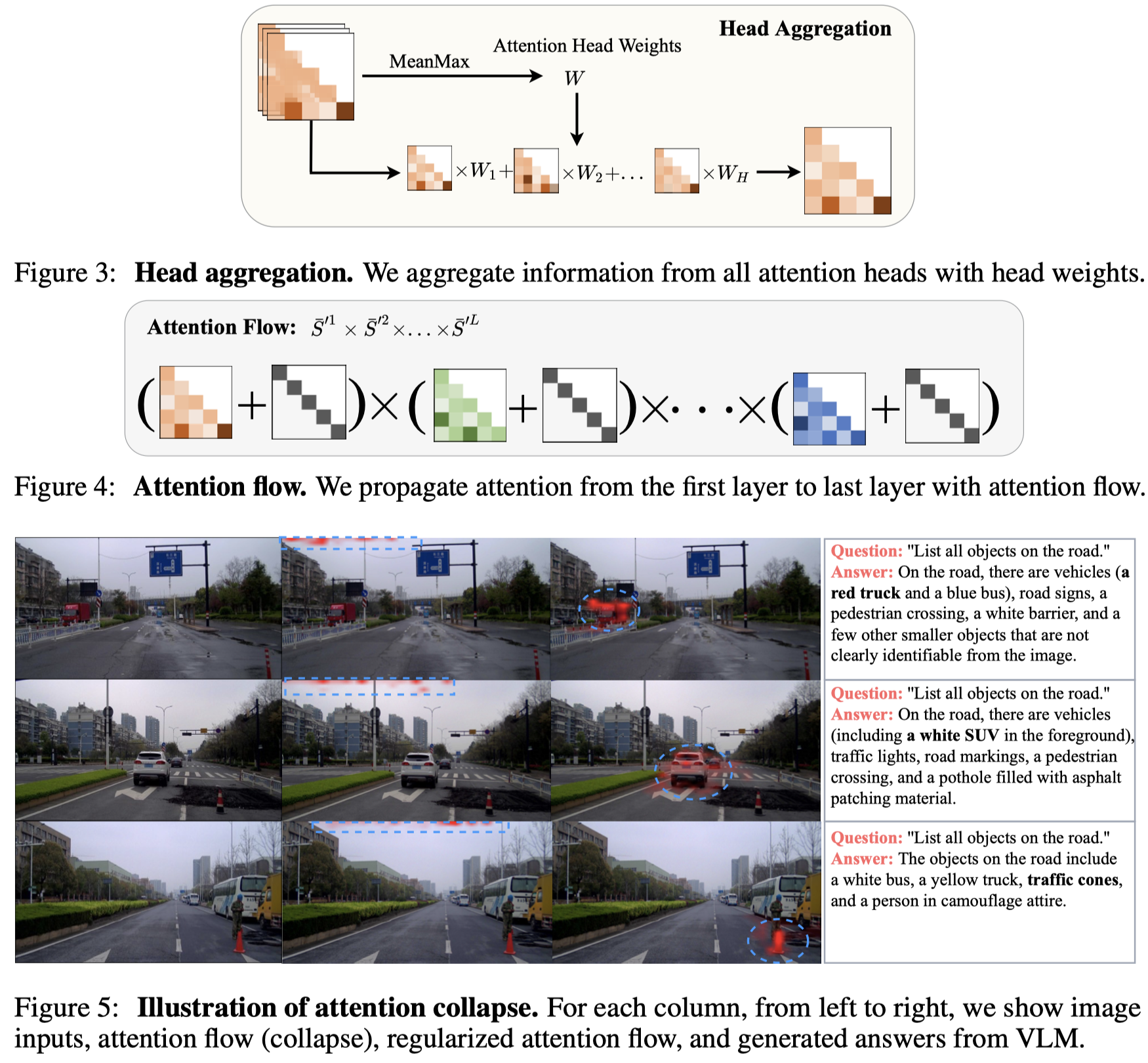
在获得了attention map,作者使用一个阈值来过滤掉weak activated areas,寻找到the maximum connectivity area as the positive area [5]。把剩下的区域作为negative data。从positive area和negative中分别采用一个点来作为输入给SAM的prompt。
之后,作者采用了迭代优化的策略来不断调整SAM的分割结果。具体参考论文。
llava-logit lens
Towards Interpreting Visual Information Processing in Vision-Language Models. arXiv 2024. 南洋理工. 代码.
