LLM-PEFT
LLM的PEFT方法
参数高效微调PEFT(Parameter-Efficient Fine Tuning)方法调研。
Prefix-Tuning
Prefix-Tuning: Optimizing Continuous Prompts for Generation
ACL 2021,斯坦福。
Fine-tuning is the de facto way of leveraging large pretrained language models for downstream tasks. However, fine-tuning modifies all the language model parameters and therefore necessitates storing a full copy for each task. In this paper, we propose prefix-tuning, a lightweight alternative to fine-tuning for natural language generation tasks, which keeps language model parameters frozen and instead optimizes a sequence of continuous task-specific vectors, which we call the prefix. Prefix-tuning draws inspiration from prompting for language models, allowing subsequent tokens to attend to this prefix as if it were “virtual tokens”. We apply prefix-tuning to GPT-2 for table-to-text generation and to BART for summarization. We show that by modifying only 0.1% of the parameters, prefix-tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low-data settings, and extrapolates better to examples with topics that are unseen during training.
作者提出了一种区别于所有模型参数更新方法的新微调方法,prefix-tuning:
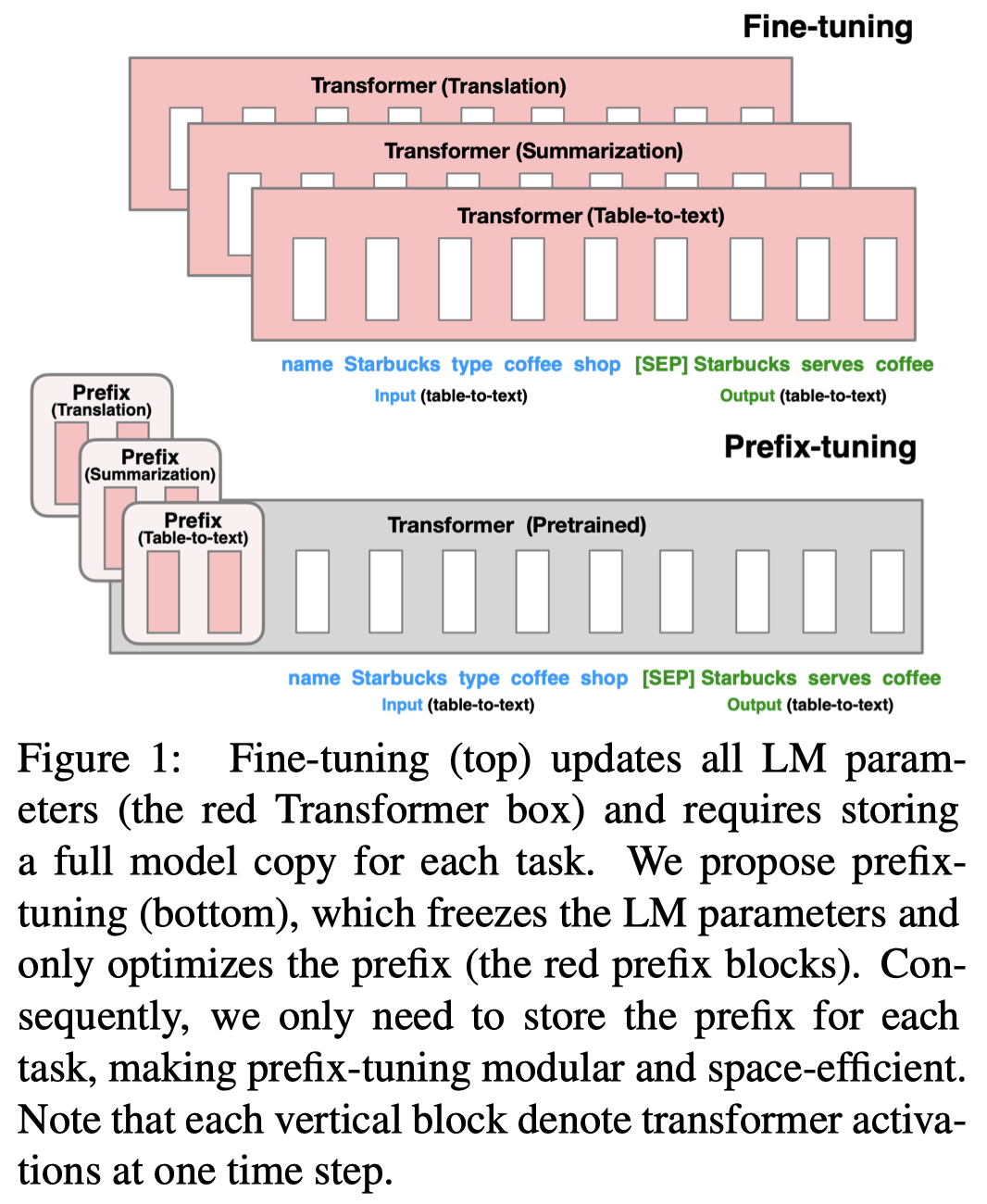
简单的说就是在LLM模型的每一层输入最前面,加入一个embedding序列,作为prefix。这样每一层模型的输出(encoder/decoder)都会被prefix影响:
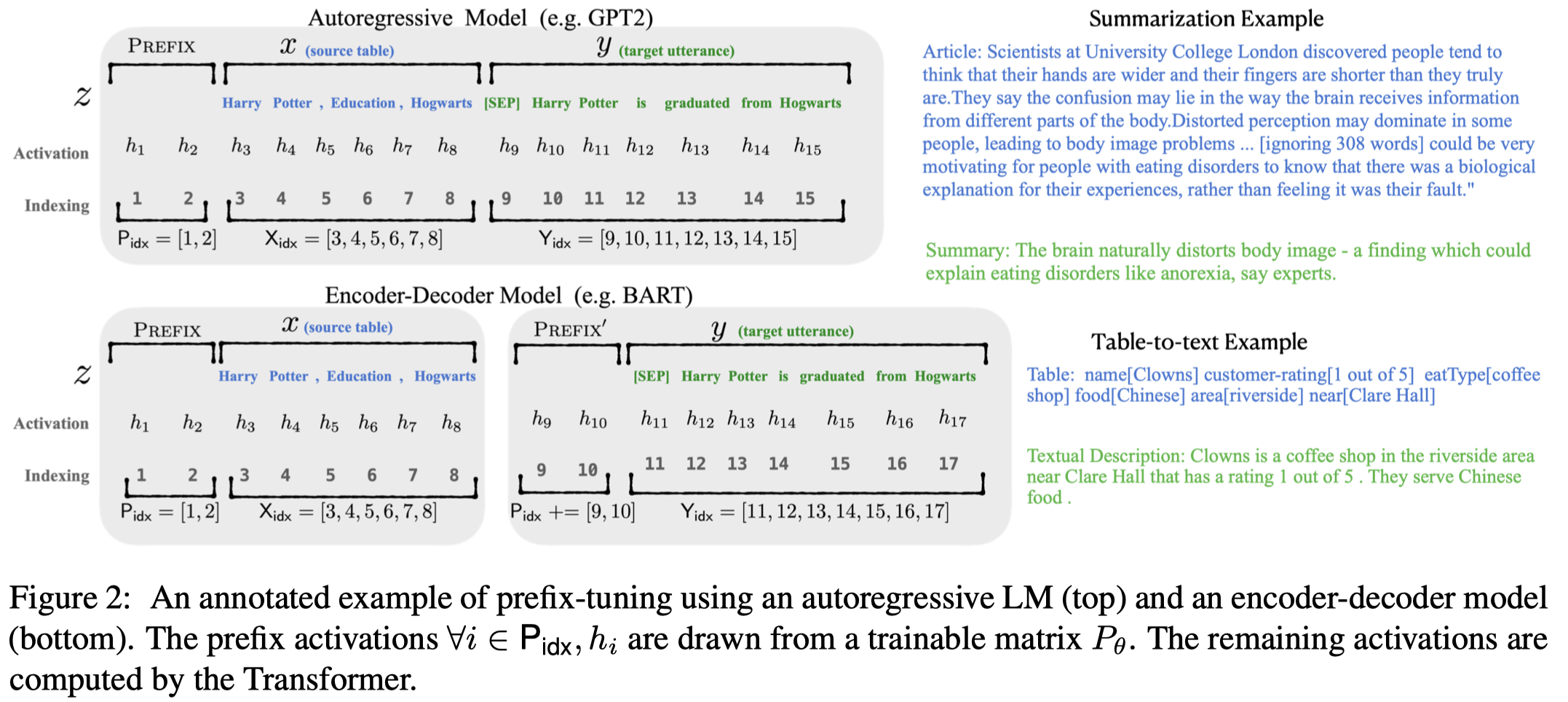
需要注意的是,作者发现如果只是单纯的给每一层输入加入独立的embedding,会导致模型训练不稳定,效果下降。因此作者是使用一个MLP来生成要输入到每一层左侧的prefix embedding。在inference阶段,就可以丢掉这个prompt而直接使用最终训练好的prefix embedding即可。
作者基于GPT-2进行了相关的实验。
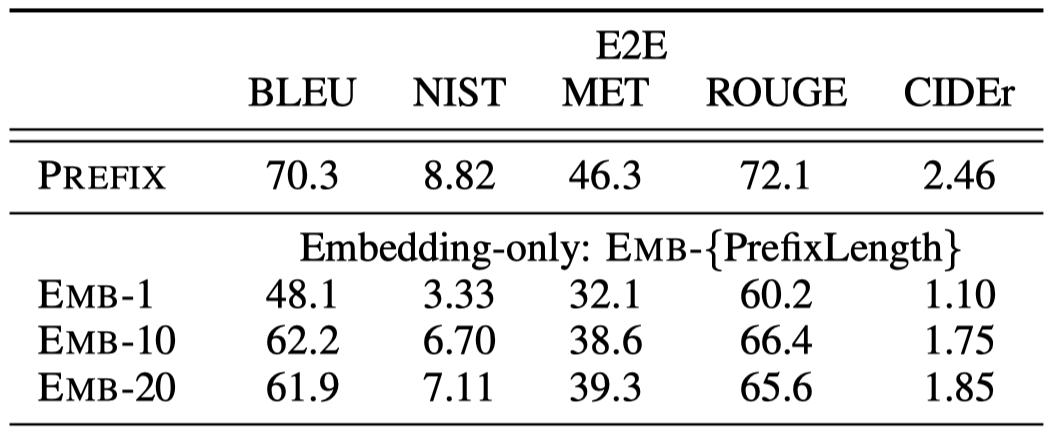
一个发现是随着prefix length的增加,模型性能先增加后减低:
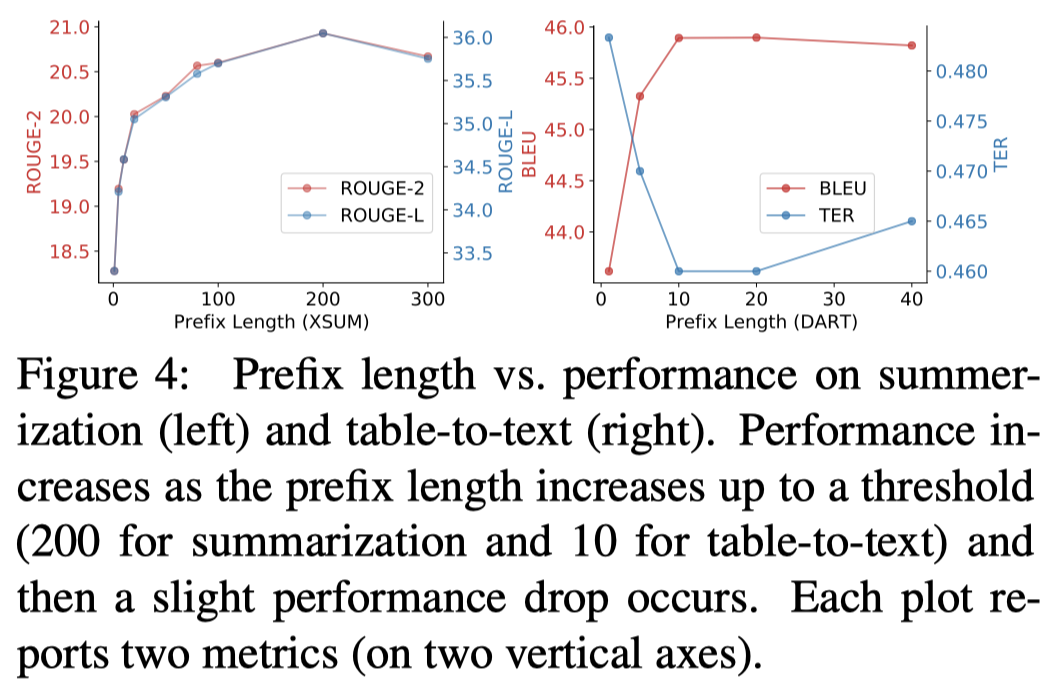
作者还进行了一个只在embedding层加入prefix的结果,发现效果会下降很多(这一点可能是因为GPT-2的model size还不够大,后面的prompt-tuning方法证明越大的模型需要微调的参数量越少):
Prompt-tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
EMNLP 2021,Google brain,代码。
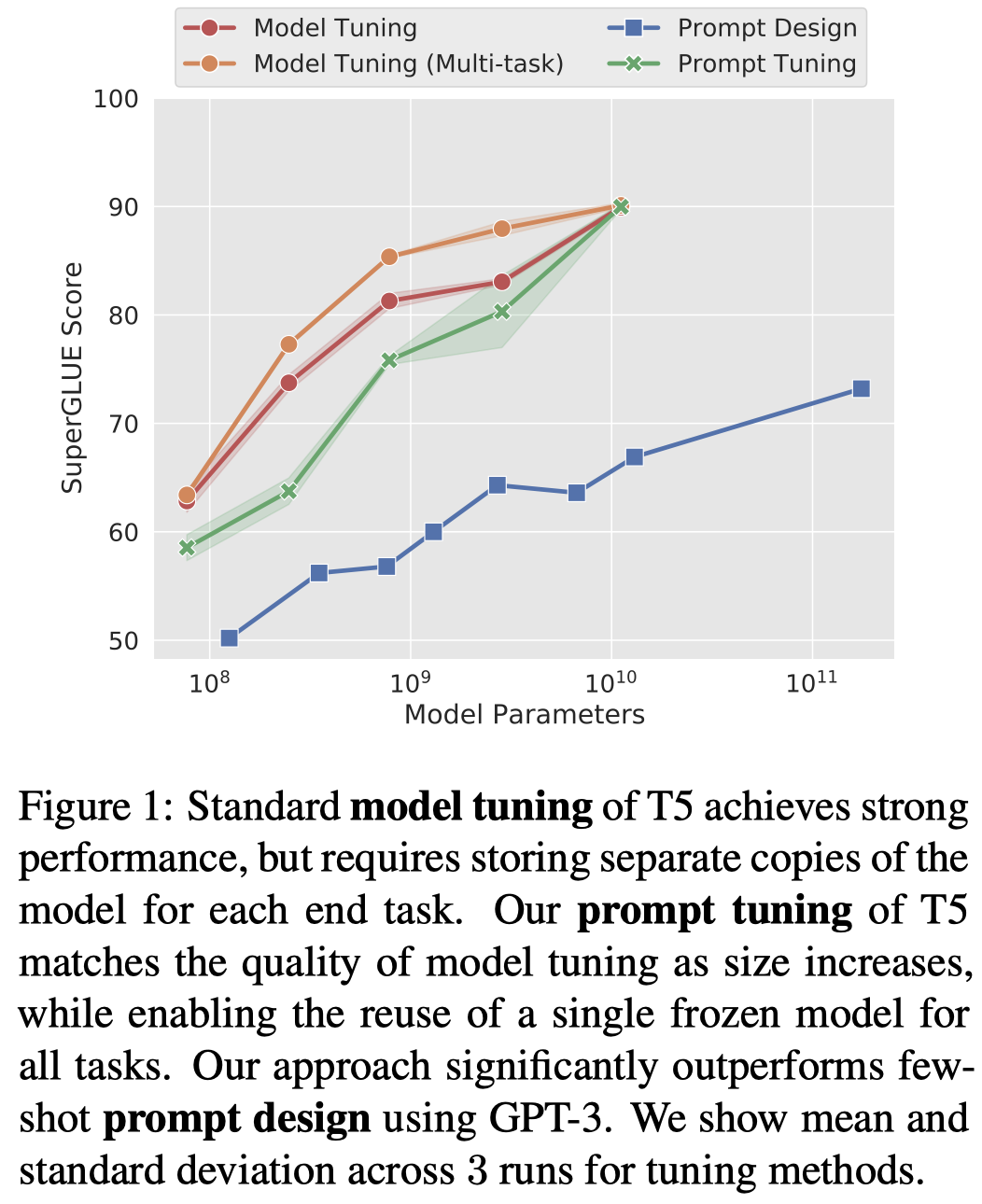
In this work, we explore “prompt tuning,” a simple yet effective mechanism for learning “soft prompts” to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signals from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3’s few-shot learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method “closes the gap” and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant because large models are costly to share and serve and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed “prefix tuning” of Li and Liang (2021) and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer and enables efficient “prompt ensembling.” We release code and model checkpoints to reproduce our experiments.
