LLM-ICL
LLM in-context learning
LLM上下文学习,相关论文合集1。
APE
Large Language Models are Human-Level Prompt Engineers
ICLR 2023,University of Toronto,代码。
By conditioning on natural language instructions, large language models (LLMs) have displayed impressive capabilities as general-purpose computers. However, task performance depends significantly on the quality of the prompt used to steer the model, and most effective prompts have been handcrafted by humans. Inspired by classical program synthesis and the human approach to prompt engineering, we propose Automatic Prompt Engineer (APE) for automatic instruction generation and selection. In our method, we treat the instruction as the “program,” optimized by searching over a pool of instruction candidates proposed by an LLM in order to maximize a chosen score function. To evaluate the quality of the selected instruction, we evaluate the zero-shot performance of another LLM following the selected instruction. Extensive experiments show that our automatically generated instructions outperform the prior LLM baseline by a large margin and achieve better or comparable performance to the instructions generated by human annotators on 24/24 Instruction Induction tasks and 17/21 curated BIG-Bench tasks. We conduct extensive qualitative and quantitative analyses to explore the performance of APE. We show that APE-engineered prompts are able to improve few-shot learning performance (by simply prepending them to standard in-context learning prompts), find better zero-shot chain-of-thought prompts, as well as steer models toward truthfulness and/or informativeness.
作者提出一种从几个样例中自动创建task instruction的training free的方法APE(Automatic Prompt Engineer)。
由于LLM对于prompt的理解和人类不一样,因此简单的语言prompt不一定能够得到理想的结果。因此往往需要大量的人工去设计prompt,去搜索寻找最好的prompt实践。作者将自动寻找最能够激发LLM执行具体task能力的prompt的过程看做是一个black-box optimization problem,称之为natural language program synthesis。
作者提出的APE方案如下:
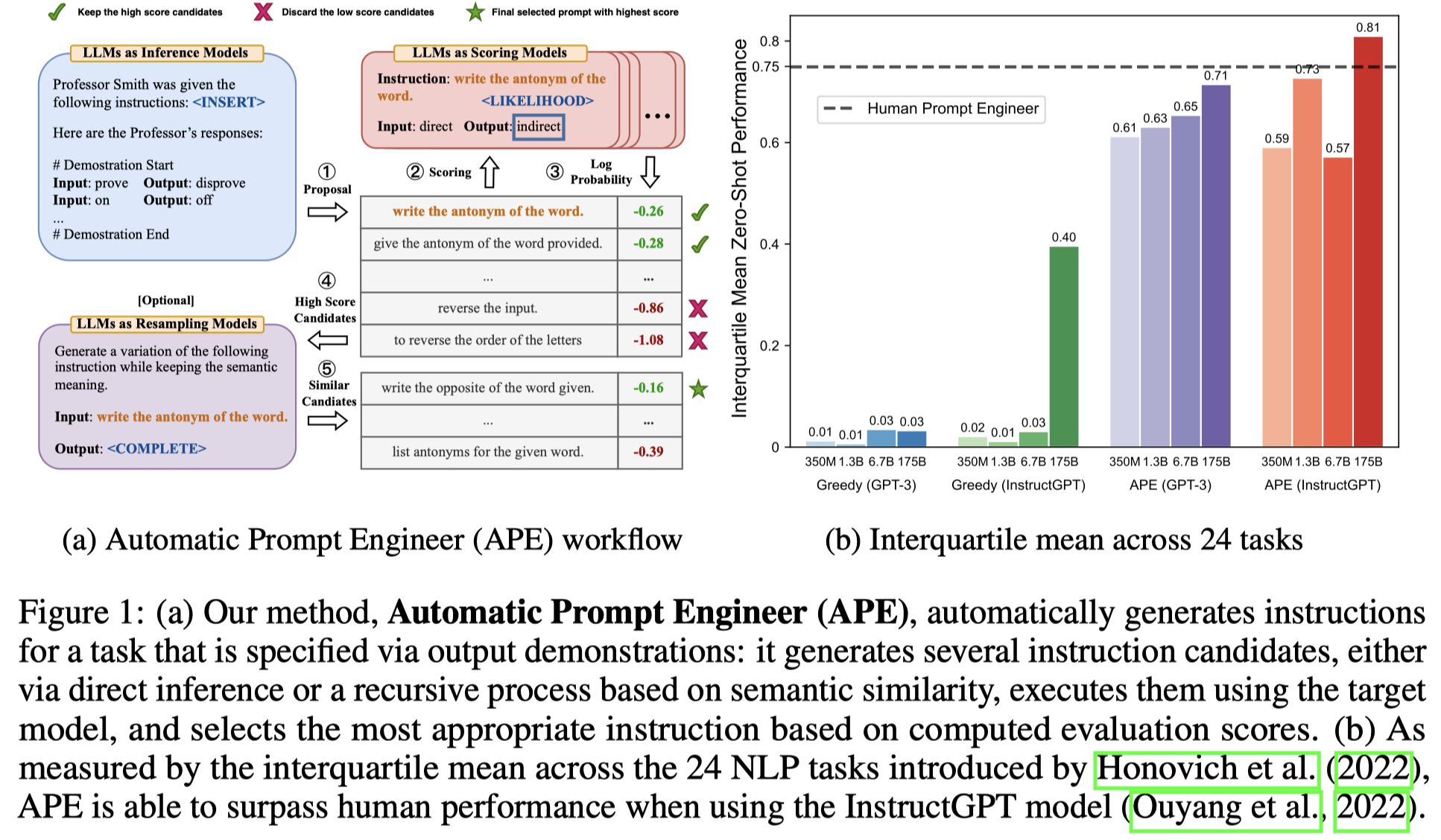
简单来说就是3步,
- 让LLM从几个样例中产生一系列的task instructions
- 让LLM使用不同的task instructions,评估不同task instructions的效果。先选一个子集评估所有的instruction,然后对于score比较高的instructions,再选新的子集评估筛选,直至选出一定数量的候选instructions
- [可选] 为了防止在某些任务下,LLM一开始没有找到合适的instructions,重新采样。让LLM在当前score最高的instructions附近采样
第1步采样初始的task instructions,作者使用了三种方式:

第一种forward mode prompt是最直接的,让LLM续写query,但是instructions只会出现在句子最后。作者提出第2种reverse mode prompt让LLM填空,让instructions可以出现在句子的任意地方。最后是对于一些已经发现了效果比较好的模板,可以加进来(具体在实验中可能作者只是在TruthfulQA数据集下使用了?)。
第2步怎么样评价不同instructions的效果,当然最直接的是根据任务指标来验证。在一般情况下,作者建议可以直接使用0-1 loss来给不同生成的instructions打分。还可以使用log probability。同时,让每个instructions都在所有的训练样例下进行评估是不实际的,因此作者就提出使用训练子集来筛选合适的instructions。如果一个子集筛选过后的instructions还是太多,就继续采样新的不重叠的训练子集,继续筛选instructions。
第3步是针对一些情况下,LLM生成的所有instructions没有找到合适的instructions,让LLM继续在当前效果最好的instructions周围进行寻找。we consider exploring the search space locally around the current best candidates. 这一步是可选的,因为作者发现不断增加更多的迭代步骤没有带来更多的提升,同时这种提升也不是在所有task中都会出现。(在实验中APE默认无迭代,APE-IT是加入了迭代)
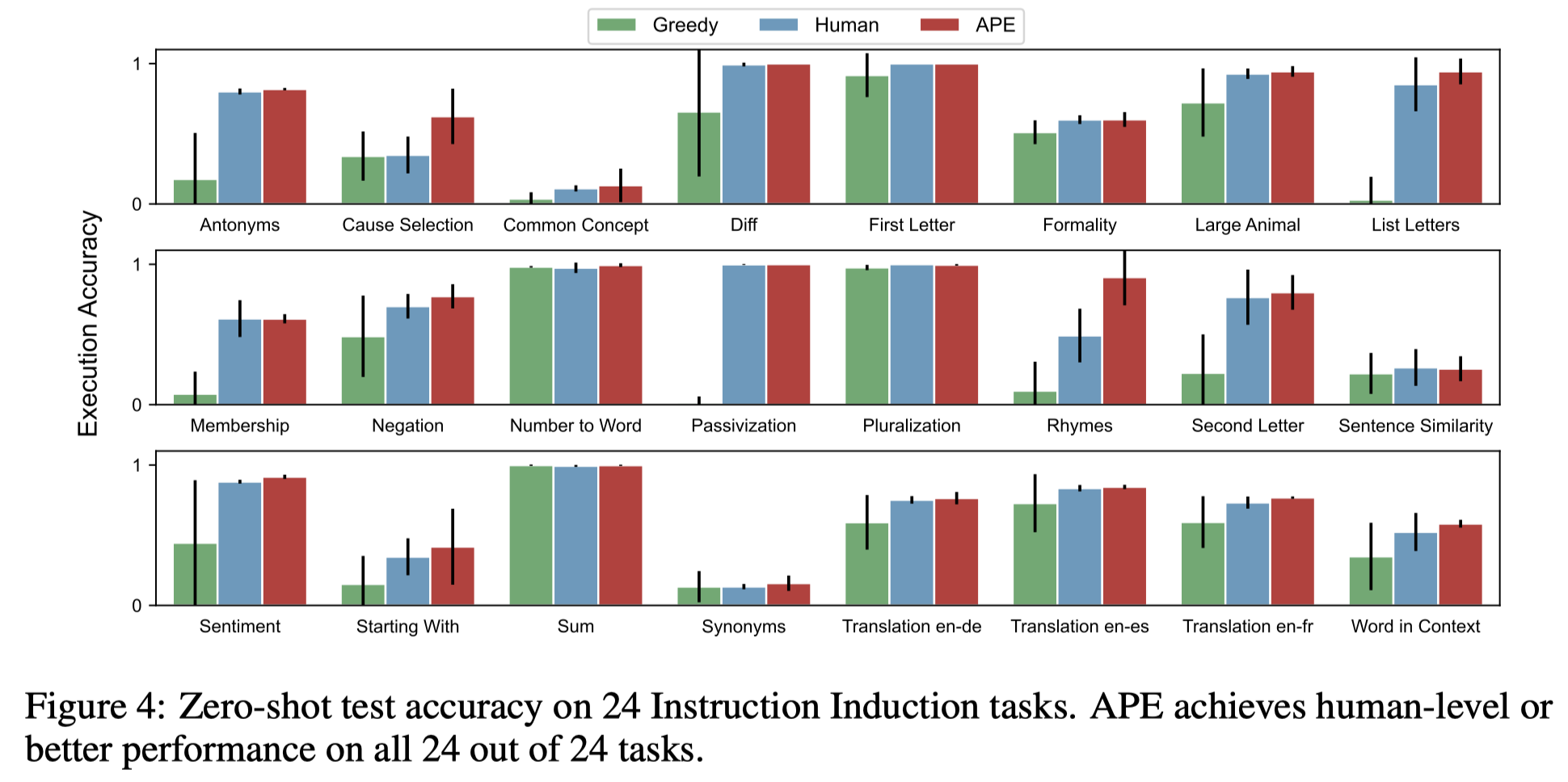
zero-shot instruction induction实验结果来看,APE方法在很多任务上已经达到了人工prompting的效果:
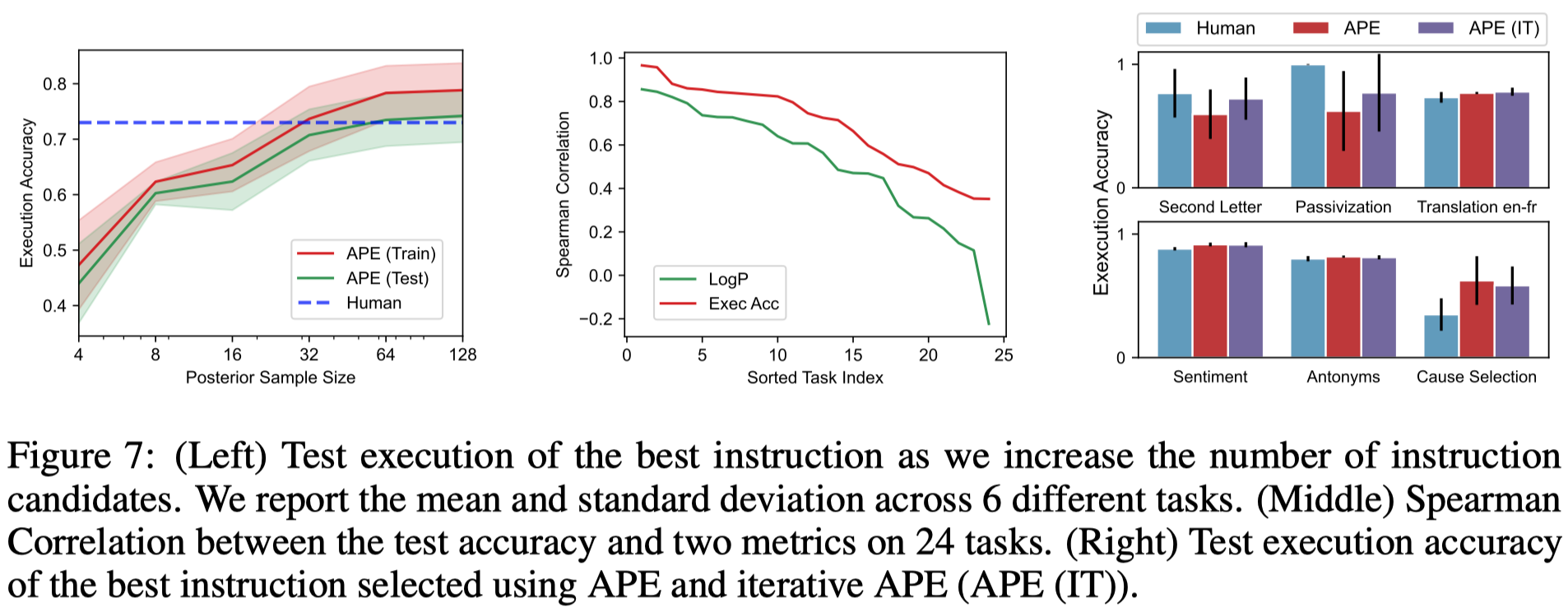
生成更多的候选instructions带来了更好的效果,同时iterative search对于那些一开始没有办法找到合适的instructions的task有提升作用,而在另外task上仅仅是生成一次就效果比较好了:
SG-ICL
Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
NAACL 2022 Workshop,首尔大学
Large-scale pre-trained language models (PLMs) are well-known for being capable of solving a task simply by conditioning a few input-label pairs dubbed demonstrations on a prompt without being explicitly tuned for the desired downstream task. Such a process (i.e., in-context learning), however, naturally leads to high reliance on the demonstrations which are usually selected from external datasets. In this paper, we propose self-generated in-context learning (SG-ICL), which generates demonstrations for in-context learning from PLM itself to minimize the reliance on the external demonstration. We conduct experiments on four different text classification tasks and show SG-ICL significantly outperforms zero-shot learning and is generally worth approximately 0.6 gold training samples. Moreover, our generated demonstrations show more consistent performance with low variance compared to randomly selected demonstrations from the training dataset.
利用LLM自动生成demonstrations来增强zero-shot ICL的能力(作者声称是首个这么做的工作)。
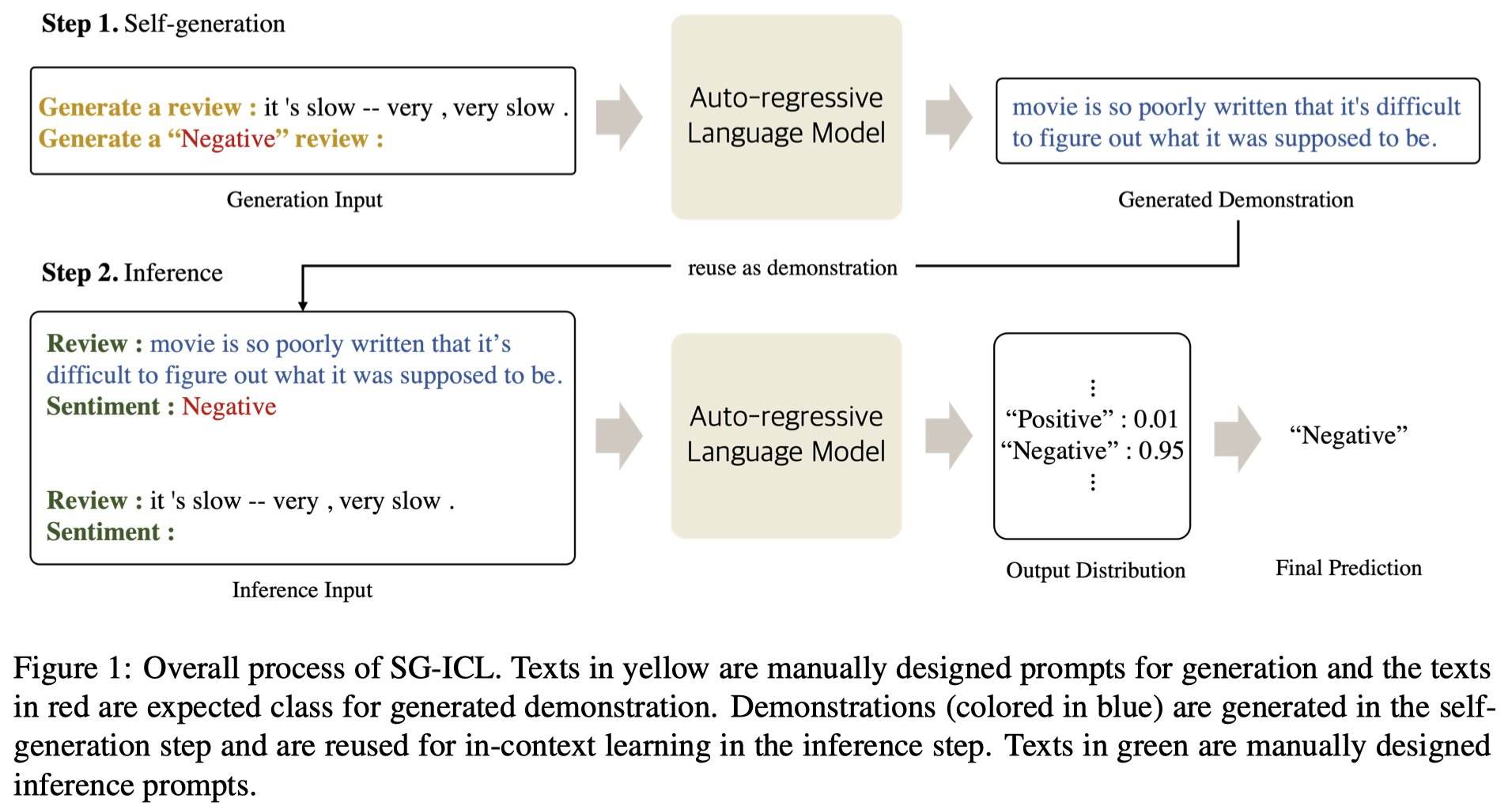
需要注意的一点是,在使用LLM生成demonstrations的时候,是输入了对应的test instance和期望生成的class一起生成的。