Vision-Language Models (VLMs) are powerful tools for processing and understanding text and images. We study the processing of visual tokens in the language model component of LLaVA, a prominent VLM. Our approach focuses on analyzing the localization of object information, the evolution of visual token representations across layers, and the mechanism of integrating visual information for predictions. Through ablation studies, we demonstrated that object identification accuracy drops by over 70% when object-specific tokens are removed. We observed that visual token representations become increasingly interpretable in the vocabulary space across layers, suggesting an alignment with textual tokens corresponding to image content. Finally, we found that the model extracts object information from these refined representations at the last token position for prediction, mirroring the process in text-only language models for factual association tasks. These findings provide crucial insights into how VLMs process and integrate visual information, bridging the gap between our understanding of language and vision models, and paving the way for more interpretable and controllable multimodal systems.
Issue: 纯语言模型的理解已经取得很大进展,但是对于VLM的理解还有很大GAP。
- how visual information is encoded in these representations
- whether and how much object-specific details are localized or dispersed across the entire representation
作者以LLaVA 1.5 7B为基础,进行研究。
Solution:作者先研究哪些图像区域是重要的,通过object detection进行预测
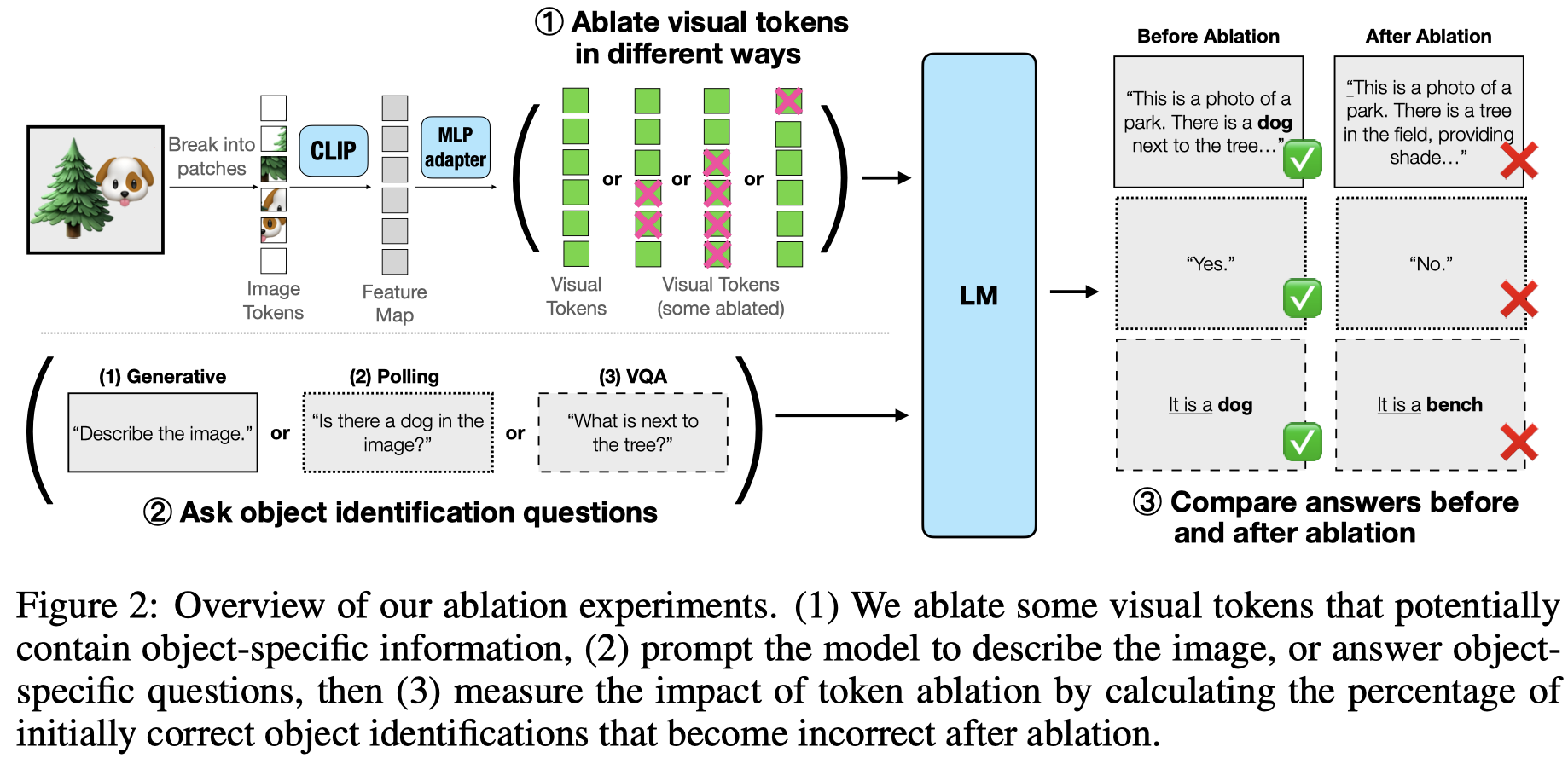
通过消融下面四种图像patch(经过image encoder adapter之后),被选中的patch使用在ImageNet validation set的50,000 images所有visual tokens的平均值替换。

结果发现,object对应区域的visual tokens包含了最多的信息,引起了最多的性能下降。换句话说,object的信息并没有在经过image encoder之后,被扩散到整个image上。