更近一步的简化,只是在embedding输入层最左边加入soft prompt作为task prompts。作者发现,这种方法随着model size增加,效果逐渐能够比拟fine-tuning的效果:
这种soft prompt比起text prompt/hard prompt来说,好处就是它可以看做是一种信息压缩。如果用text prompt要达到比较好的效果,依赖于输入的长度和是否准确的描述了足够的context信息。实际上所有的text token也最终会被fixed LLM转化为fixed embedding。prompt tuning只不过让某些tokens能够被更新/或者是理解为创造代表新语义的token embedding。
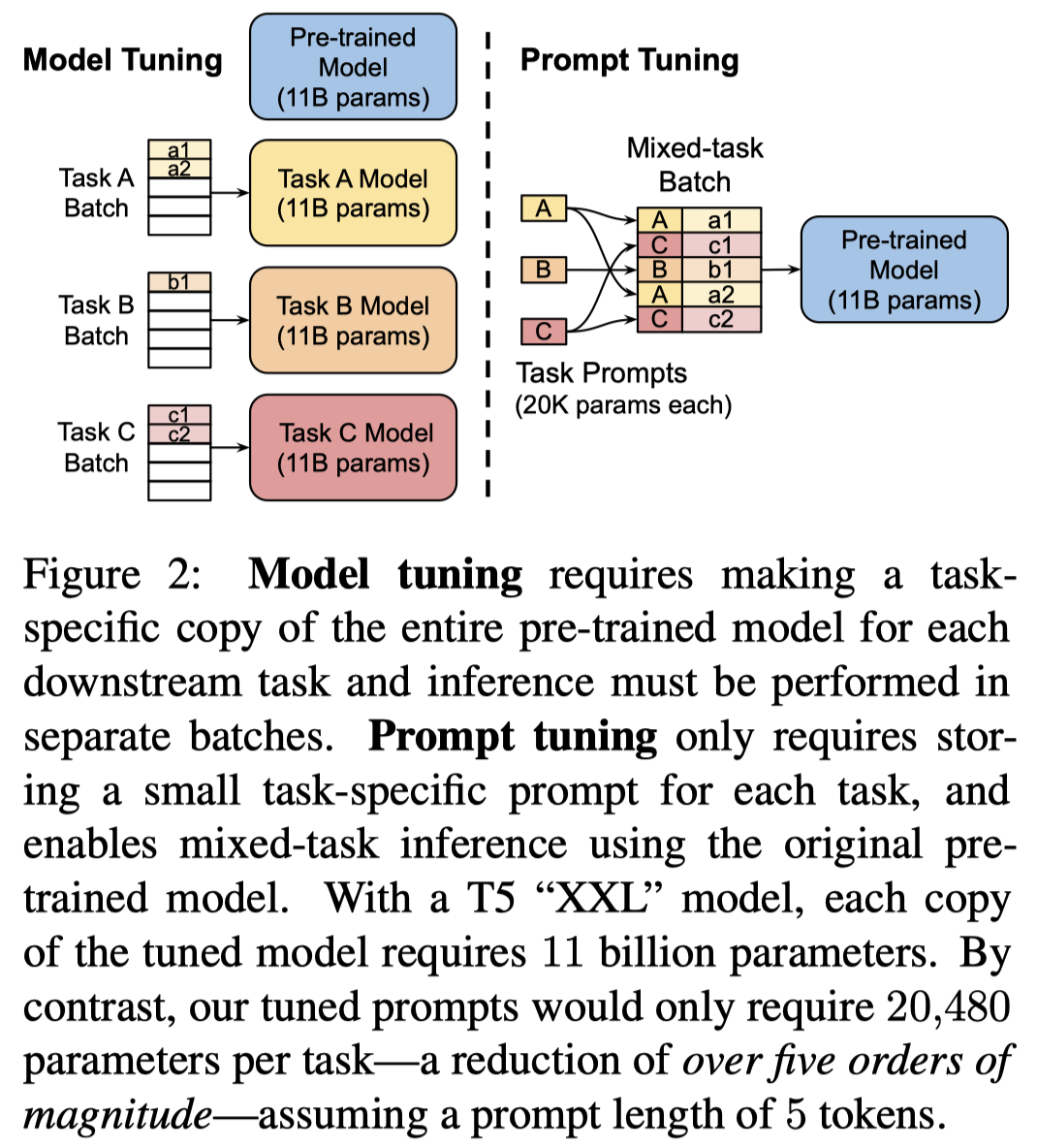
方法很简单,更重要的是几个实验。
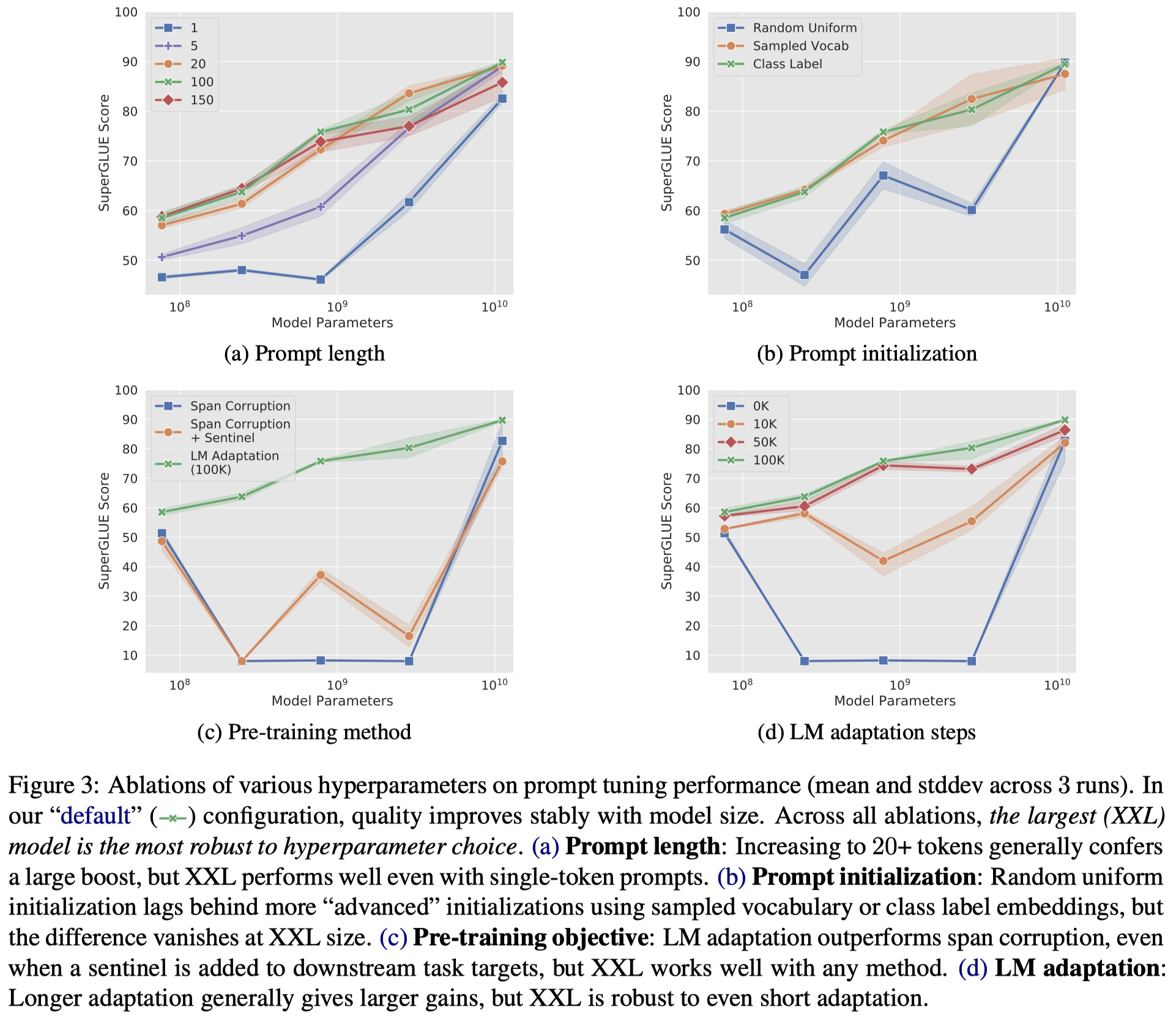
从这个图(a)能够看出很重要的一点信息,越大的LLM,对于prompt length要求越低,可能LLM越能够快速的学习好condition signal,也只需要微调更少的参数即可。
作者实验了三种不同的初始化prompt的方法:
- random initialization: we sample uniformly from the range [−0.5, 0.5]
- initializing from sampled vocabulary: we restrict to the 5,000 most “common” tokens in T5’s SentencePiece vocabulary (Kudo and Richardson, 2018), which is ordered by likelihood in the pre-training corpus.
- “class label” initialization: we take the embeddings for the string representations of each class in the downstream task and use them to initialize one of the tokens in the prompt.