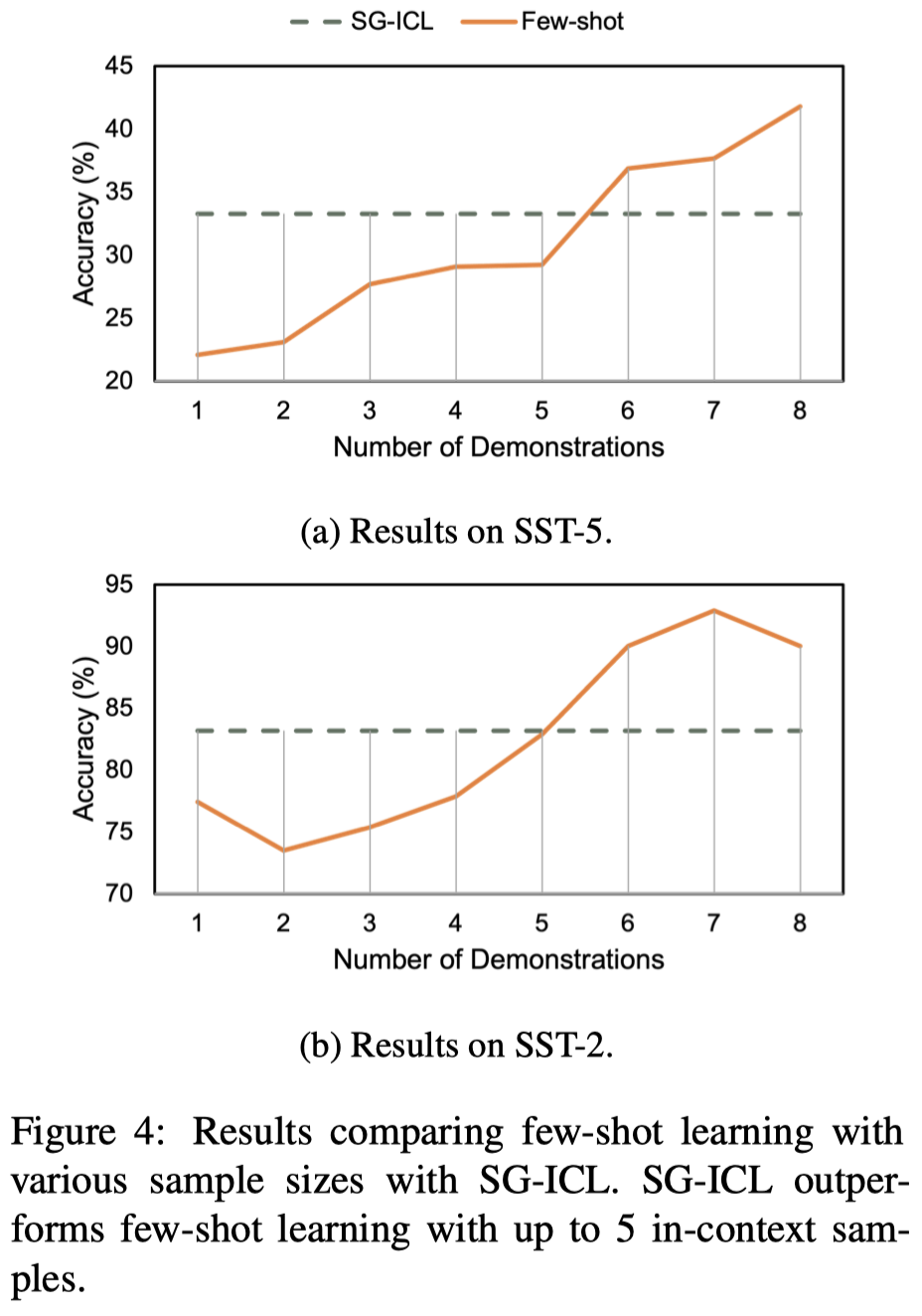
作者在实验部分使用LLM位每个test instance生成8个构造的demonstrations,发现效果和在进行5-shot的LLM ICL效果差不多,因此作者认为1个LLM生成的demonstration价值相当于0.6个gold training sample:
Self-Instruct
ACL 2023,华盛顿大学,代码。
[个人详细博客]Large “instruction-tuned” language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce SELF-INSTRUCT, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off their own generations. Our pipeline generates instructions, input, and output samples from a language model, then filters invalid or similar ones before using them to finetune the original model. Applying our method to the vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on SUPER-NATURALINSTRUCTIONS, on par with the performance of InstructGPT 001, which was trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with SELF-INSTRUCT outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT 001 . SELF-INSTRUCT provides an almost annotation-free method for aligning pretrained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
人工生成instructions一方面代价很大,另一方面人工生成的instructions难以保证quantity, diversity, and creativity。
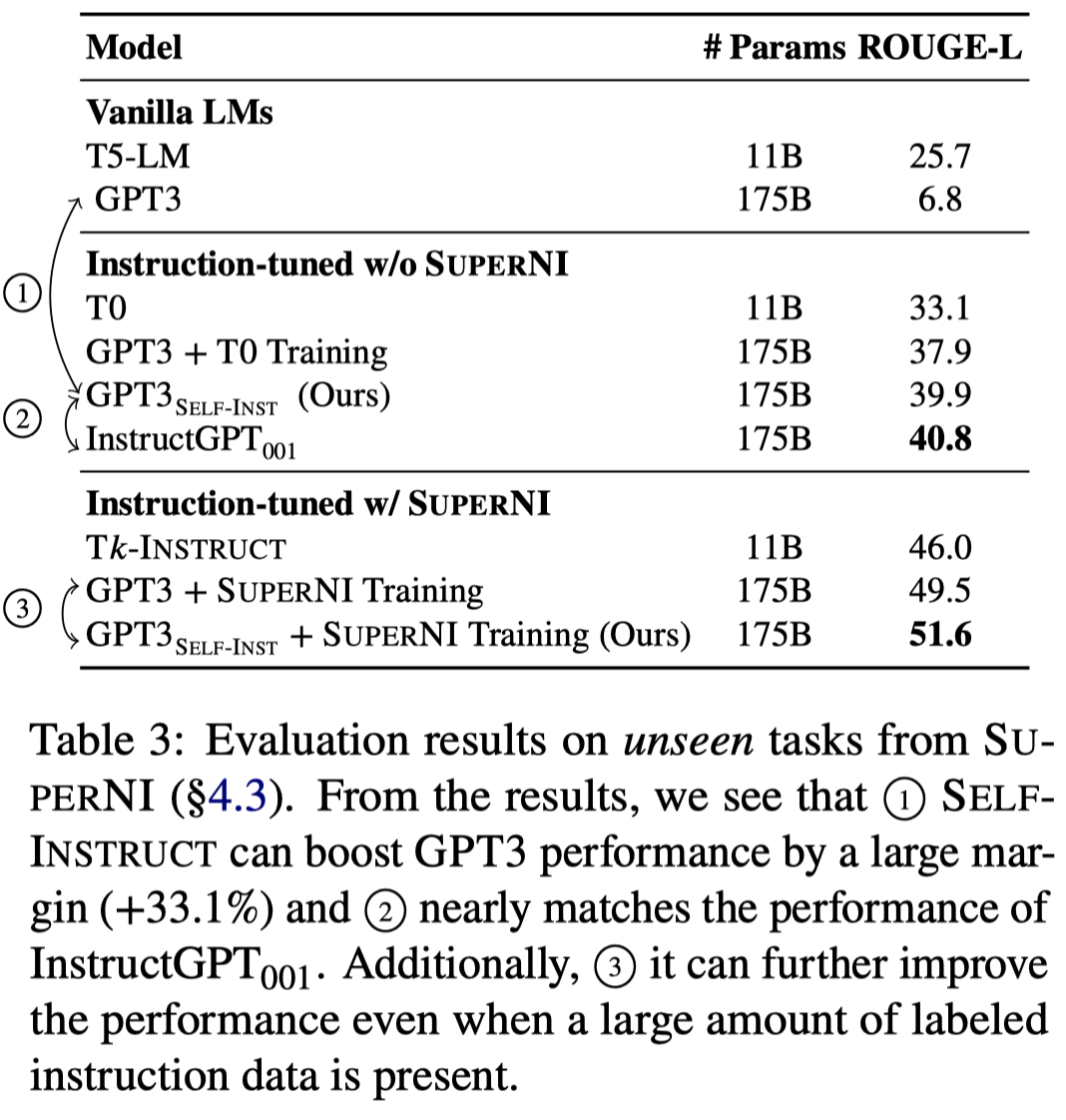
作者提出使用LLM从已有的task instruction出发,自动生成新的task instruction和对应的input-output,然后过滤掉不符合规则的新task instructions,再加入到已有的task instructions集合中。作者在这个自动构造的instruction data上fine-tuning GPT3,发现效果提升了33%,非常接近InstructGPT001的效果。
作者提出的方法:
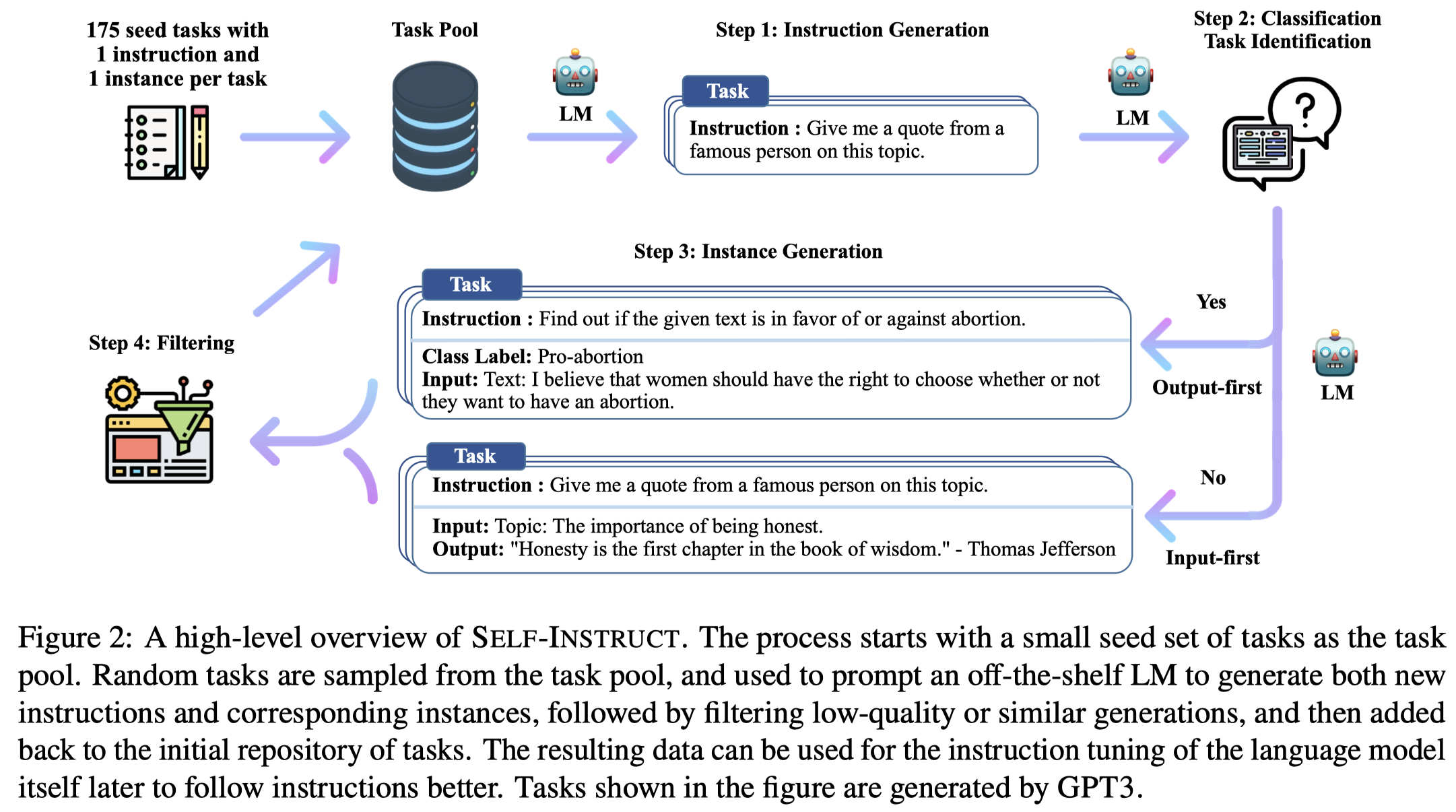
首先,作者拥有一个task pool,包括175 tasks (1 instruction and 1 instance for each task)。这175个初始的task instructions都是由本文作者自己创建的。
然后,作者从task pool中随机抽取8个task instructions(6 are from the human-written tasks, and 2 are from the model-generated tasks)。下面是产生新task instruction的prompt:

之后,作者使用LLM判断新产生的instruction是否是一个classification task(using 12 classification instructions and 19 non-classification instructions):


随后,对于新产生的task instruction,用LLM生成新的对应的instance。对于生成任务,作者先生成input,再生成output,作者称为Input-first Approach:


对于分类任务,作者发现如果是先生成input,LLM总是会倾向于生成某一个label的输入。因此作者使用LLM先生成output label,再让LLM生成input,作者称为Output-first Approach:


对于LLM生成的task instruction、input和output,需要通过一些规则过滤,比如:
- 只有当和已有的task instruction相似度全部比较低(\(\mbox{ROUGE-L}< 0.7\))的时候,一个新task instruction会被添加到task pool里
- We also exclude instructions that contain some specific keywords (e.g., image, picture, graph) that usually can not be processed by LMs.
- When generating new instances for each instruction, we filter out instances that are exactly the same or those with the same input but different outputs.
- Invalid generations are identified and filtered out based on heuristics (e.g., instruction is too long or too short, instance output is a repetition of the input).
作者从原始的175个task出发,最后构造了5万多的task,并且差异性也比较大:
在SuperNI数据集上的实验结果:
SuperNI数据集大多是已有的NLP任务,为了进一步评估模型在实际使用场景下的价值,作者人工创建了一个包括252 task的新数据集。
Discrete prompt for different SLM
Can discrete information extraction prompts generalize across language models?
ICLR 2023,代码。
作者探究了不同小参数量语言模型对于discrete prompt的泛化性的情况,并且提出了mixed-training autoprompt。也就是在AutoPrompt的方法基础上,用一个LM进行候选prompt生成,另一个LM进行评估。
We study whether automatically-induced prompts that effectively extract information from a language model can also be used, out-of-the-box, to probe other language models for the same information. After confirming that discrete prompts induced with the AutoPrompt algorithm outperform manual and semi-manual prompts on the slot-filling task, we demonstrate a drop in performance for AutoPrompt prompts learned on a model and tested on another. We introduce a way to induce prompts by mixing language models at training time that results in prompts that generalize well across models. We conduct an extensive analysis of the induced prompts, finding that the more general prompts include a larger proportion of existing English words and have a less order-dependent and more uniform distribution of information across their component tokens. Our work provides preliminary evidence that it’s possible to generate discrete prompts that can be induced once and used with a number of different models, and gives insights on the properties characterizing such prompts.
作者对比了三种方法产生的prompt:
- LPAQA:使用预先定义好的几个prompt,通过mining和paraphrasing发现更多的prompt
- AutoPrompt:让LM自动生成prompt
- OptiPrompt:使用了soft prompt
作者在下面一系列的小LM上进行了实验:
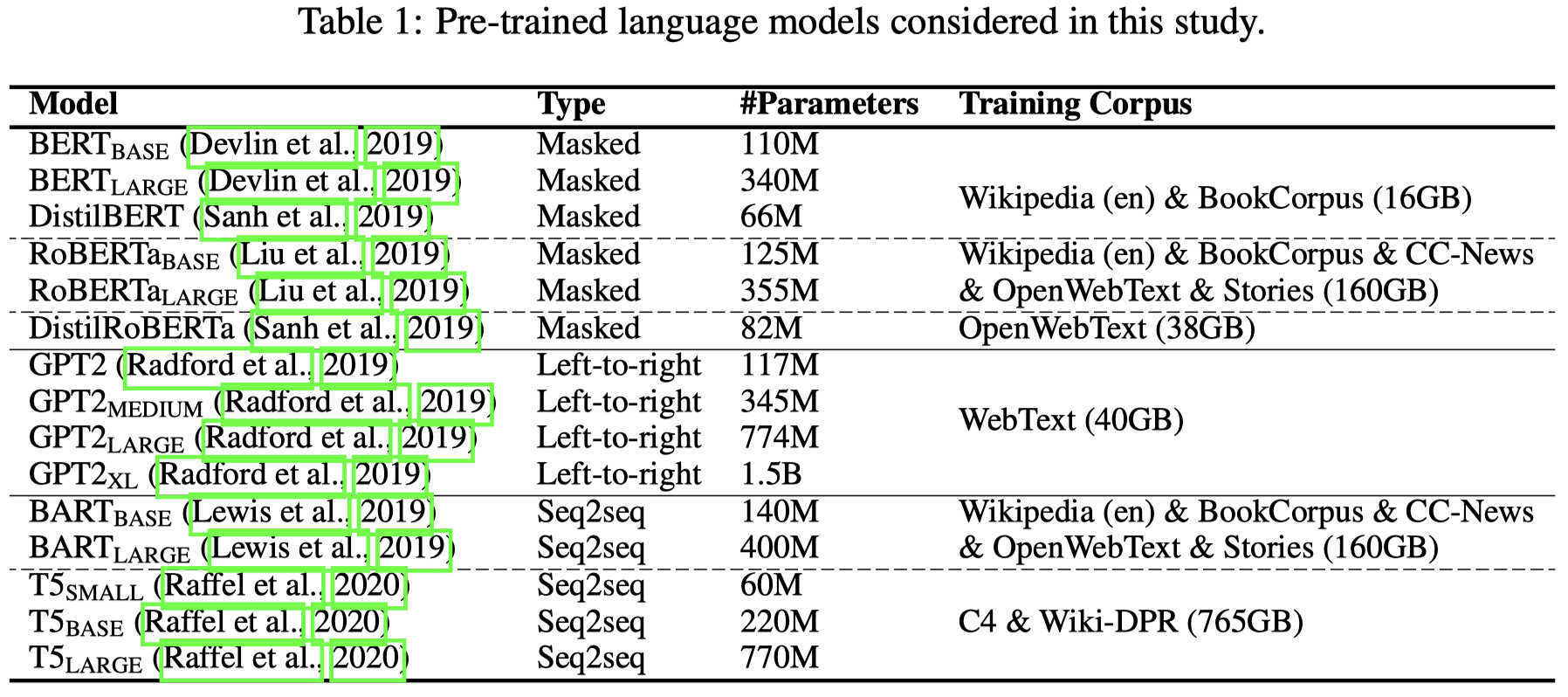
在LAMA数据集上的对比效果如下,表格中LAMA是指该数据集本身提供的人工写的prompt:
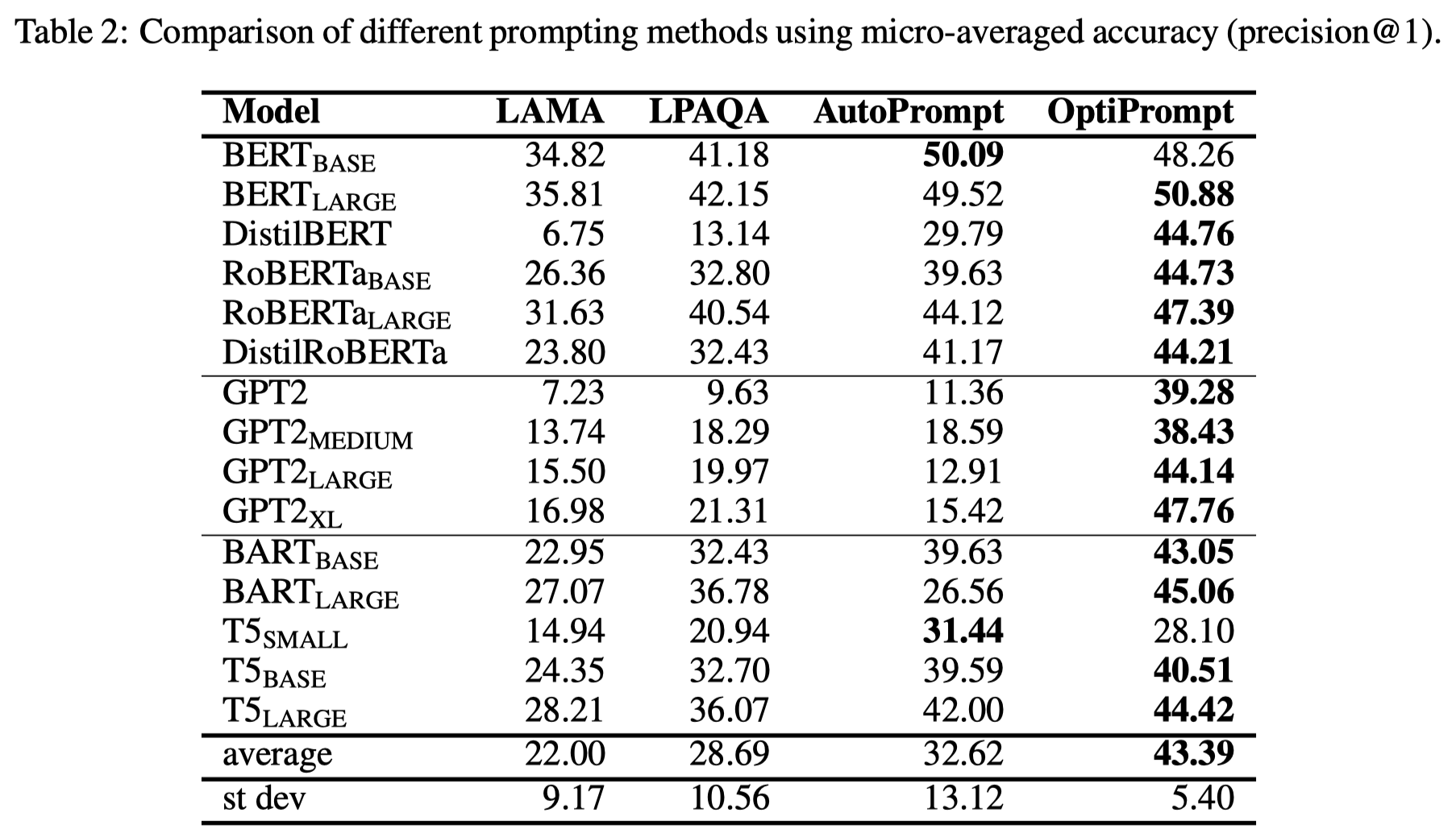
作者发现使用了soft prompt的OptiPrompt方法效果最好,而AutoPrompt这种自动生成discrete prompt的方法效果次之,但也是好于人工写的prompt。
soft prompt虽然在自动生成prompt和使用prompt的LM是一致的情况下效果最好,但是泛化性很差:
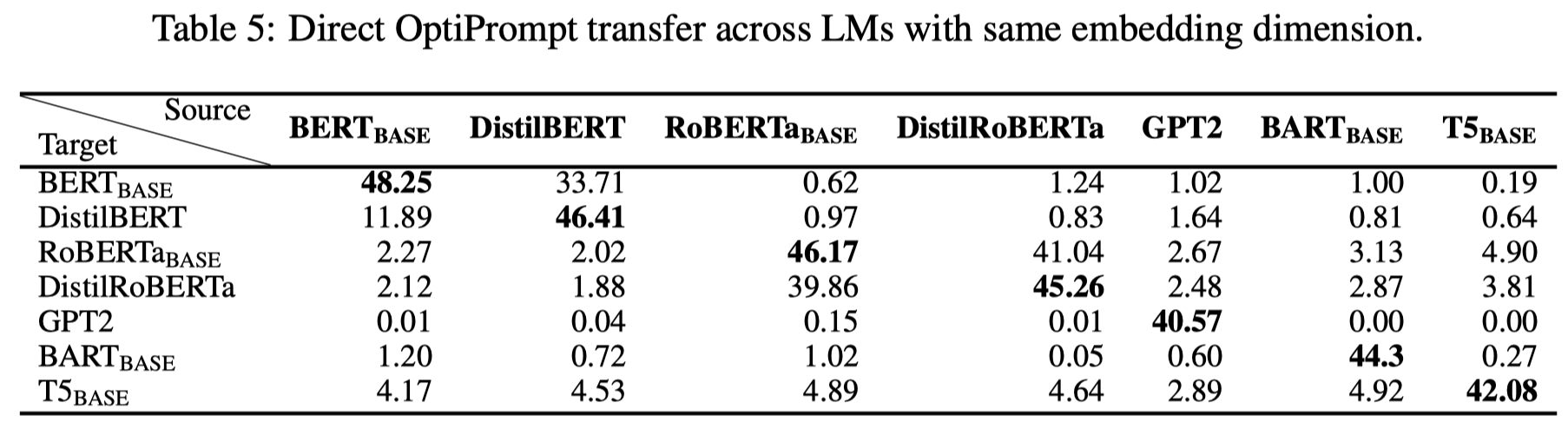
同时soft prompt还要求能够访问LM的内部结构,能够使用它的embeddings。
作者进而测试了在使用AutoPrompt的情况下,这些生成的prompt在source LM和target LM不一致的情况下的效果:
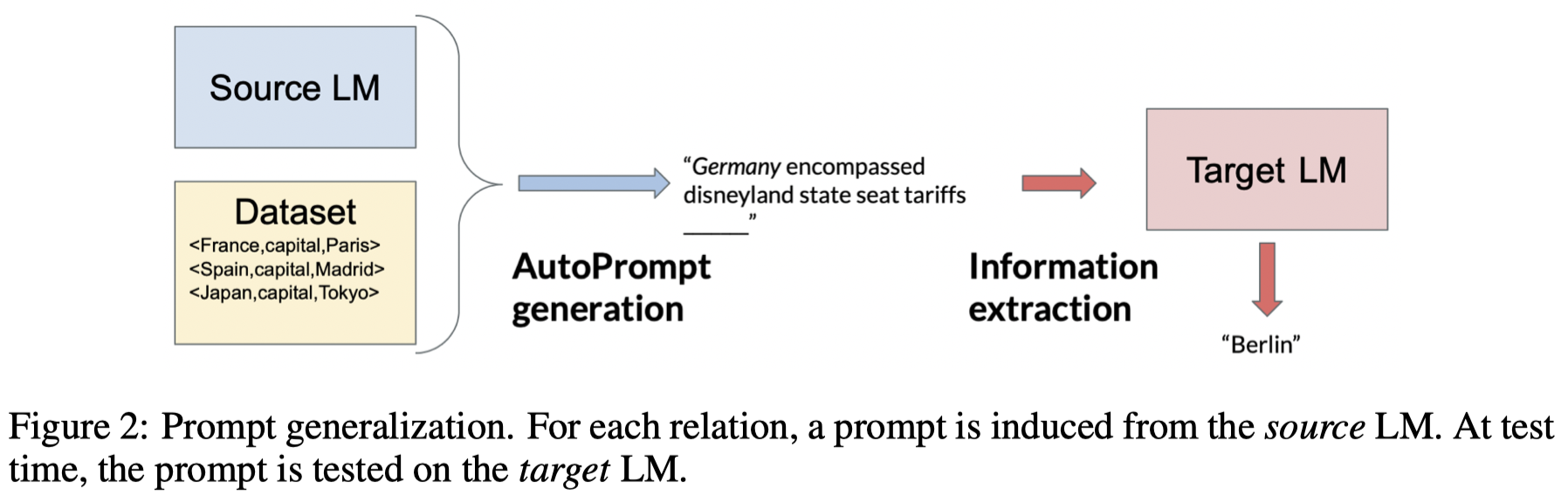
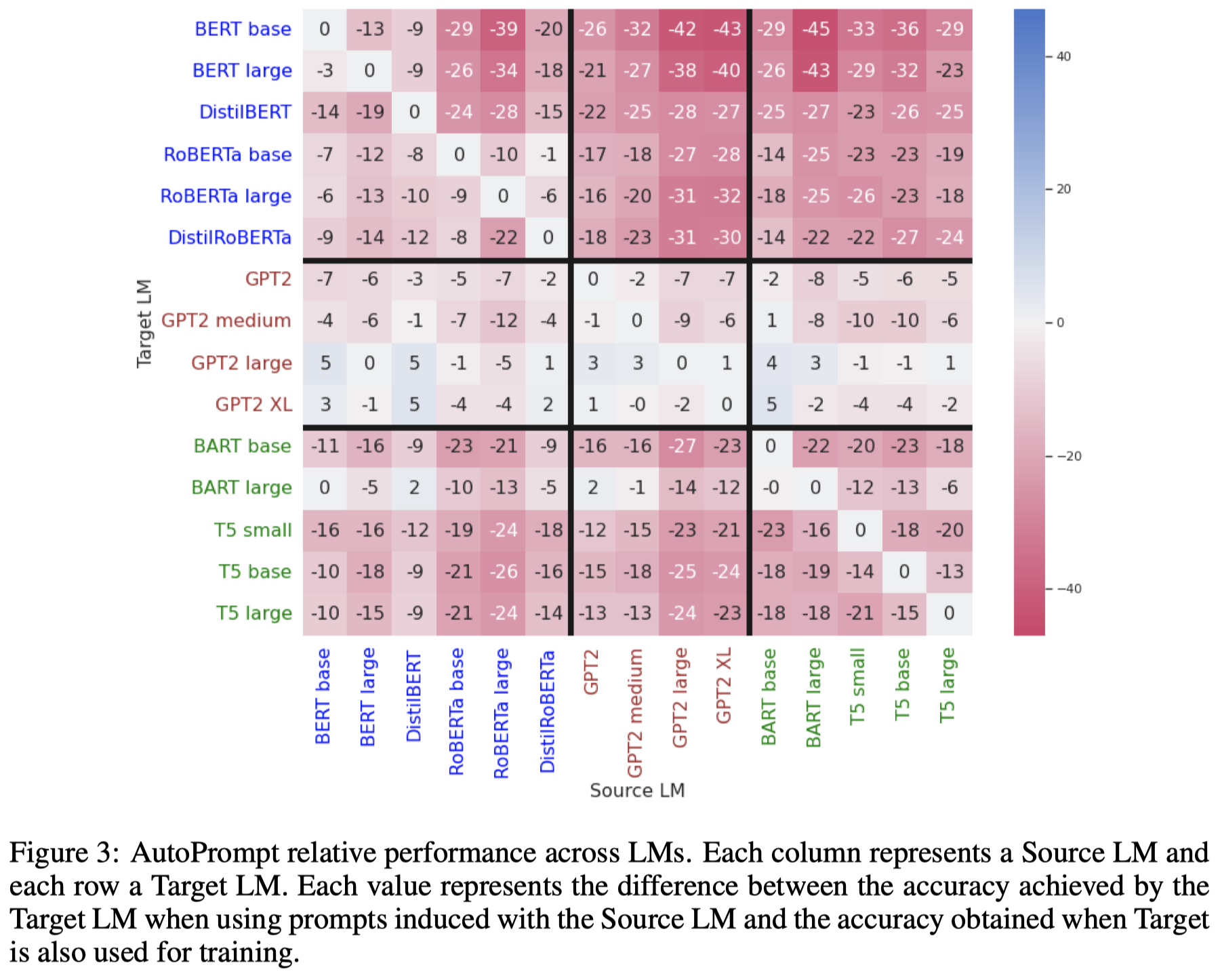
可以看出来,当两个LM是一样的情况下,效果最好。如果target LM和source LM不一致的情况下,基本上效果都会下降。中间GPT-2的一系列变种变化不大,作者解释原因是GPT-2本身效果已经比较差了,再差点也没有什么太大变化了。
为了解决这一问题,作者提出了AutoPrompt的一个简单改动:
Recall that the AutoPrompt algorithm involves two phases: one in which candidate prompts are generated, and one in which the prompts are evaluated. Rather than relying on the same model for the two phases, we now use two different LMs. The first model, which we call the generator, proposes a set of candidates. Then, the second model, that we call the evaluator, evaluates the candidates and chooses the best one.
下面是作者的实验:

可以看到,不同架构的LM混合在一起,是可能生成具有更好泛化性的prompt的。但是作者在论文中也指出,这种更好的泛化性的生成和哪两个LM组合到一起有关,不是说只要组合在一起,就能够生成泛化性更好的prompt。
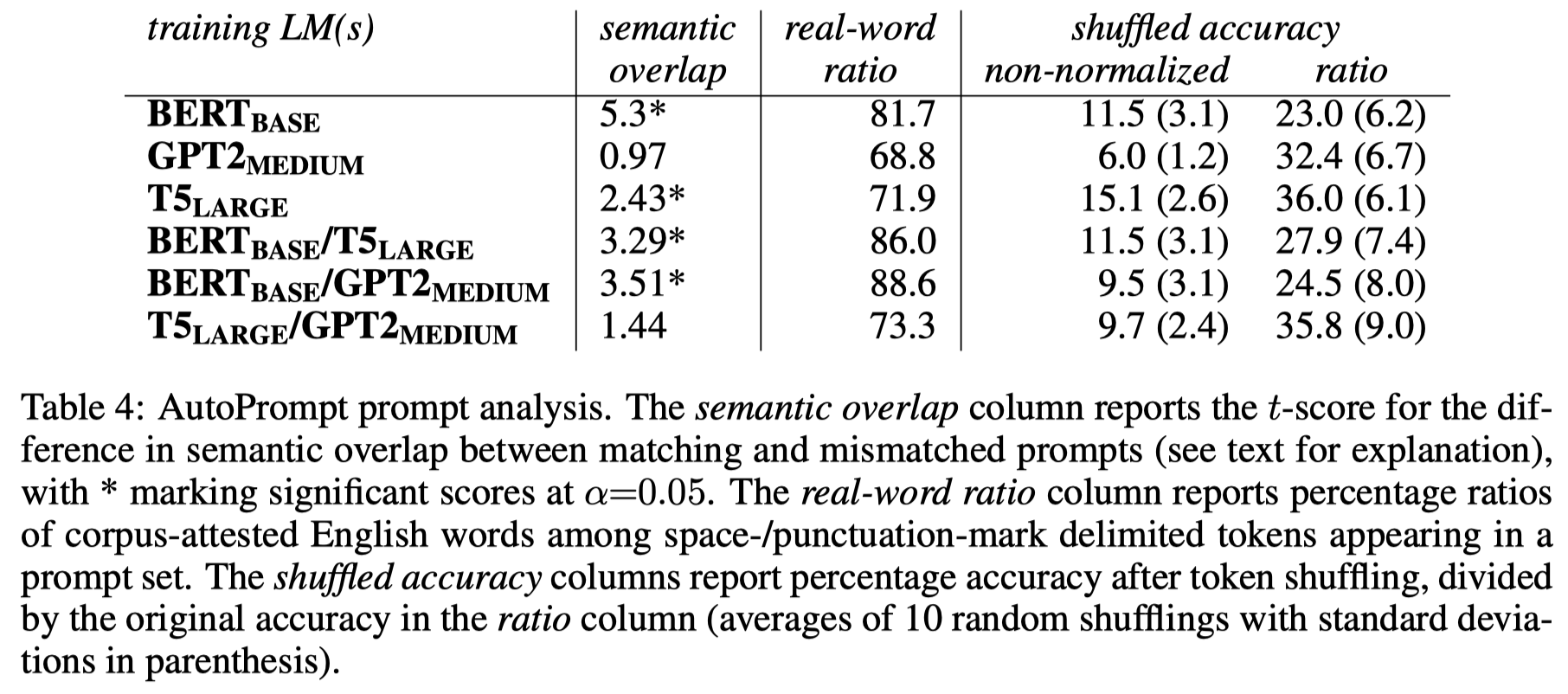
在最后,作者尝试从4个方面对找到的泛化性更好的prompt进行定量分析:
- Semantic overlap with English: We thus hypothesize that prompts that generalize better will have a larger semantic overlap with manually crafted English prompts.
- 作者的观察:对于作者提出的mixed-training AutoPrompt方法来说,泛化性更强的prompt和人类实际语言之间的相似度有很强的相关性。但是这种相似度,和泛化性更弱的单个模型比如BERT-base产生的prompt对比的话,相似度耕地(说明这个假设还有待验证)。
- Real-word ratio: We thus conjecture that prompts that generalize better will contain a larger proportion of real English words.
- 作者的观察:进行了混合策略的方法总是自动产生了更多real world的单词;但是不一定能够带来更好的泛化性。
- Shuffling: We thus conjecture that a “bag-of-token” prompt sequence that does not require the tokens to be in any special order will be more general than one where order matters and, consequently, generalizing prompts will be more robust to token shuffling.
- 作者的观察:更加泛化的prompt确实对于token的顺序更加不敏感
- Token deletion: We thus conjecture that generalizing prompts will distribute information more evenly across tokens and thus they will be more robust to single-token deletion.
- 作者的观察:随机去掉prompt上不同位置token,测试prompt不同位置上,LM的关注程度是不是不同的。发现总是对于prompt最后一个位置的token有最大的关注。
Wang et al.
Large Language Models Are Implicitly Topic Models: Explaining and Finding Good Demonstrations for In-Context Learning
arXiv 2023, 代码。
In recent years, pre-trained large language models have demonstrated remarkable efficiency in achieving an inference-time few-shot learning capability known as incontext learning. However, existing literature has highlighted the sensitivity of this capability to the selection of few-shot demonstrations. The underlying mechanisms by which this capability arises from regular language model pretraining objectives remain poorly understood. In this study, we aim to examine the in-context learning phenomenon through a Bayesian lens, viewing large language models as topic models that implicitly infer task-related information from demonstrations. On this premise, we propose an algorithm for selecting optimal demonstrations from a set of annotated data and demonstrate a significant 12.5% improvement relative to the random selection baseline, averaged over eight GPT2 and GPT3 models on eight different real-world text classification datasets. Our empirical findings support our hypothesis that large language models implicitly infer a latent concept variable.
作者提出了一种看待ICL中的demonstration的作用的角度,认为LLM可以从demonstrations中学习到隐式的任务相关的信息。并且给出了一些理论上的分析。
基于此假设,作者提出一种新的找demonstrations的方法,整体流程如下:
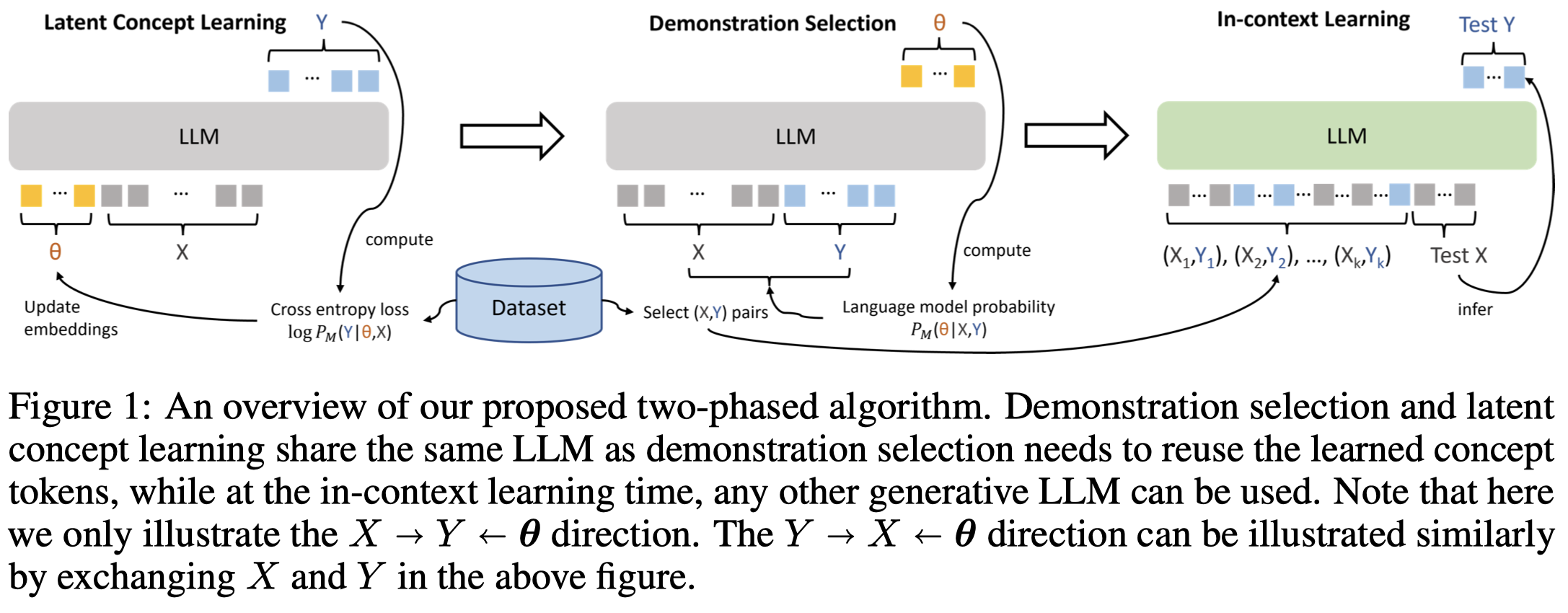
首先是利用prompt-tuning的思想,固定LM,学习和task相关的soft prompt:

然后,作者认为最佳的demonstrations就是能够在给定样例的情况下,使得输出上一步学习到的soft prompt的概率最大的样例。直观上的理解就是说最能够“体现”任务的demonstrations就是最佳的找到的demonstrations。demonstrations的候选集应该是各种数量、各种排序的组合,但是为了减小搜索空间,作者简化到了假设最佳的单个demonstration的采样是相互独立的,然后再排序:

最后,找到的这种最佳的demonstrations,可以用于其它的LM。
实验结果:

KATE
What Makes Good In-Context Examples for GPT-3?
DeeLIO 2022,杜克大学与Microsoft,代码。
GPT-3 has attracted lots of attention due to its superior performance across a wide range of NLP tasks, especially with its in-context learning abilities. Despite its success, we found that the empirical results of GPT-3 depend heavily on the choice of in-context examples. In this work, we investigate whether there are more effective strategies for judiciously selecting incontext examples (relative to random sampling) that better leverage GPT-3’s in-context learning capabilities. Inspired by the recent success of leveraging a retrieval module to augment neural networks, we propose to retrieve examples that are semantically-similar to a test query sample to formulate its corresponding prompt. Intuitively, the examples selected with such a strategy may serve as more informative inputs to unleash GPT-3’s power of text generation. We evaluate the proposed approach on several natural language understanding and generation benchmarks, where the retrieval-based prompt selection approach consistently outperforms the random selection baseline. Moreover, it is observed that the sentence encoders fine-tuned on task-related datasets yield even more helpful retrieval results. Notably, significant gains are observed on tasks such as table-totext generation (44.3% on the ToTTo dataset) and open-domain question answering (45.5% on the NQ dataset).
在GPT-3中的原始ICL是随机找上下文样例,作者发现上下文样例的选择会极大的影响GPT-3的效果:

因此,寻找适用于GPT的上下文样例很关键。最粗暴的做法是穷举所有样例的可能排列,但这个是不实际的。作者提出,利用kNN方法,从训练集中寻找sentence-level语义相似的样例来辅助ICL:
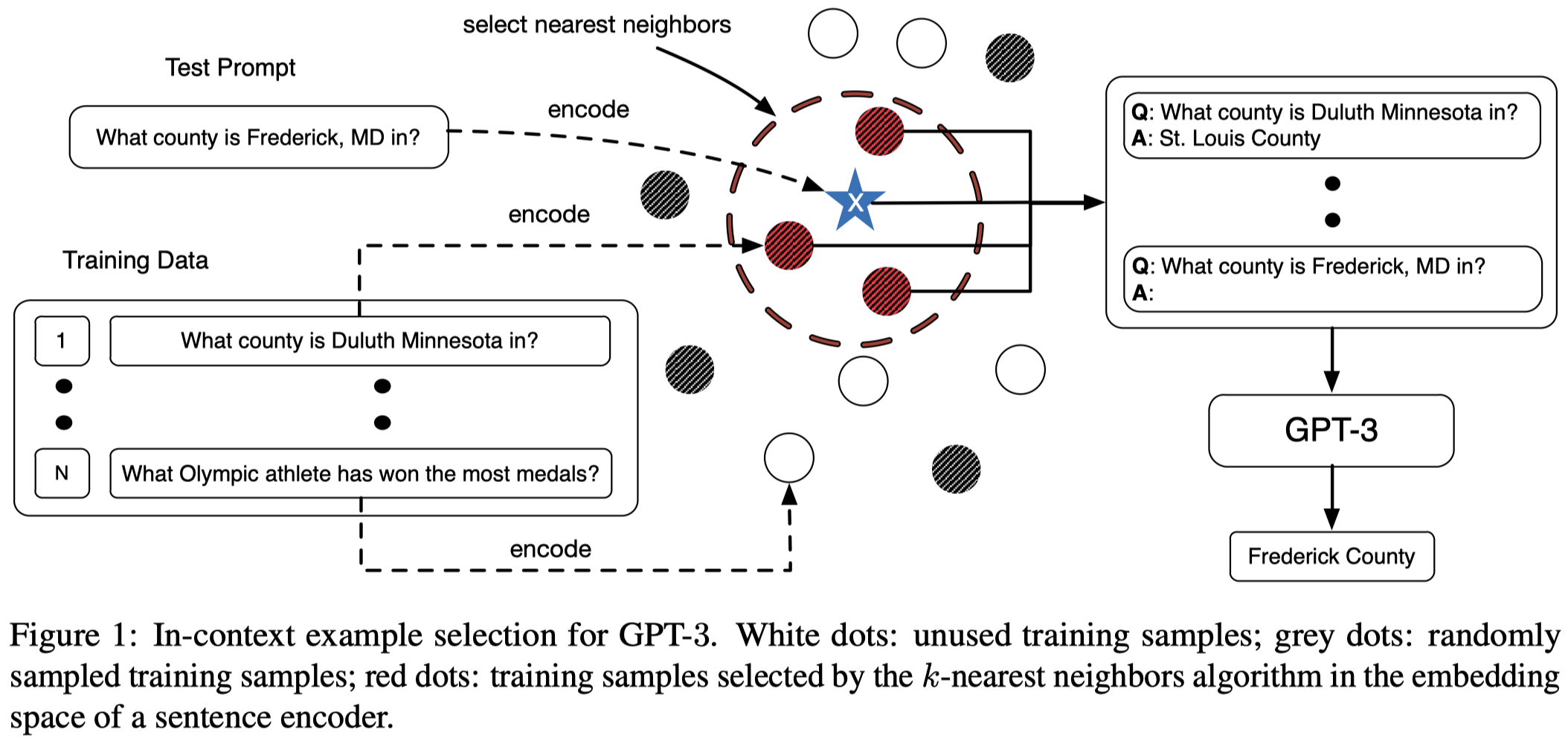
利用kNN找相似样例首先是需要将样例转化为embedding,作者提出两个考虑:
- The first category includes generally pre-trained sentence encoders such as the BERT.
- The second category includes sentence encoders fine-tuned on specific tasks or datasets.
从实验上看,效果提升很明显:
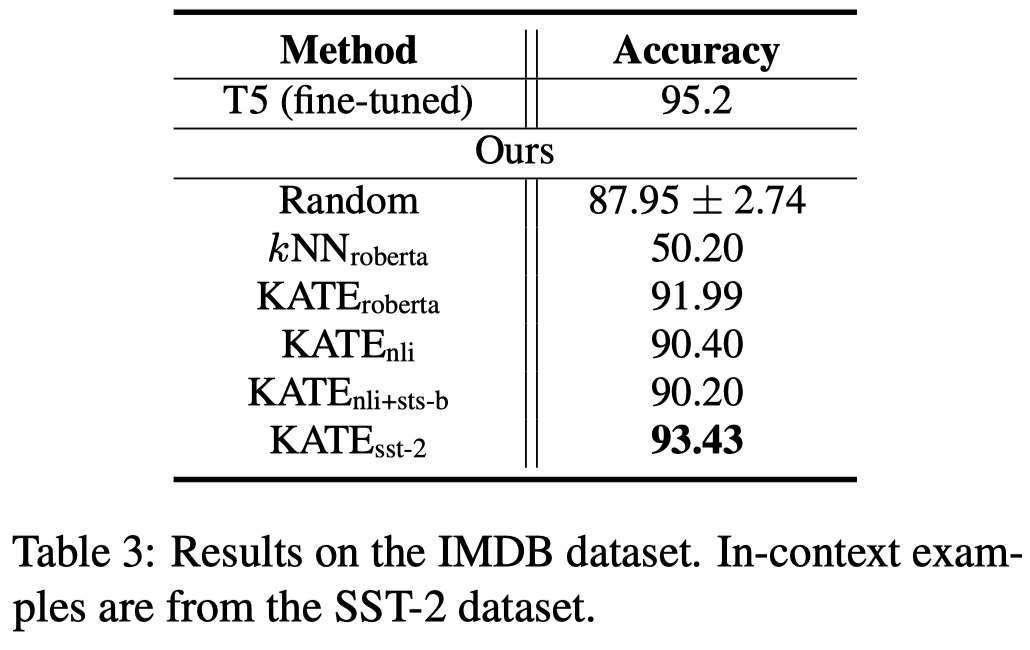
Effect of ordered examples
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
伦敦大学,ACL 2022
When primed with only a handful of training samples, very large, pretrained language models such as GPT-3 have shown competitive results when compared to fully-supervised, fine-tuned, large, pretrained language models. We demonstrate that the order in which the samples are provided can make the difference between near state-of-the-art and random guess performance: essentially some permutations are “fantastic” and some not. We analyse this phenomenon in detail, establishing that: it is present across model sizes (even for the largest current models), it is not related to a specific subset of samples, and that a given good permutation for one model is not transferable to another. While one could use a development set to determine which permutations are performant, this would deviate from the true fewshot setting as it requires additional annotated data. Instead, we use the generative nature of language models to construct an artificial development set and based on entropy statistics of the candidate permutations on this set, we identify performant prompts. Our method yields a 13% relative improvement for GPTfamily models across eleven different established text classification tasks.
之前已经有很多讨论sample structure/formatting的工作,作者声称这篇论文是首个讨论sample顺序对ICL性能影响的paper。
要注意,作者的ICL是corpus-level的prompt,对于所有query,有相同的demonstrations。直接来看作者实验得到的几个结论:
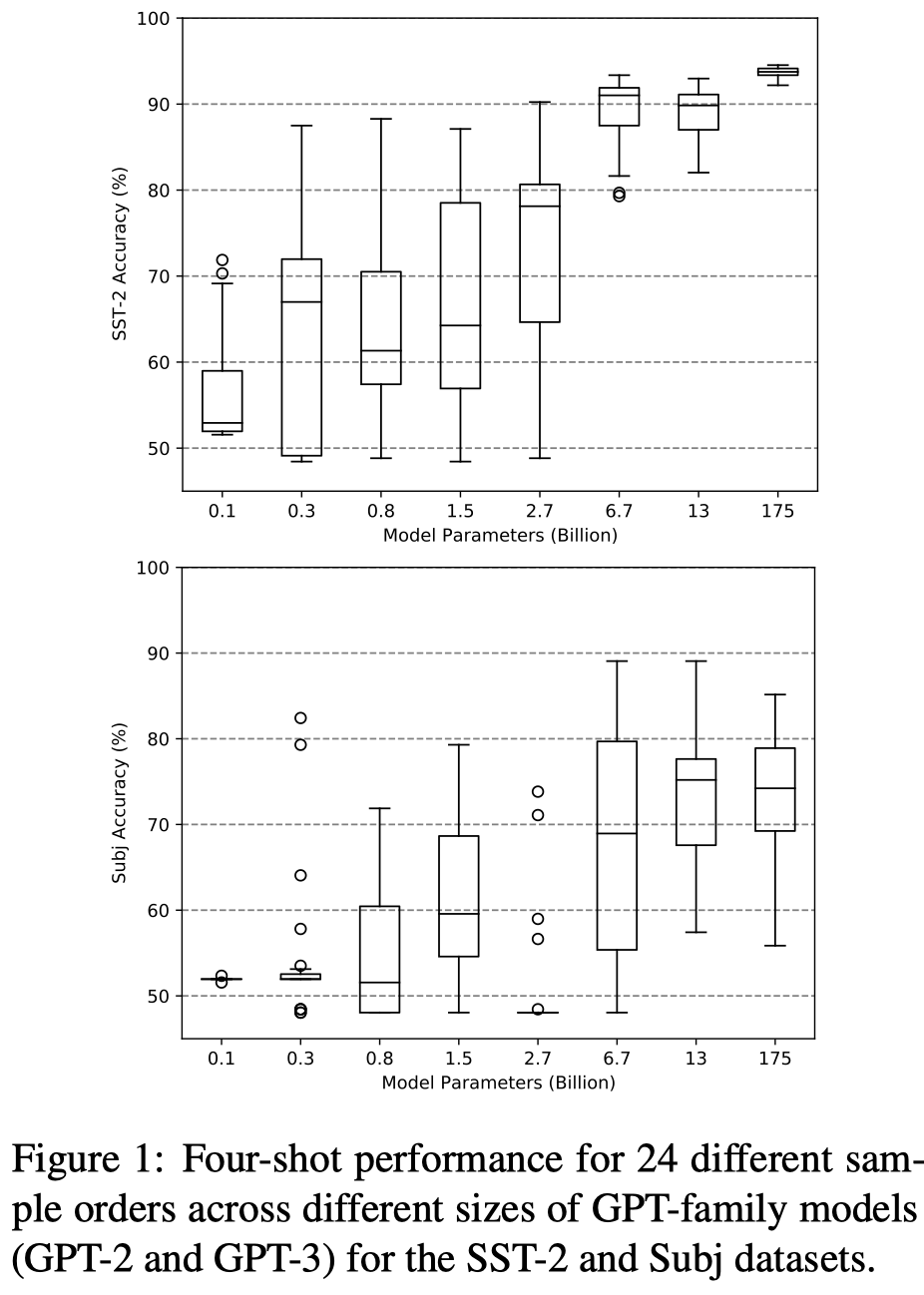
观察:
- ICL中demonstrations的排列顺序很重要,最坏的情况下是50%准确率,也就是随机猜测;最好的排列是性能接近有监督SOTA方法
- LLM对于demonstrations的order很敏感,增大model size虽然似乎会一定程度缓解模型对example order的敏感程度,但是在一些任务下,这种缓解趋势并不存在(如Figure 1下面在Subj数据集的实验结果)
- 与之相反的,传统的有不同初始化设置的有监督训练的方法的性能variance,可能就是在1%-2%(反正肯定在个数百分比)的变化。
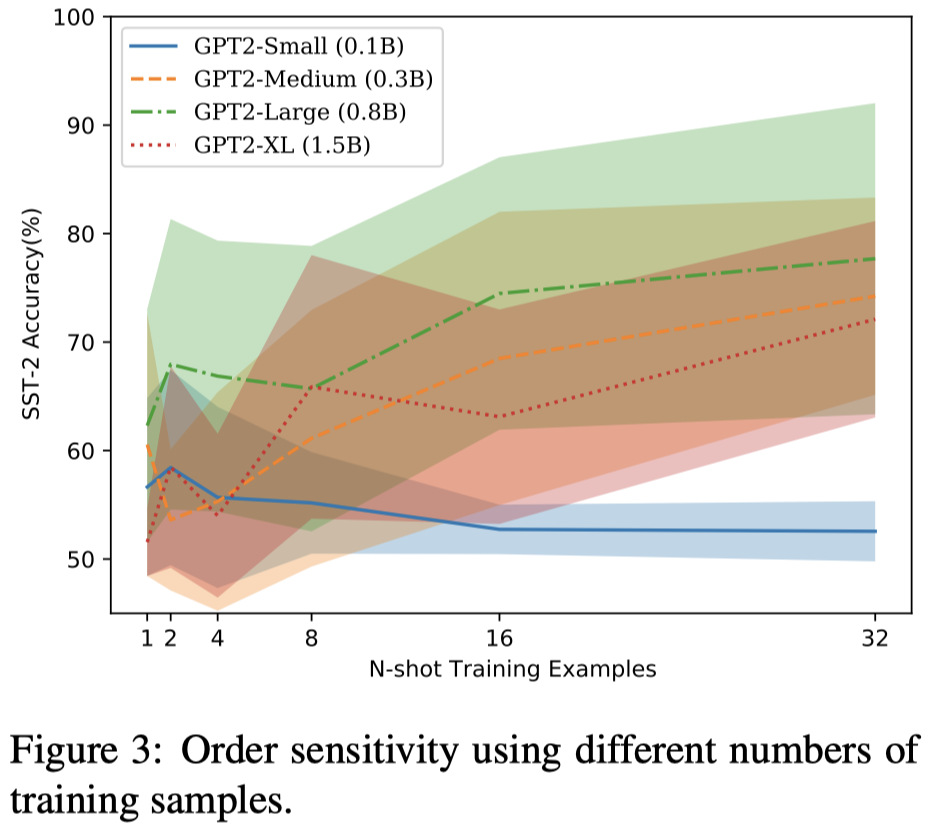
观察:
- Adding training samples does not significantly reduce variance. 增加上下文样例数量并不会缓解对order的敏感性。
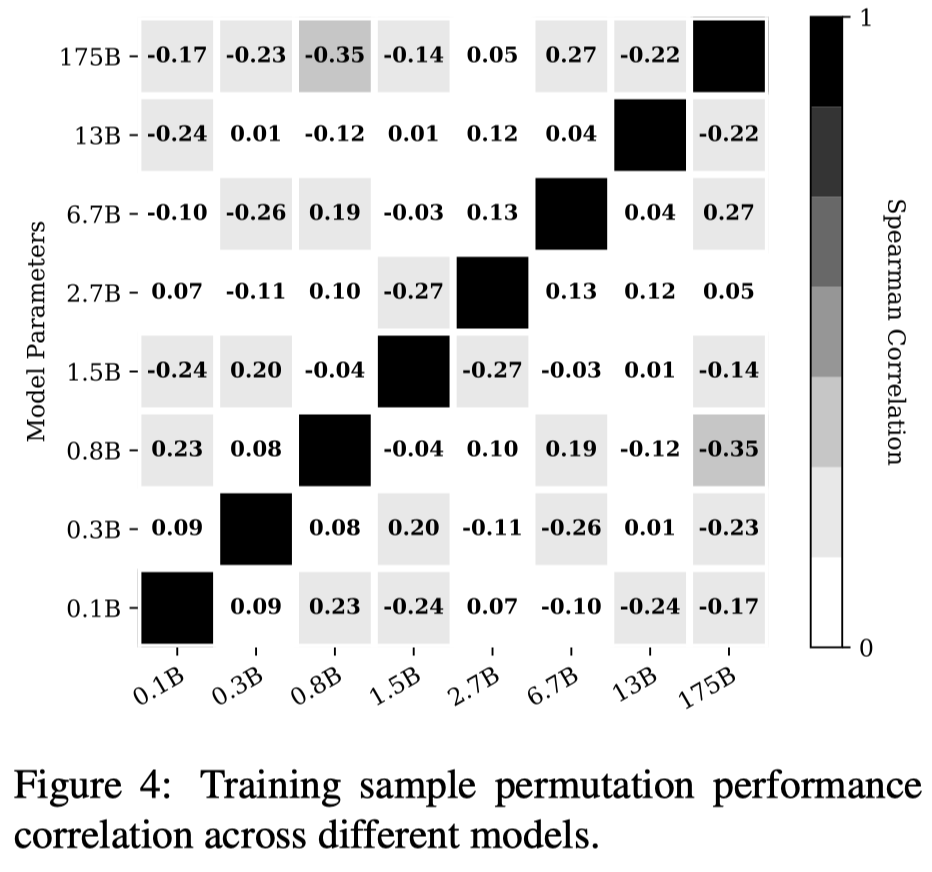
观察:
- Performant prompts are not transferable across models. 不同LLM偏好的order是不通用的(图中的pairwise Spearman’s rank correlation系数很小)
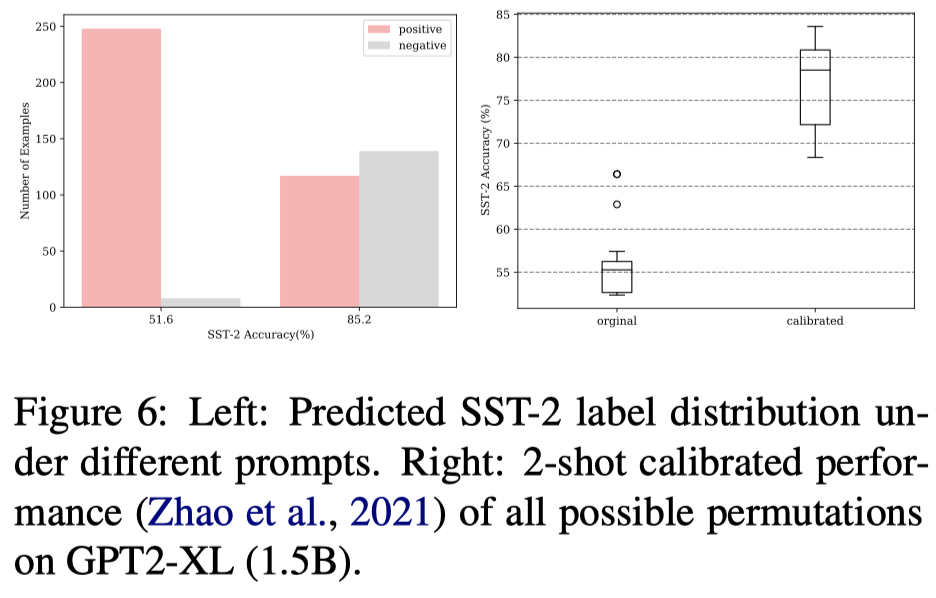
观察:
- 表现不好的order原因之一可能是,不够平衡的label估计,总是对某一类label过于自信。
从上面可以看出,表现不好的prompt可能会导致有不平衡的label输出估计。因此,作者提出了一种无监督的评估方法,选择ICL样例的合适排序。
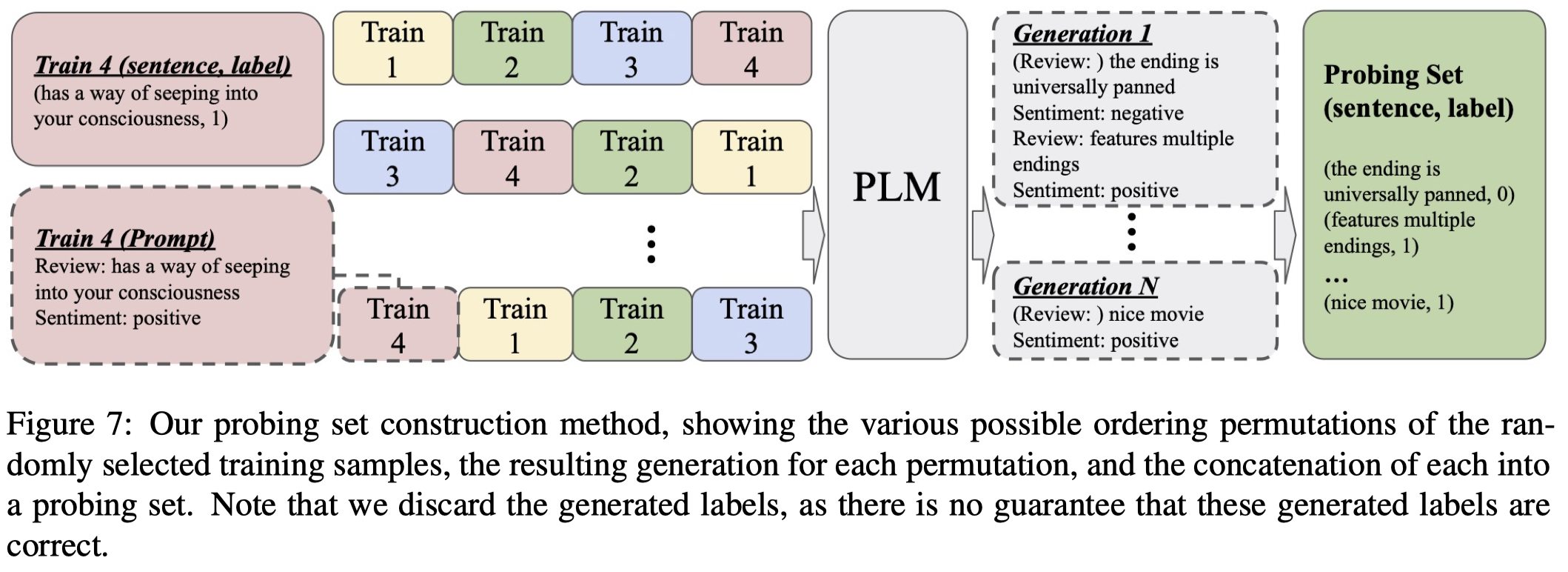
首先,作者根据随机采样得到的样例集合,使用它们的所有可能排列,如有\(n\)个example,那么对应\(n!\)种排列permutations,每个permutation,让LLM生成对应的新的data和label,要注意此时生成的label不能保证是正确的,因此会丢弃。所有生成的sequences作为probing set:
接下来,对于每种可能的排列,作者通过在probing set上计算两种无监督基于熵的指标,来选择合适ordered prompt:
- Global Entropy (GlobalE):avoid the issue of extremely unbalanced predictions. 用LLM计算在给定某种排列顺序的demonstrations之后,对于整个probing set上所有data预测label的分布,如果让这个总体分布熵越小,表示越倾向输出一致/不平衡的label,更有可能出错。
- Local Entropy (LocalE):if a model is overly confident for all probing inputs, then it is likely that the model is not behaving as desired. 分别计算probing data预测label分布的熵,然后平均。
实验结果:
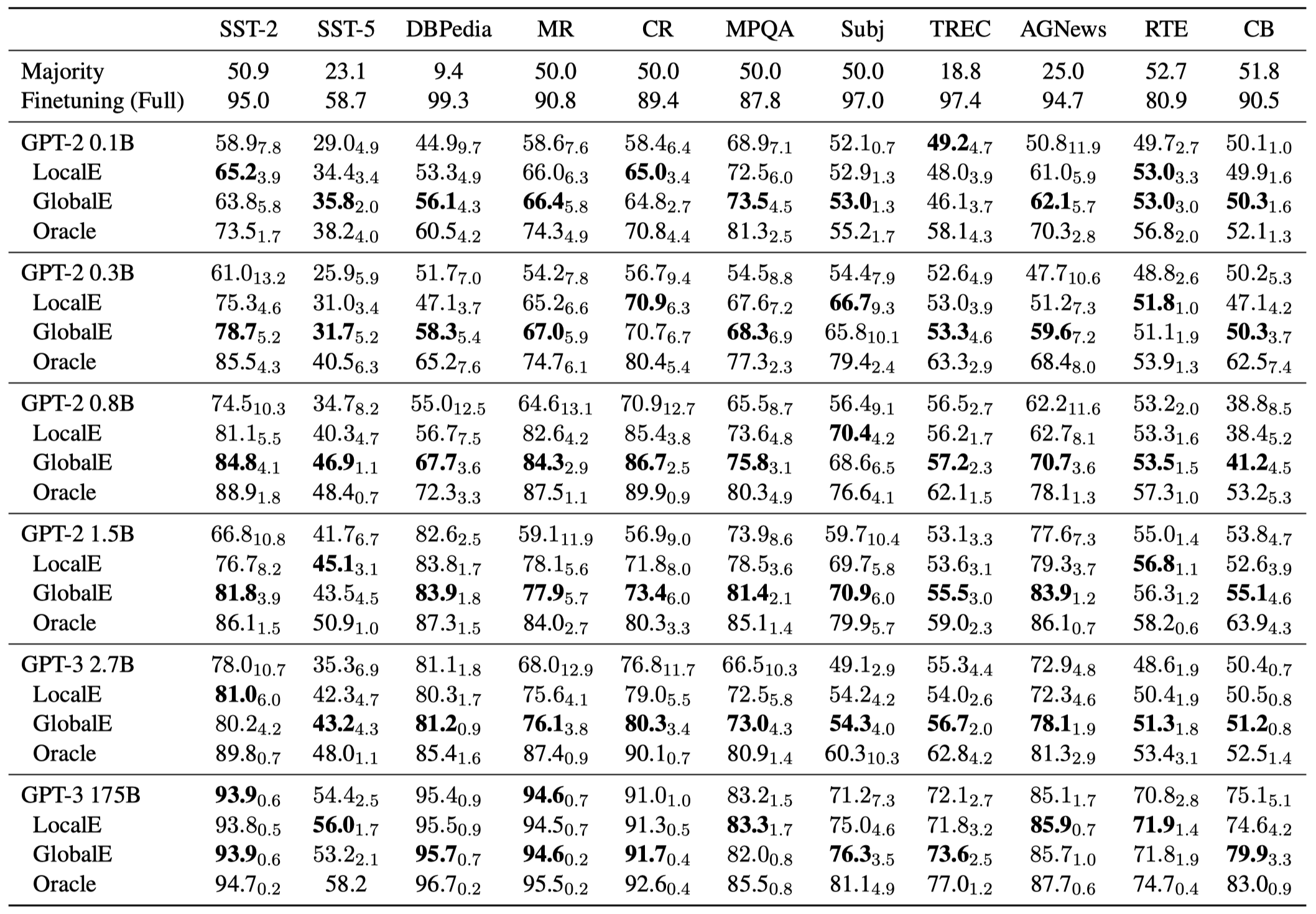
采用GlobalE或LocalE指标能够减小LLM order对于效果的variance。
Rethinking the role of demonstrations
华盛顿大学与Meta,EMNLP 2022,代码。[详细博客]
Large language models (LMs) are able to incontext learn—perform a new task via inference alone by conditioning on a few input-label pairs (demonstrations) and making predictions for new inputs. However, there has been little understanding of how the model learns and which aspects of the demonstrations contribute to end task performance. In this paper, we show that ground truth demonstrations are in fact not required—randomly replacing labels in the demonstrations barely hurts performance on a range of classification and multi-choice tasks, consistently over 12 different models including GPT-3. Instead, we find that other aspects of the demonstrations are the key drivers of end task performance, including the fact that they provide a few examples of (1) the label space, (2) the distribution of the input text, and (3) the overall format of the sequence. Together, our analysis provides a new way of understanding how and why in-context learning works, while opening up new questions about how much can be learned from large language models through inference alone.
作者对于上下文学习中,什么样的signal是对LLM进行task learning有帮助的进行了实验探究。
作者主要针对4个ICL中的demonstrations可能提供的learning signal进行了实验:

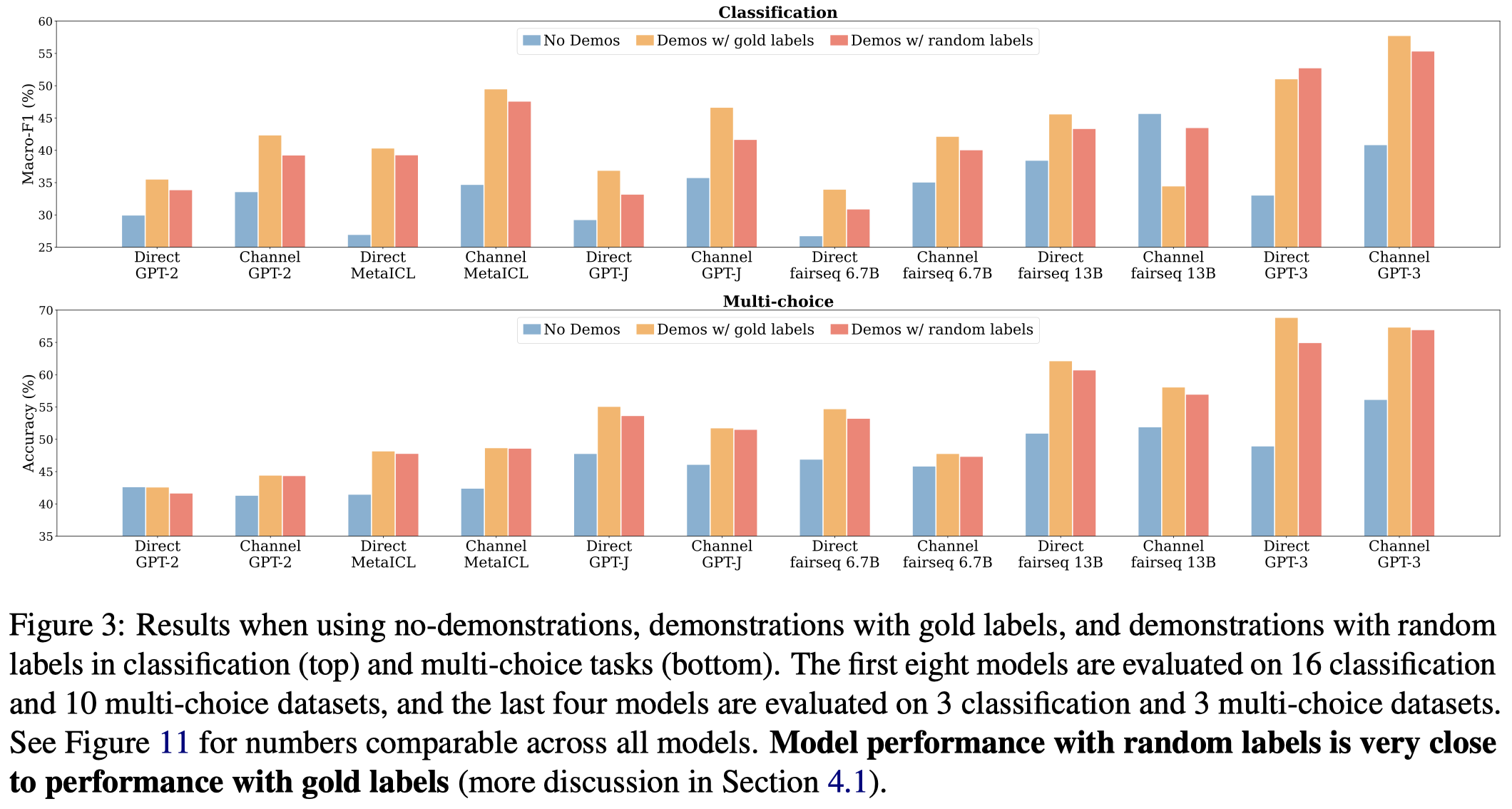
作者的第一个重要发现是ICL中demonstrations的input-label是否正确匹配,对模型效果的影响不大。作者用随机的label来替换demonstrations的ground truth label,发现效果下降不是很多:
Self-adaptive ICL
Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering
Shanghai AI Laboratory和厦门大学,ACL 2023,代码。
Despite the impressive few-shot performance of in-context learning (ICL), it remains a common practice to randomly select examples to serve as the context. In this paper, we advocate self-adaptive in-context learning, a new principle for ICL, in which the self-adaption mechanism is introduced to help each input find an in-context example organization (i.e., selection and permutation) that can derive the correct output, thus maximizing performance. To validate the effectiveness of self-adaptive ICL, we propose a general select-then-rank framework and a set of novel selection and ranking algorithms. Upon extensive evaluation on eight different NLP datasets, our self-adaptive ICL method achieves a 40% relative improvement over the common practice setting. Further analysis reveals the great potential of selfadaptive ICL as a promising method to close the gap between ICL and finetuning. Our code will be released to facilitate future research.
作者提出,针对每个test example进行demonstrations selection,然后进行ranking也就是排列。首先,作者建议有以下的寻找demonstrations的策略:
- TopK:KATE方法和Making pre-trained language models better few-shot learners 工作中提出,选择test sample的nearest neighbors作为demonstrations。
- VoteK:在TopK的策略上,通过惩罚和已选择的样例相似的候选样例,考虑多样性[Selective annotation makes language models better few-shot learners]。
- DPP:作者进一步尝试了determinantal point process (DPP),同样是一种考虑样例多样性的指标[k-dpps: Fixed-size determinantal point processes. ICML 2011]。
为了找合适的样例排列顺序,作者从Solomonoff’s general theory of inference (Solomonoff, 1964)和Minimum Description Length (MDL) principle (Grünwald, 2007)出发,倾向于选择能够无损压缩test sample的demonstrations:
We assume that a good organization of in-context examples is the organization that is good at losslessly compressing testing samples.
换句话说,无损的压缩test sample,意味着可以从demonstrations中,正确的推导出test sample对应的label:
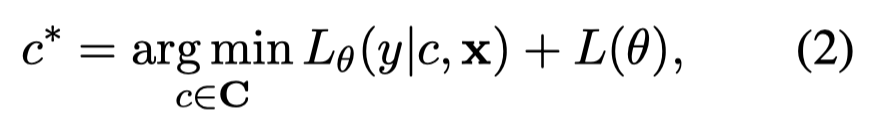
其中\(c\)表示某种demonstrations组织。\(L_{\theta}(y | c, x)\)是指在给定样例\(c\)和test input \(x\),能够真正压缩与还原test label \(y\)的codelength。\(L(\theta)\)是指描述model本身所需的codelength,对于所有的候选demonstrations是一样的,因此可以忽略。
上述公式定义最佳的demonstrations应该使无损压缩test sample所需的codelength最短。
使用Shannon-Huffman code来计算进行data transmission的codelength:

但是test label \(y\)在实际中是未知的,因此作者使用codelength的期望来代替:
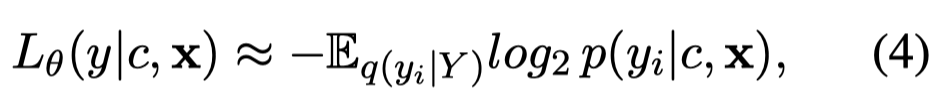
其中\(q(y_i | Y)\)是test label \(y\)的先验分布,对于每个test sample来说可能是不一样的,因此作者再次使用model进行估计:
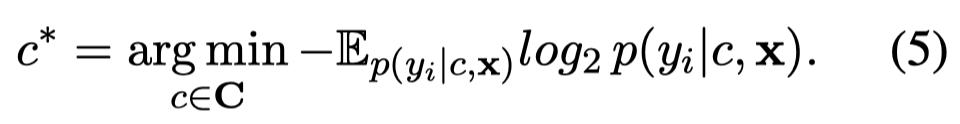
现在,从理论上,对于每个排列\(c\),我们都可以计算出一个无监督的metric来进行选择;但是由于作者的demonstrations是instance-level的,潜在的排序数量仍然过多,不可能真正的计算一遍所有的候选排序。因此,作者实际上只是在对应的\(K=8\)采样集合中,随机采样\(10\)种排列,然后进行ranking。
对于最终的公式5,此时作者是在计算熵,也就是寻找熵最小的情况,寻找让LLM的预测分布非常confident的demonstrations。这和上面Effect of ordered examples工作中提出的GlobalE和LocalE的思想是相反的。
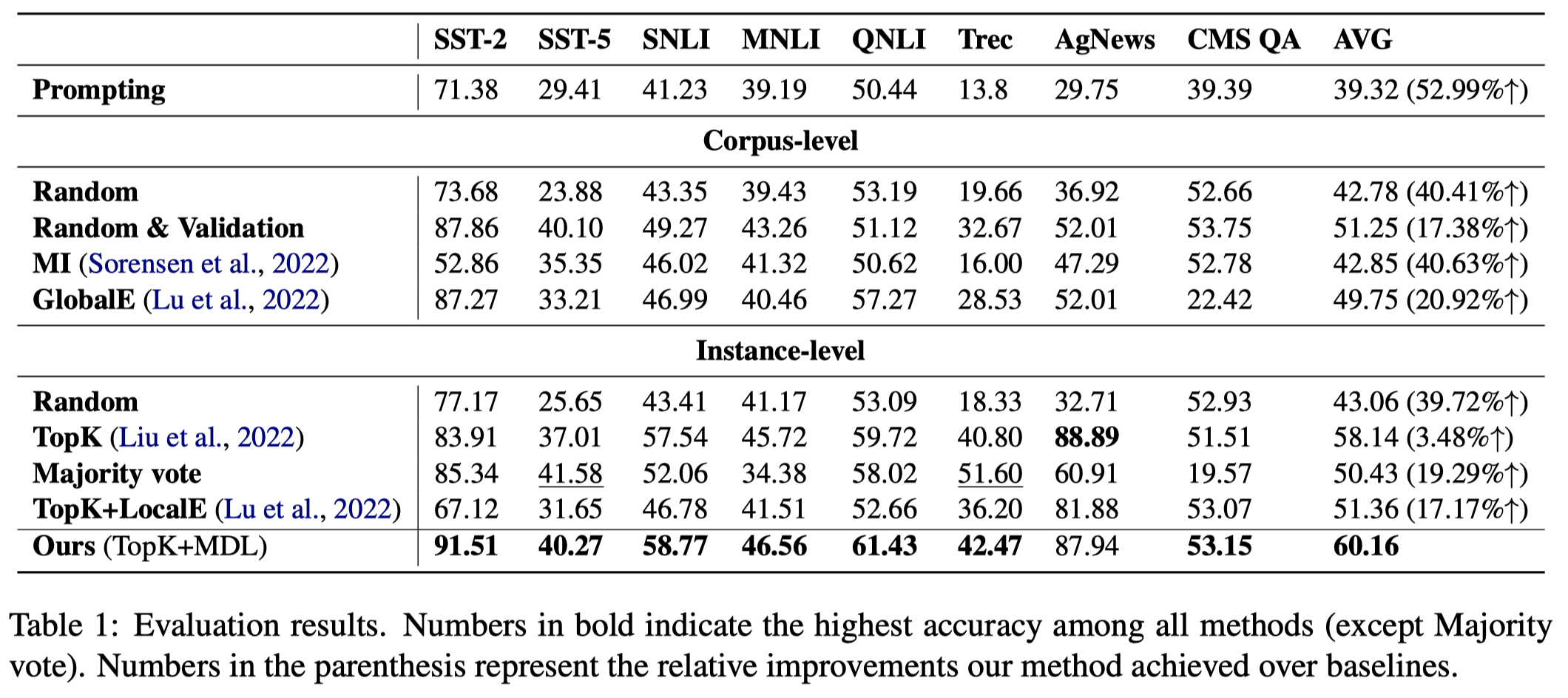
观察:
- 使用TopK选择demonstrations,然后使用MDL进行ranking取得了最好的结果
- TopK的instance-level的ICL策略,已经在大多数据集上优于corpus-level的ICL策略
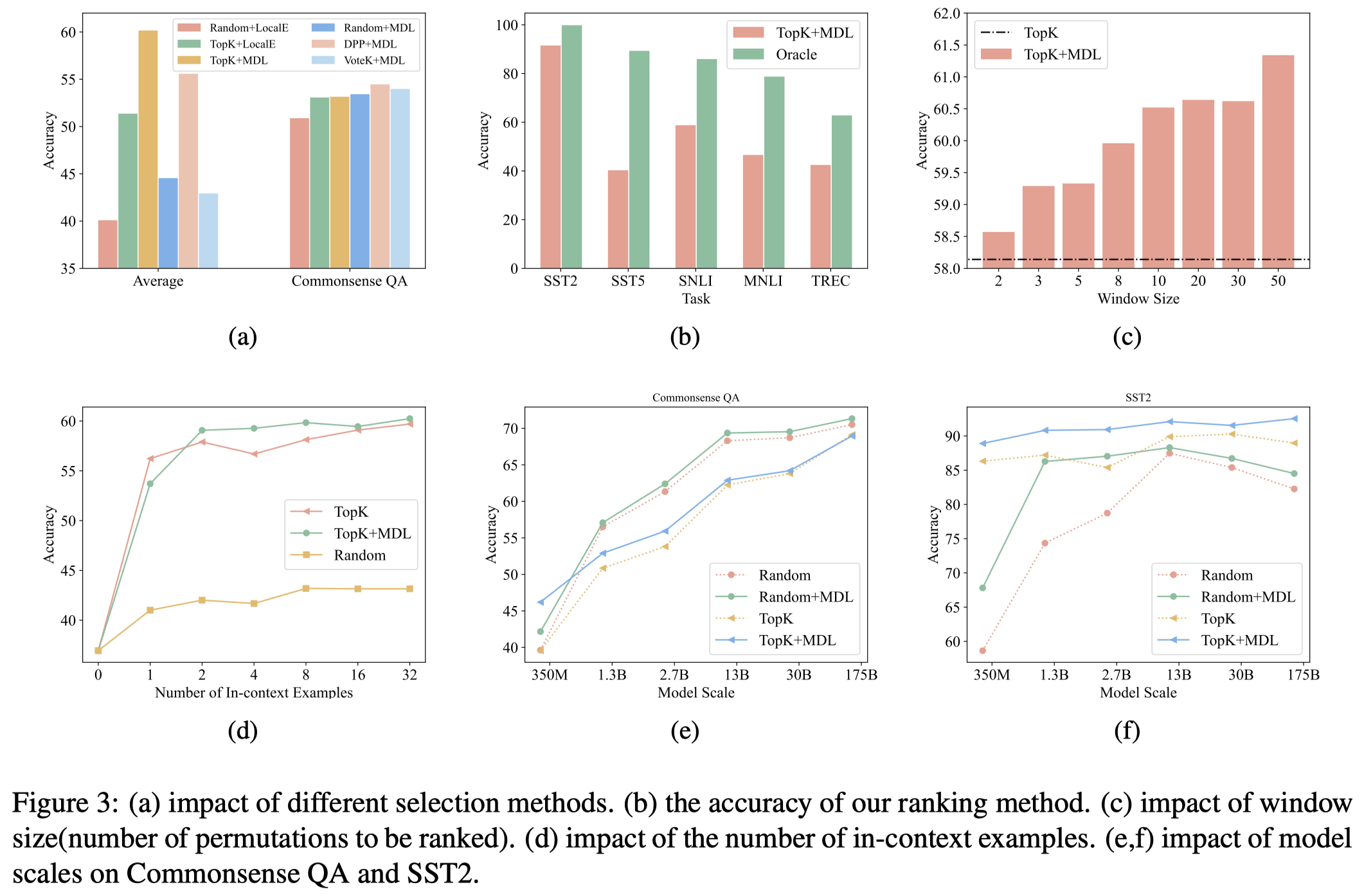
观察:
- 不同任务下需要selection偏好不同。在分类任务下,使用TopK策略取得了最好的效果,在QA任务下,使用VoteK等考虑多样性的策略效果更好。
UDR
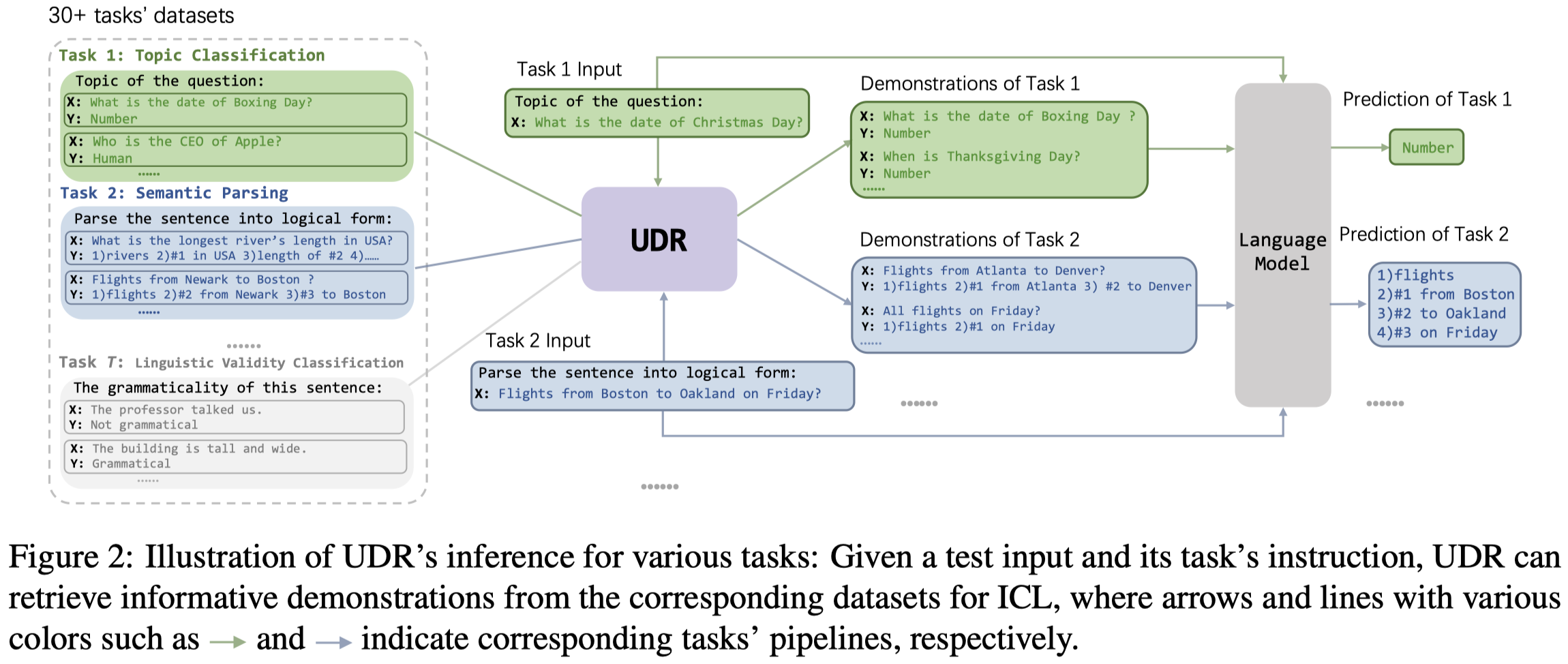
Unified Demonstration Retriever for In-Context Learning
复旦,ACL 2023,代码。
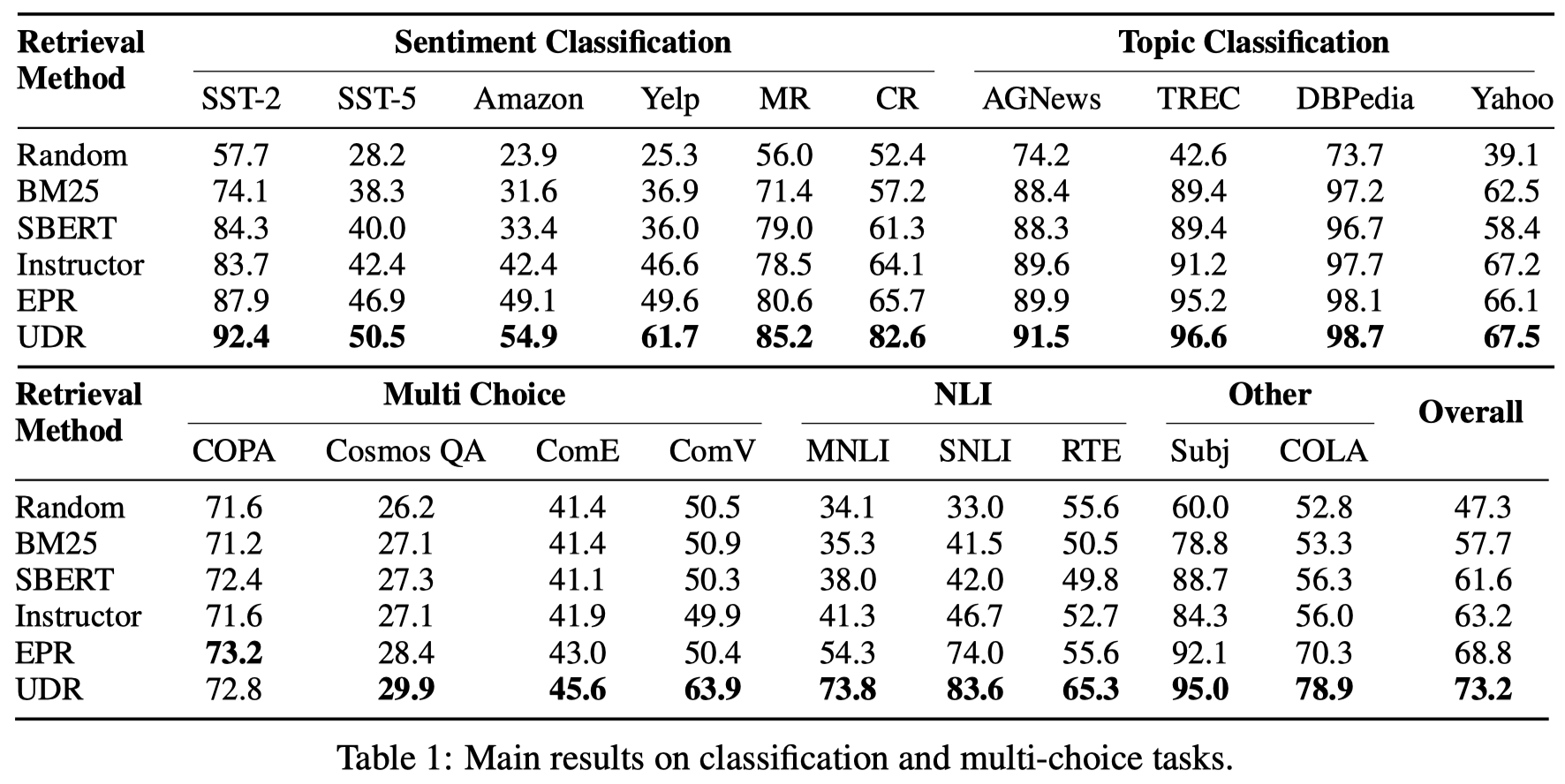
In-context learning is a new learning paradigm where a language model conditions on a few input-output pairs (demonstrations) and a test input, and directly outputs the prediction. It has been shown highly dependent on the provided demonstrations and thus promotes the research of demonstration retrieval: given a test input, relevant examples are retrieved from the training set to serve as informative demonstrations for in-context learning. While previous works focus on training task-specific retrievers for several tasks separately, these methods are often hard to transfer and scale on various tasks, and separately trained retrievers incur a lot of parameter storage and deployment cost. In this paper, we propose Unified Demonstration Retriever (UDR), a single model to retrieve demonstrations for a wide range of tasks. To train UDR, we cast various tasks’ training signals into a unified list-wise ranking formulation by language model’s feedback. Then we propose a multi-task list-wise ranking training framework, with an iterative mining strategy to find high-quality candidates, which can help UDR fully incorporate various tasks’ signals. Experiments on 30+ tasks across 13 task families and multiple data domains show that UDR significantly outperforms baselines. Further analyses show the effectiveness of each proposed component and UDR’s strong ability in various scenarios including different LMs (1.3B ∼ 175B), unseen datasets, varying demonstration quantities, etc.
目前对于ICL进行demonstrations选择的方法有两类:
- 无监督的:比如使用BM25或者SBERT等embedding进行相似度计算
- 有监督的:针对特定task,在某种ranking的监督信号下,训练一个demonstration retriever
作者期望解决的问题是,能够设计一种适用于不同task的Demonstration Retriever。
作者提出的方法:
首先,作者计算query sample和candidate example的方式是基于dense passage retriever (DPR) [Dense passage retrieval for open-domain question answering. EMNLP 20]的思路。也就是使用encoder,将query example \(x\)和candidate example \(z\)分别进行编码,然后计算相似度:
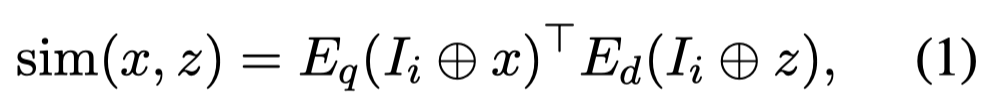
为了能够辨别来自不同task的example,编码的时候会将task instruction \(I\)和example一起进行编码。
实现中,作者使用BERT-base来编码。
然后,作者的ranking signal来自LM本身的conditional probability,继承于之前的的工作EPR的思想:
This indicates how helpful this candidate is for decoding the target (independent of all other candidates).
公式:

其中\(G\)代表LLM,\(z_j\)是某个candidate example,\(s_{gen}\)和\(s_{cls}\)分别代表生成任务和分类任务下,加入example \(z_j\)后LM对query \(x\)输出正确\(y\)的概率。\(r(z_j)\)代表\(z_j\)在所有candidate examples中的rank。
作者期望通过相似度计算的retriever对于candidate examples的排序结果,能够靠近LM基于条件概率的排序结果,作者引入了两种loss:
LambdaRank loss [From RankNet to LambdaRank to LambdaMART: An overview. 2010]:其中\(w\)是一个根据不同pair \(z_i,z_j\)动态调整的值
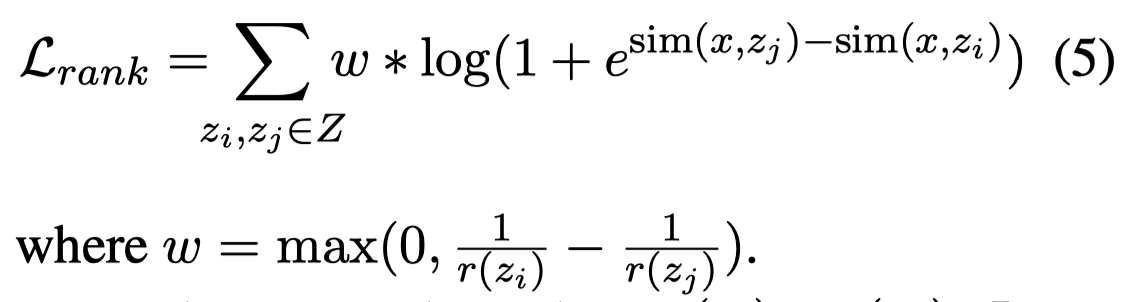
in-batch negative loss:让rank 1的example \(z^{*}\)应该在所有可能的examples中和\(x\)是最相似的
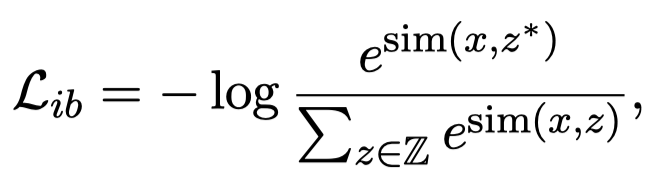
最后,为了保证效率,在训练阶段,使用迭代的采样策略;最后在推理时,基于FAISS [Billion-scale similarity search with gpus. 2021]使用基于相似度的计算来寻找demonstrations(考虑到如果在推理阶段,使用LM来ranking的巨大代价)。
实验结果(基于GPT-Neo-2.7B作为LM):
Cover-LS
Diverse Demonstrations Improve In-context Compositional Generalization
ACL 2023,代码。
In-context learning has shown great success in i.i.d semantic parsing splits, where the training and test sets are drawn from the same distribution. In this setup, models are typically prompted with demonstrations that are similar to the input utterance. However, in the setup of compositional generalization, where models are tested on outputs with structures that are absent from the training set, selecting similar demonstrations is insufficient, as often no example will be similar enough to the input. In this work, we propose a method to select diverse demonstrations that aims to collectively cover all of the structures required in the output program, in order to encourage the model to generalize to new structures from these demonstrations. We empirically show that combining diverse demonstrations with in-context learning substantially improves performance across three compositional generalization semantic parsing datasets in the pure in-context learning setup and when combined with fine-tuning.
作者针对的是Compositional generalization问题。在组合泛化中,仅仅寻找和query example相似的单个example是不够的,需要考虑更加多样diverse的examples set来提供足够的信息。
Follow前人的工作[Unobserved local structures make compositional generalization hard. 2022],作者定义的example的多样性体现在example的local structures。local structures是指Compositional generalization问题的答案program对应的抽象语法树的各个子图:

作者期望找到的demonstrations一方面能够尽可能和query example相似;一方面能够有更多样的local structures去覆盖query example的predicted local structures。作者训练T5-large来针对query example输出local structures,而不是whole program。这样能够减低预测的难度。
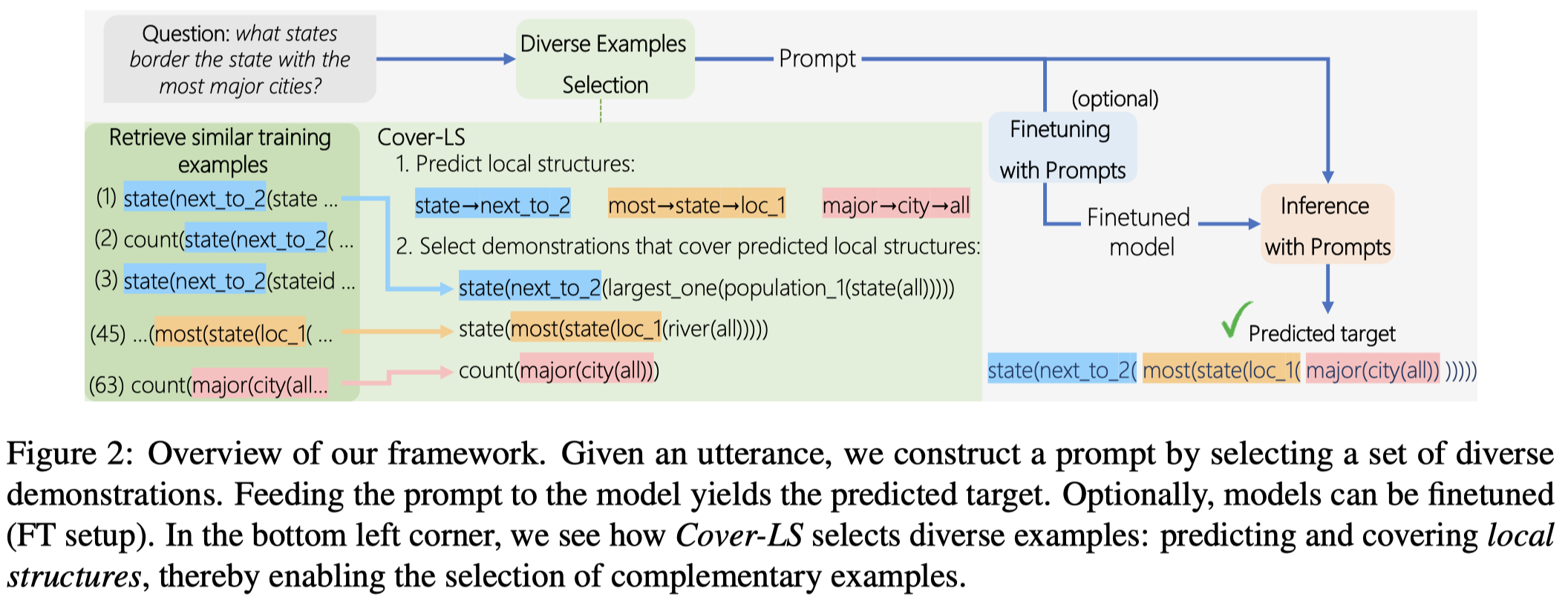
在找demonstrations时:
- 作者先对T5-large预测的query example的local structures根据长度进行降序排列;这一思想和前人的工作[Generate-and-Retrieve: Use Your Predictions to Improve Retrieval for Semantic Parsing. COLING 2022]一致,先进行preliminary prediction,然后基于preliminary prediction再进行检索;
- 然后迭代的选择当前最长的local structure,寻找training set里覆盖了当前local structure中,和query example最相似的example。相似度的计算可以基于BM25或者SBERT;
- 最后,移除和已经选择的example的program一样的其它候选examples,继续进行选择;直至达到上限。
找到的demonstrations不仅可以辅助与LLM的ICL,作者还直接用来fine-tuning一个SLM(同样是基于T5-large)。
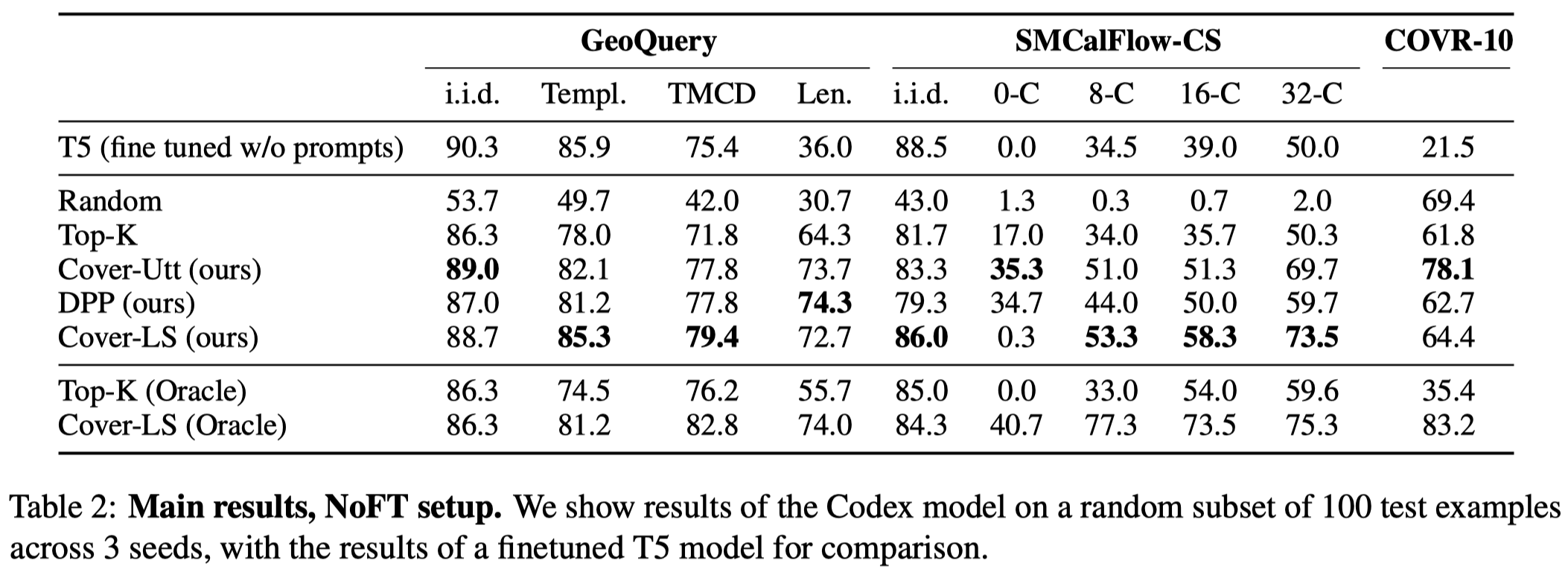
实验结果(LLM基于code-davinci-002):
(相关工作里有一些寻找多样example的paper,只不过并非是为prompt设计的)
Mutual information
An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
ACL 2022,代码。
Pre-trained language models derive substantial linguistic and factual knowledge from the massive corpora on which they are trained, and prompt engineering seeks to align these models to specific tasks. Unfortunately, existing prompt engineering methods require significant amounts of labeled data, access to model parameters, or both. We introduce a new method for selecting prompt templates without labeled examples and without direct access to the model. Specifically, over a set of candidate templates, we choose the template that maximizes the mutual information between the input and the corresponding model output. Across 8 datasets representing 7 distinct NLP tasks, we show that when a template has high mutual information, it also has high accuracy on the task. On the largest model, selecting prompts with our method gets 90% of the way from the average prompt accuracy to the best prompt accuracy and requires no ground truth labels.
这篇属于评价哪个prompt template/ICL formatting比较好的工作,适用于任何分类的NLP任务,并且只要各个分类的开头token是独一无二的。
LLM的prompt是指:
“prompt” refers to any language passed to the model via the context window.
prompt的template可以理解为待填充的prompt,用来构建prompt:
a template refers to a natural language scaffolding filled in with raw data, resulting in a prompt.
prompt template的好坏能够极大的影响LLM的task performance,一种最general的找最好的template的思路是通过在validation set上进行评估,但这要求有提前的labeled set。
作者的方法是可以在不需要ground truth label的情况下,通过计算不同templates和LLM输出结果的mutual information来找合适的template:
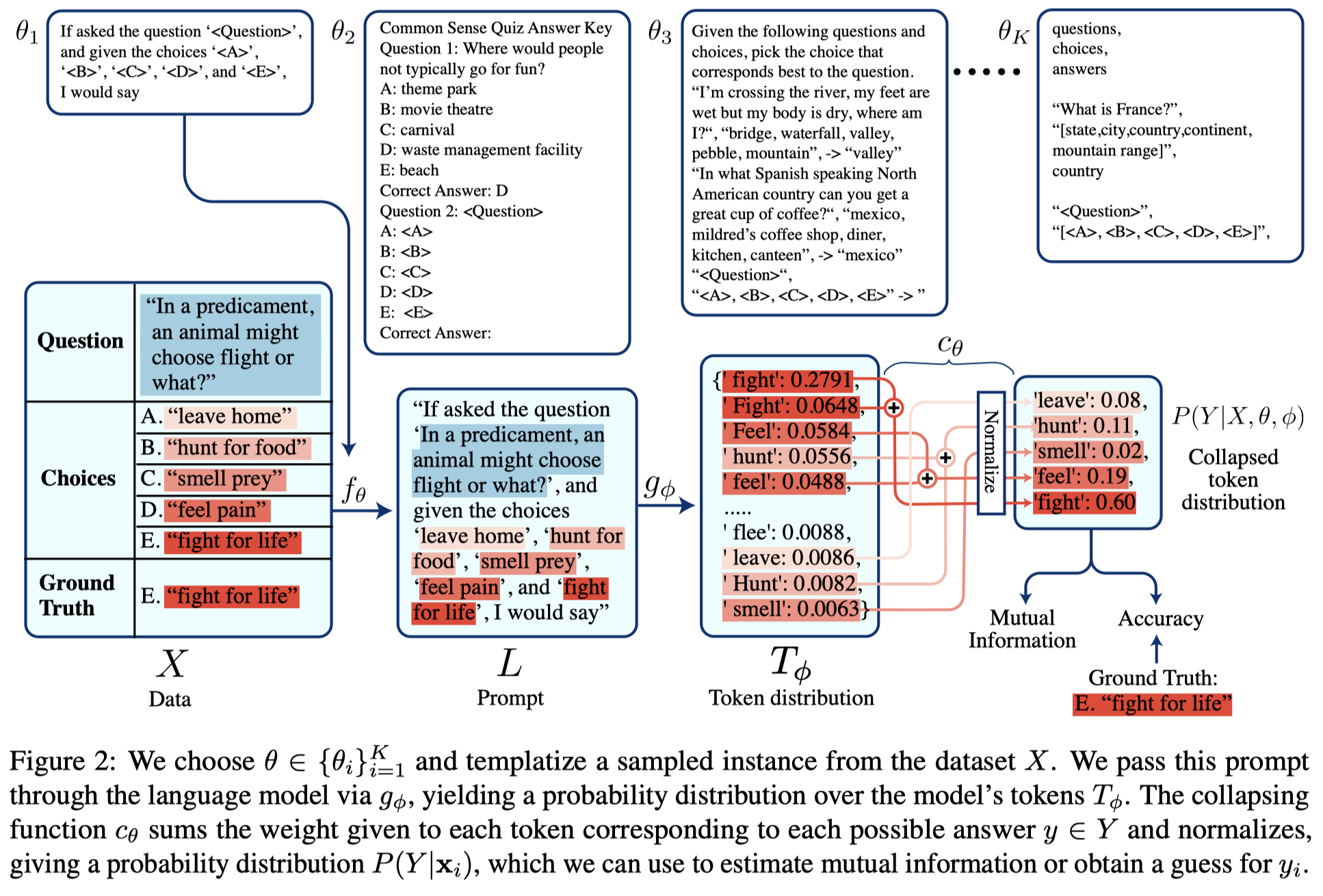
步骤:
- 人工设计\(K\)个prompt template,然后用几个samples测试下template,排除或者修改那些无法将对应label最开头的token输出在前几位的templates;
- 针对每个template,采样数据,填充template,创建测试数据;
- 对于输出结果,将不同label对应的开头token的权重重新归一化。计算mutual information,选择最大互信息的template;
什么是互信息:
Mutual information is a measure of the amount of shared information between two random variables (Cover and Thomas, 2006); in other words, it is the reduction in entropy that is observed in one random variable when the other random variable is known.
假定templates \(f_{\theta}(X)=\{f_{\theta}(x)\}\)是random variable,\(Y\)是labels,计算mutual information \(I(f_{\theta(X)};Y)=D_{KL}(P_{(f_{\theta(X)},Y)}||P_{f_{\theta}} \otimes P_Y)\),进一步化简为:
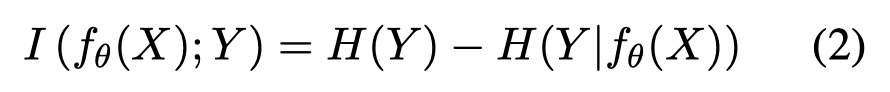
使用下面的采样期望进行估计:
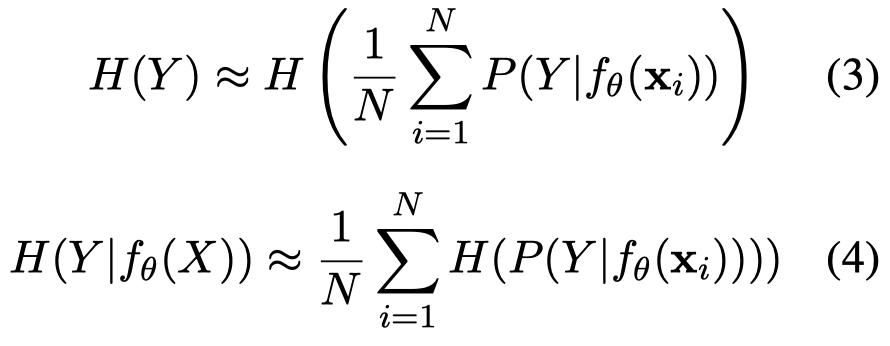
\(H(\cdot)\)代表熵。作者认为更高的mutual information更好,代表采用该template之后,熵减小的更多。
如何理解一个template有更大的互信息就更好?
根据上面的公式2,最大化互信息,意味着最大化\(H(Y)\)和最小化\(H(Y|f_{\theta}(X))\)。也就是一个更好的template,对原始的label有更少的bias(更uniform,不潜在的偏好某种label);同时该template倾向于输出更confident的label probability
从data processing inequality [Elements of Information Theory 2nd Edition (Wiley Series in Telecommunications and Signal Processing) 2006]的角度分析,\(I(f_{\theta(X)};Y) \leq I(X;Y)\),也就是说\(I(f_{\theta(X)};Y)\)是\(I(X;Y)\)的lower bound。更大的\(I(f_{\theta(X)};Y)\)意味着更tight的lower bound,因此保留了\(X\)和\(Y\)之间更多的信息