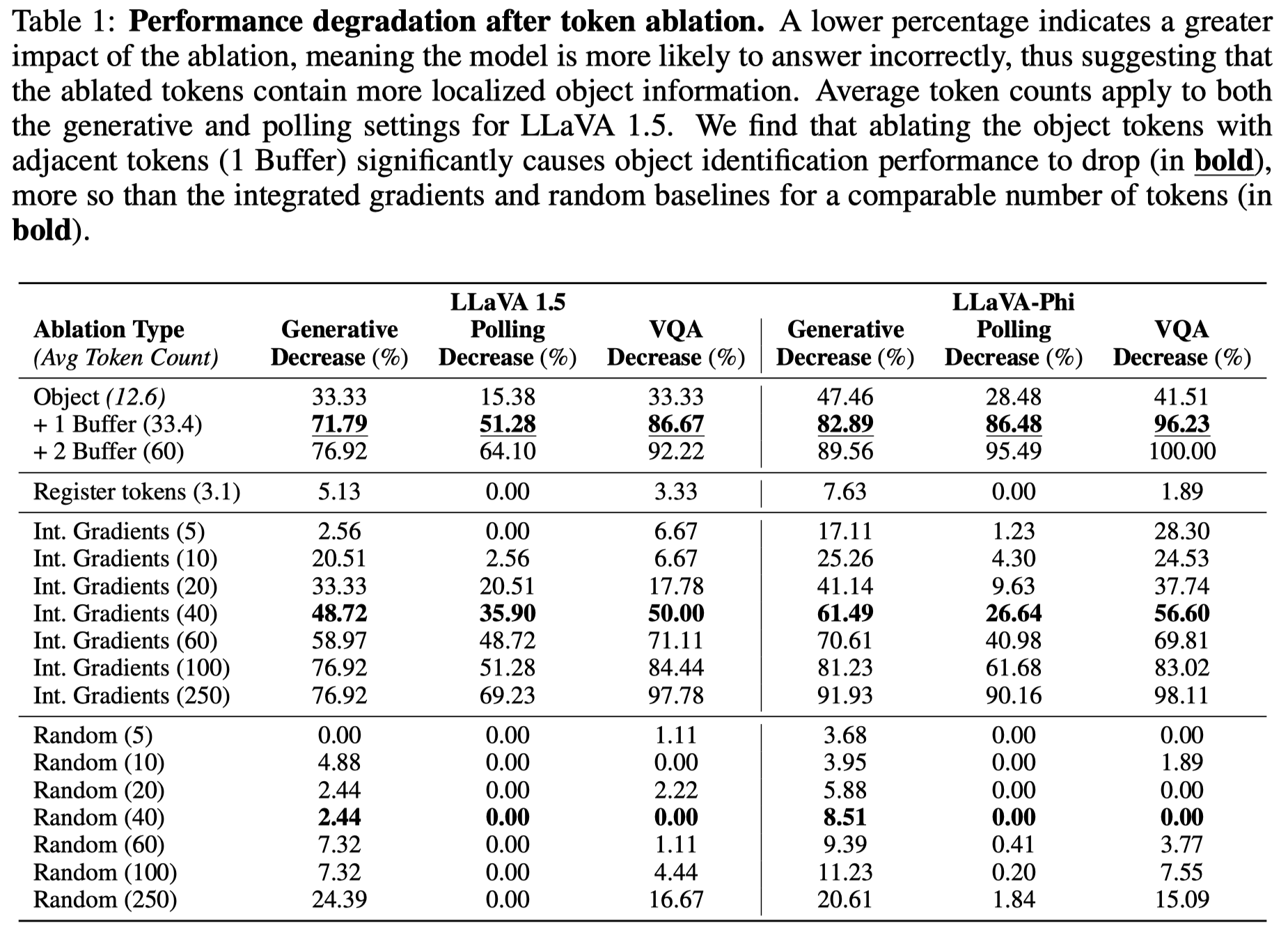
之后,为了分析visual tokens是如何在经过不同LLM层之后被学习的,作者使用了logit lens方法,也就是让每一层visual tokens与unembedding matrix计算相似度,得到最大的logit选择为对应的词。
作者结果发现,LLM在中高层的时候,LLM逐渐能够将visual tokens对齐到和所在的object相关的词上:

不过也存在特殊的情况是某些背景所在的tokens,可能会反而捕获global image相关的信息。比如说上面的(d)图中,背景patch对应到了一些苹果的数量。
最后,作者尝试分析了attention flow探究LLM是直接从相关的visual tokens中找到对应的信息,还是会在生成最终输出token之前,先聚合visual tokens。
利用attention knockout方法,在不同层之间mask从特定token到目标token对应的attention。
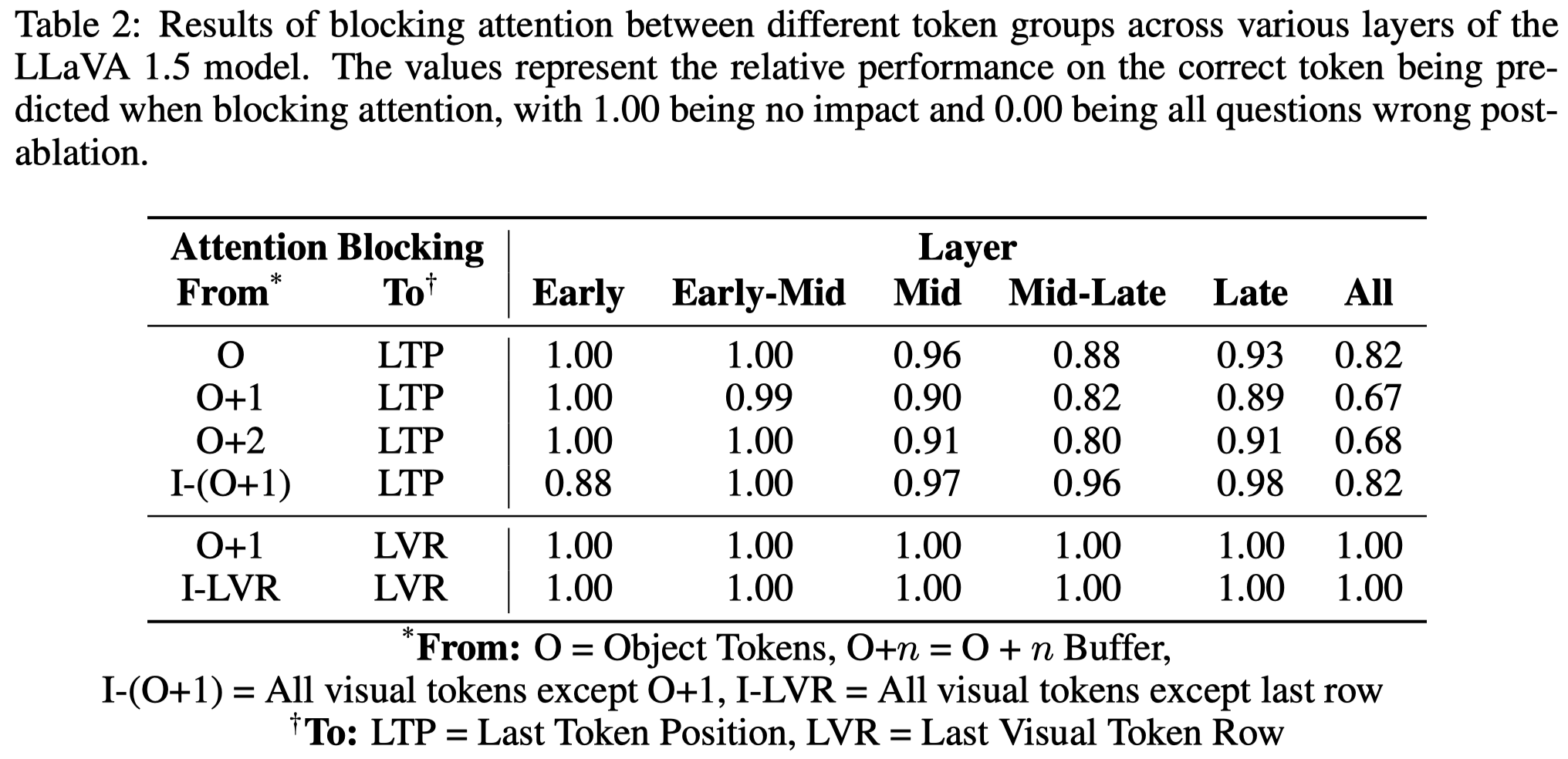
结果发现,mask掉object相关的visual tokens到最终final token引起了最多的性能下降,这表明了LLM可能是直接在高层中直接获取的object信息。相反,如果是mask visual tokens到最后一层token的attention,性能几乎没有下降。这表明,至少对于作者探究的object detection任务,LLM没有尝试在最后一层visual tokens中进行信息总结。
(This contrasts with findings by Basu et al. (2024), who suggested that the model might summarize image information in the last row of visual tokens before using it.)