实验结果如上图的(b),可以看到使用“class label” initialization在model size较小的情况下效果最好,但是当model size达到一定程度的时候,不同的初始化方法没有区别了。
这种prompt-tuning方法和model-tuning的方式比起来,另一个好处可能是保持了模型本身学习到的知识和能力,不会由于fine-tuning降低泛化能力,从而带来更好的领域迁移能力。(This reduces the model’s ability to overfit to a dataset by memorizing specific lexical cues and spurious correlations.)下面是作者在一个in-domain数据集上训练,在out-domain的数据集上直接测试的结果,可以看到这种方法具有更好的领域迁移能力:
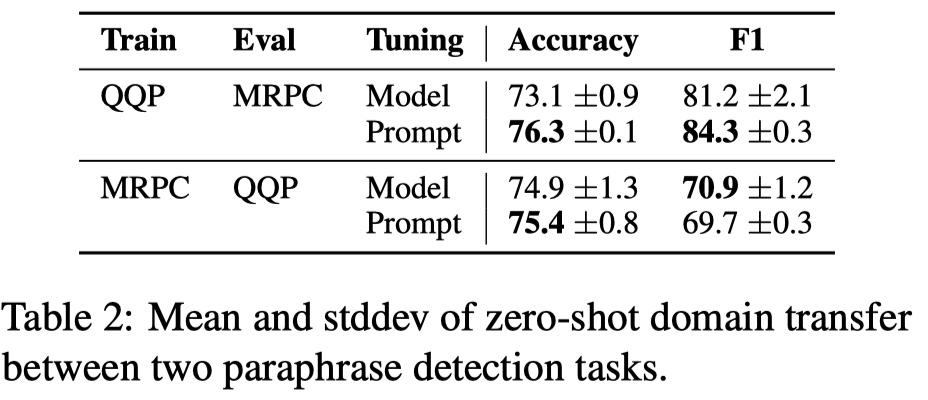
由于LLM的规模,要集成多个LLM是很难的。但是作者还把不同的prefix prompt token看做是训练了不同的model。使用由多个tokens的prompt-tuning方法,看做是一种prompt ensembling方法。作者直接拿单个的prefix token出来作为prefix,基于fixed T5,使用majority voting方法集成结果,发现效果都提升了:
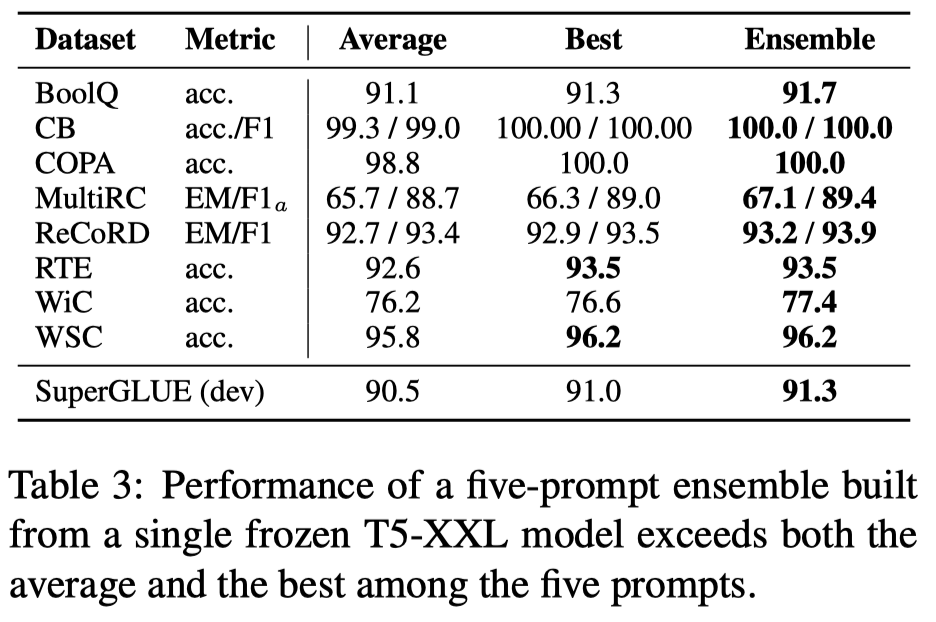
作者最后是尝试解释了一下学习到的prompt embedding的含义,基于余弦相似度计算和其它word embedding之间的相似性,使用最近邻算法聚合邻居,有如下发现:
- 发现使用word-like的prompt初始化,让最相似的邻居聚类也都是相似语义的。
- 发现label word也会在最近邻中出现,但是如果是使用随机初始化,同一个label word可能会在多个prompt embedding的最近邻里出现。如果是使用class labels去初始化,会让label word只出现在一个对应的prompt embedding的最近邻里。
- 发现label的最近邻居中确实会出现和domain相关的一些关键词,比如science,technology等。说明prompt-tuning这种方法确实可能domain specific的信息。
P-tuning
GPT Understands, Too
arXiv 2021.03,清华大学,代码。
While GPTs with traditional fine-tuning fail to achieve strong results on natural language understanding (NLU), we show that GPTs can be better than or comparable to similar-sized BERTs on NLU tasks with a novel method P-tuning which employs trainable continuous prompt embeddings. On the knowledge probing (LAMA) benchmark, the best GPT recovers 64% (P@1) of world knowledge without any additional text provided during test time, which substantially improves the previous best by 20+ percentage points. On the SuperGlue benchmark, GPTs achieve comparable and sometimes better performance to similar-sized BERTs in supervised learning. Importantly, we find that P-tuning also improves BERTs’ performance in both few-shot and supervised settings while largely reducing the need for prompt engineering. Consequently, P-tuning outperforms the state-of-the-art approaches on the few-shot SuperGlue benchmark.
作者提出了一种直接在输入层生成continuous prompt embeddings作为输入的微调方法。作者这里的continuous prompt或者叫soft prompt是由一个外部可训练的模型(LSTM+MLP)生成的。对于原来的输入离散的prompt,只保留在prompt模板中关键的context token和mask token。其它的token都是重新学习的:
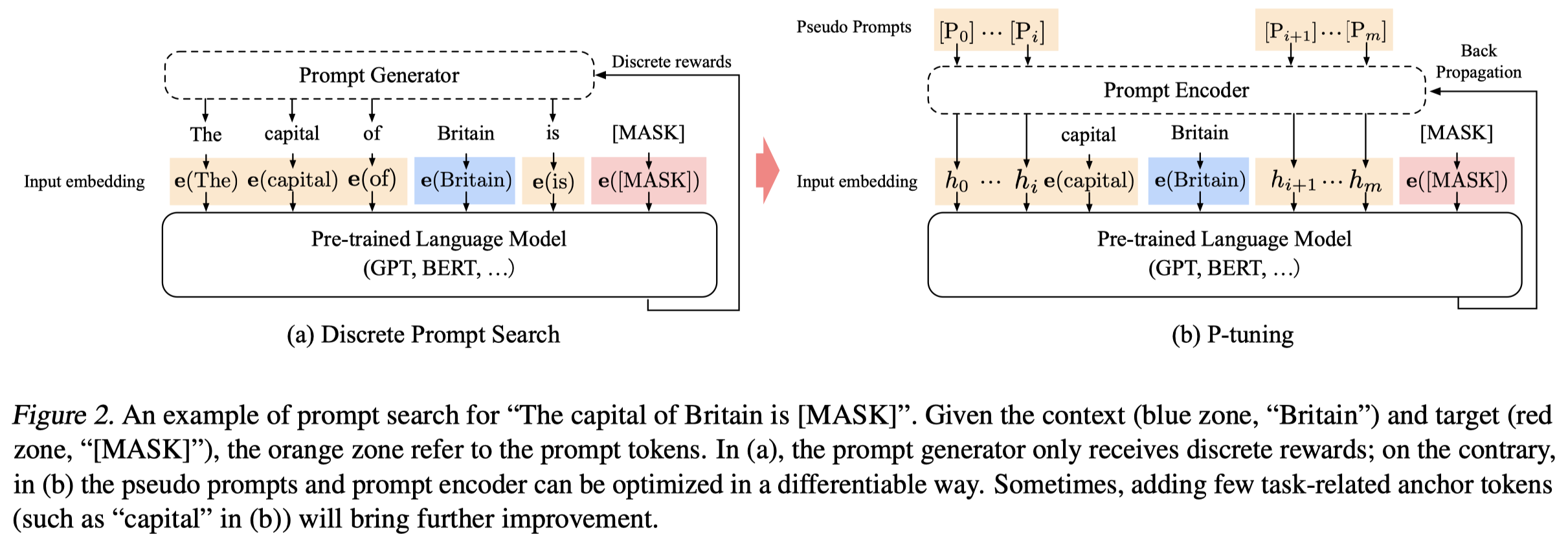
之所以不重新直接学习新的embedding,而是要由一个model生成,是因为:
- Discreteness: 随机初始化的embedding,在更新之后可能差异性不够大,可能只有一些部分邻居element获得了更新。the original word embedding \(e\) of \(M\) has already become highly discrete after pre-training. If \(h\) is initialized with random distribution and then optimized with stochastic gradient descent (SGD), which has been proved to only change the parameters in a small neighborhood.
- Association: 保证输入的soft prompt之间应该是连续的。another concern would be, intuitively, we believe the values of prompt embeddings \(h_i\) should be dependent on each other rather than independent. We need some mechanism to associate prompt embeddings with each other.
所以作者实际的获取prompt方法:
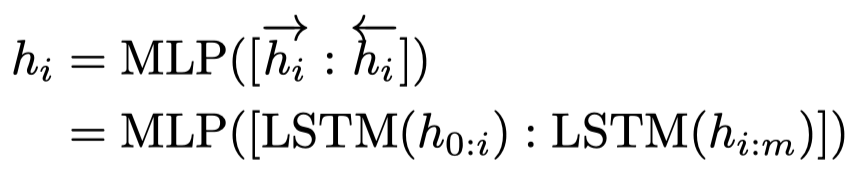
方法本质上是用一个model来重新学习几乎所有的word embedding。
实验结果: