IE-Collection2
信息抽取论文调研集合2。
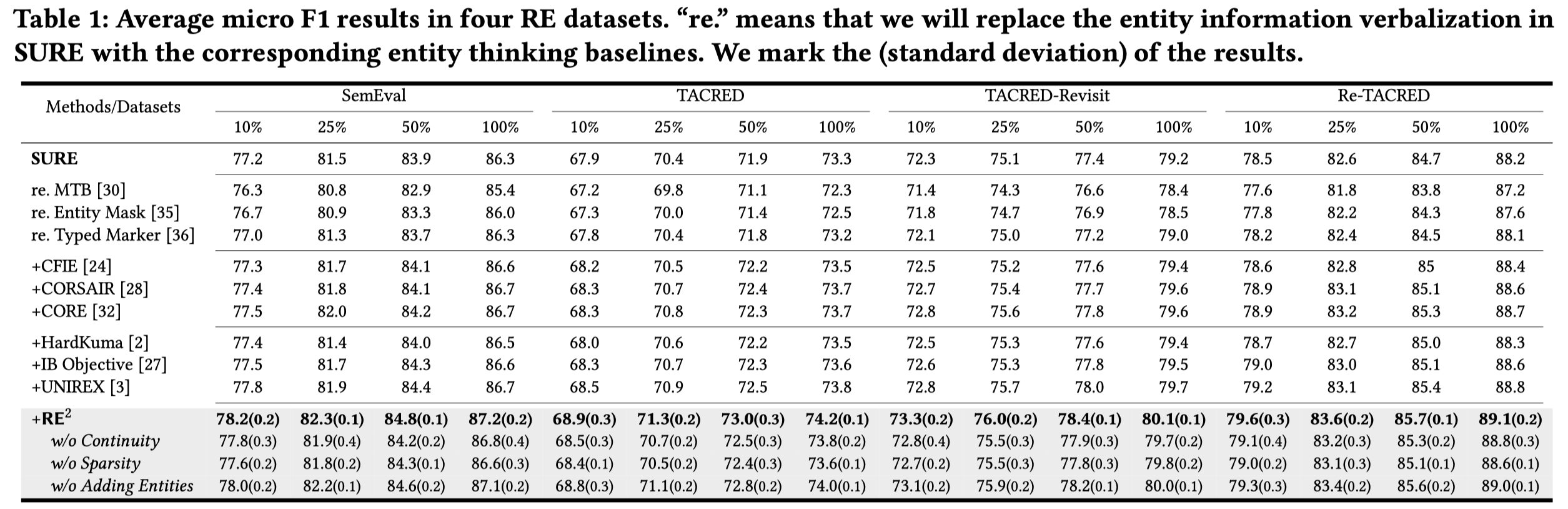
RE^2
Think Rationally about What You See: Continuous Rationale Extraction for Relation Extraction. SIGIR 2022. 清华. 代码.
Relation extraction (RE) aims to extract potential relations according to the context of two entities, thus, deriving rational contexts from sentences plays an important role. Previous works either focus on how to leverage the entity information (e.g., entity types, entity verbalization) to inference relations, but ignore context-focused content, or use counterfactual thinking to remove the model’s bias of potential relations in entities, but the relation reasoning process will still be hindered by irrelevant content. Therefore, how to preserve relevant content and remove noisy segments from sentences is a crucial task. In addition, retained content needs to be fluent enough to maintain semantic coherence and interpretability. In this work, we propose a novel rationale extraction framework named RE 2 , which leverages two continuity and sparsity factors to obtain relevant and coherent rationales from sentences. To solve the problem that the gold rationales are not labeled, RE 2 applies an optimizable binary mask to each token in the sentence, and adjust the rationales that need to be selected according to the relation label. Experiments on four datasets show that RE 2 surpasses baselines.
Issue: 作者认为之前的寻找RE任务的rationales(即什么样的信息对RE model进行预测是有意义的)有两种,但是都无法显式地去除输入的text中的noisy context。entity thinking方法是只关注entity相关信息;counter-factual thinking移除model bias。两种方法都无法explicitly remove noisy contextual context:
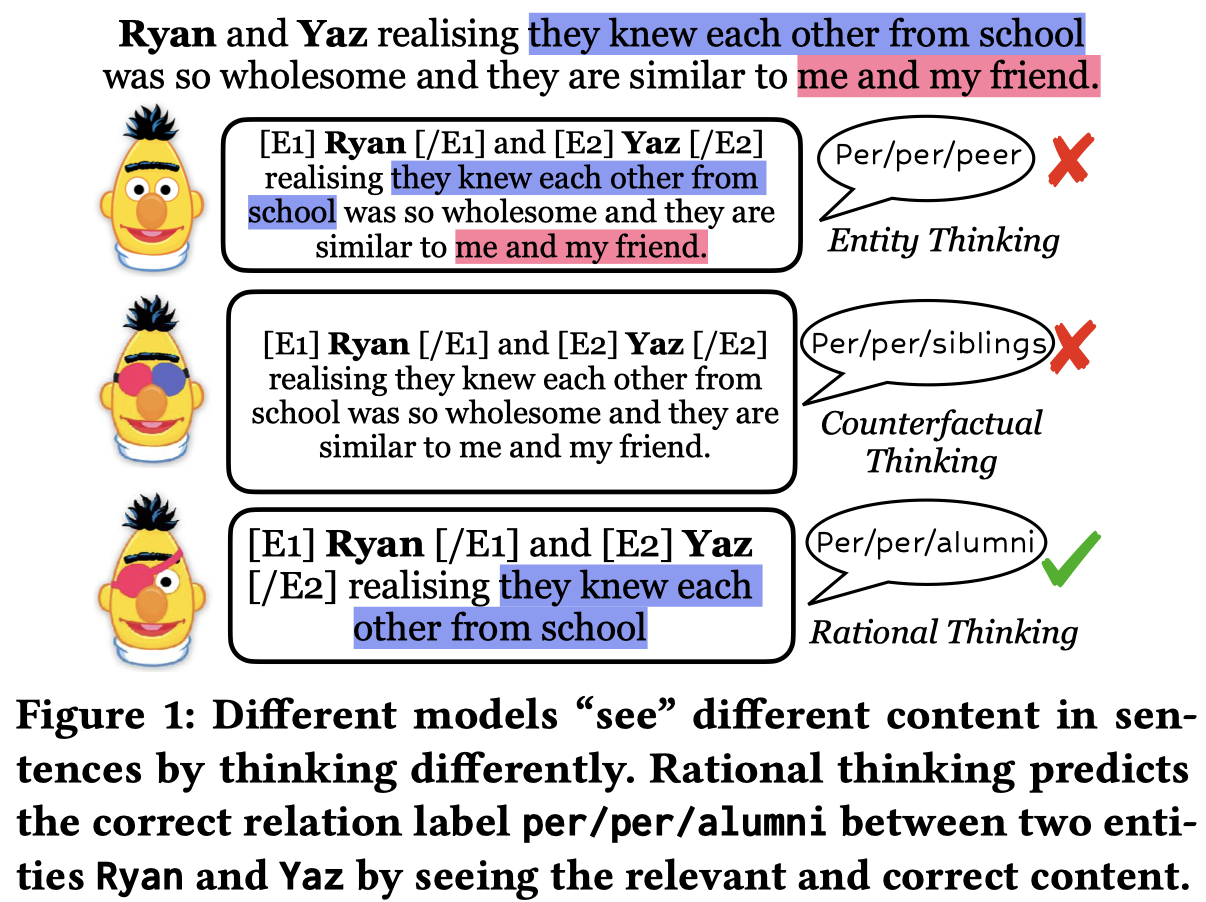
Solution: 作者提出了一种从稀疏性和连贯性两个角度选择有意义的context token的方法。
稀疏性控制有多少context被保留下来; 连贯性保证保留的context语义是连续的,这样可以提高最后保留的context的可解释性;
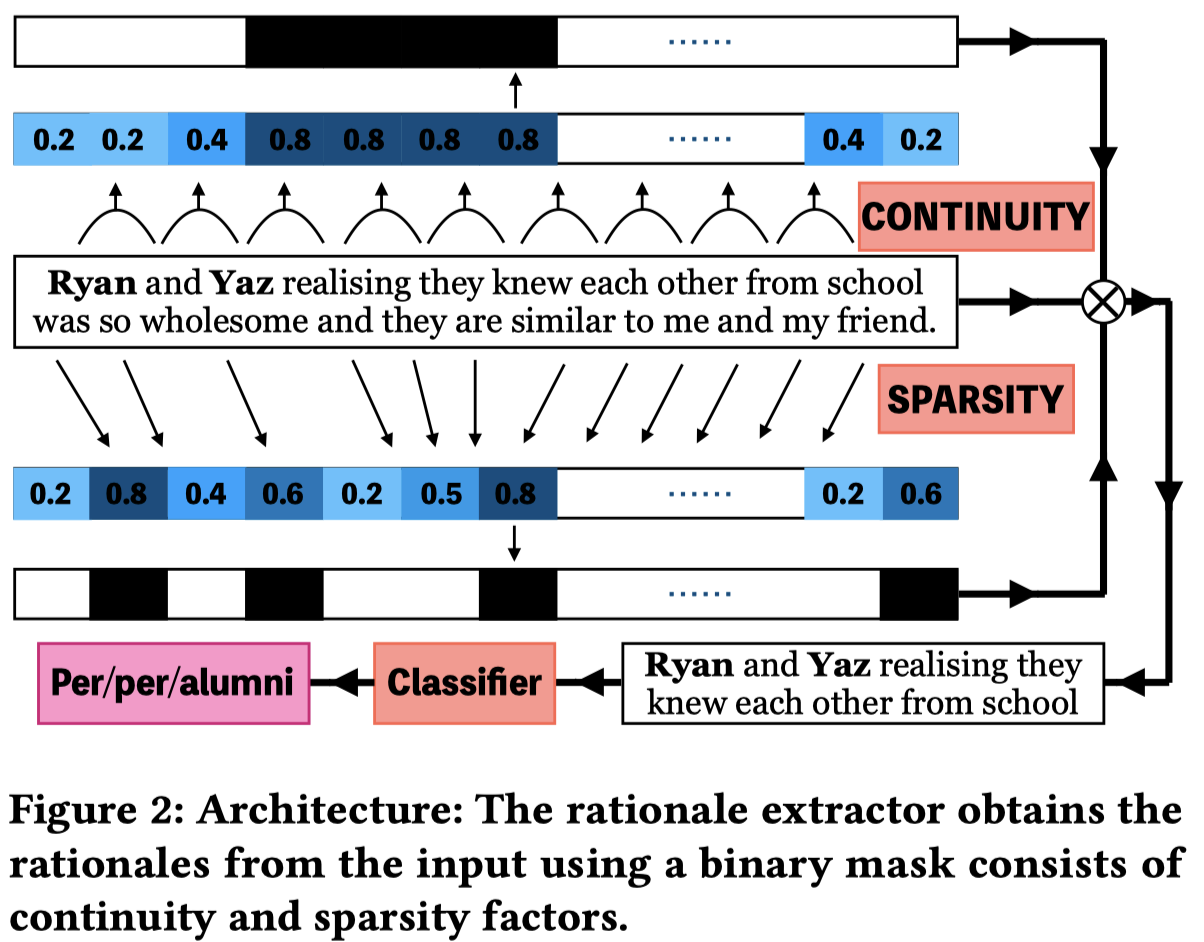
作者首先通过每个token embedding分别和头尾entity embedding相乘,作为importance matrix:
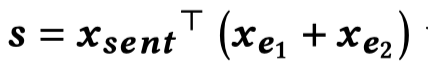
然后,为了评估连贯性,作者需要前后两个token都被选择:

式子中的\(m_i,m_{i+1}\)取值为\(0\)或\(1\)表示是否选择该token,\(r_{i,i+1}\)表示edge score。
评估稀疏性,是通过控制最大可以被保留下来的context token数量,如果数量超过了阈值\(K\)(默认60%),那么就是负无穷:
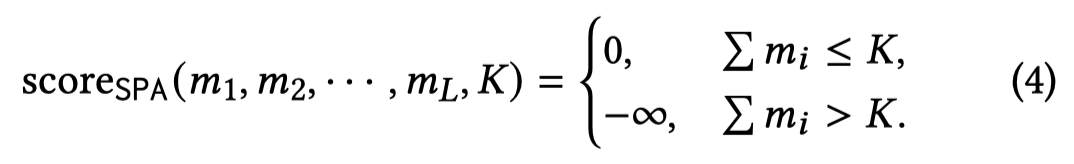
最终,两个score相加,优化目标(越大越好)就变为了一个有约束的优化问题:
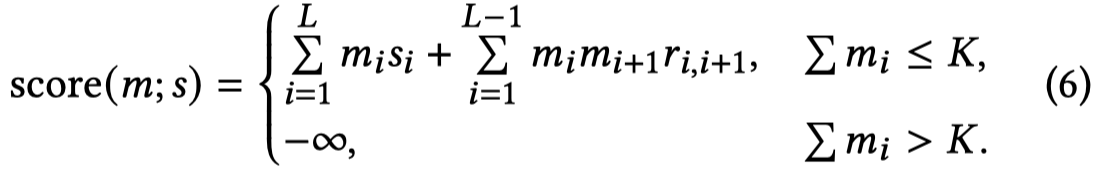
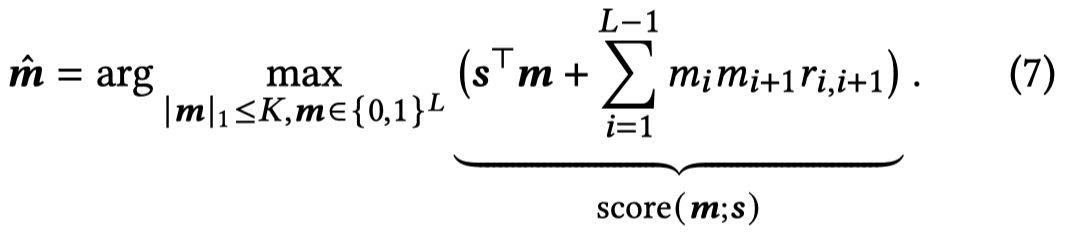
为了求解这一问题,作者使用Lagrange Multiplier,具体参考论文。
作者的方法以SURE作为base model:
RARE
From What to Why: Improving Relation Extraction with Rationale Graph. 中科院. ACL 2021 findings.
Which type of information affects the existing neural relation extraction (RE) models to make correct decisions is an important question. In this paper, we observe that entity type and trigger are the most indicative information for RE in each instance. Moreover, these indicative clues are always constrained to co-occur with specific relations at the corpus level. Motivated by this, we propose a novel RAtionale Graph (RAG) to organize such co-occurrence constraints among entity types, triggers and relations in a holistic graph view. By introducing two subtasks of entity type prediction and trigger labeling, we build the connection between each instance and RAG, and then leverage relevant global co-occurrence knowledge stored in the graph to improve the performance of neural RE models. Extensive experimental results indicate that our method outperforms strong baselines significantly and achieves state-of-the-art performance on the document-level and sentence-level RE benchmarks.
对于RE任务来说,什么样的信息是重要的。之前的一篇研究[Learning from context or names? an empirical study on neural relation extraction. EMNLP 2021]发现,entity type和textual context总是重要的。实体type总是对于RE任务重要的,另外,textual context中包括了一些indicative word span,Yu et al. (2020) [Dialogue-based relation extraction. ACL 2020]将其称为triggers,也是重要的。

作者认为,可以通过总结全局视角下,特定关系对应的,常出现的entity type和triggers,作为先验知识,来辅助关系抽取。并且其可以作为用来解释为什么输出label的依据。
下面是作者构造的一个基于共现频率,统计出来的全局RAtionale Graph (RAG)图:
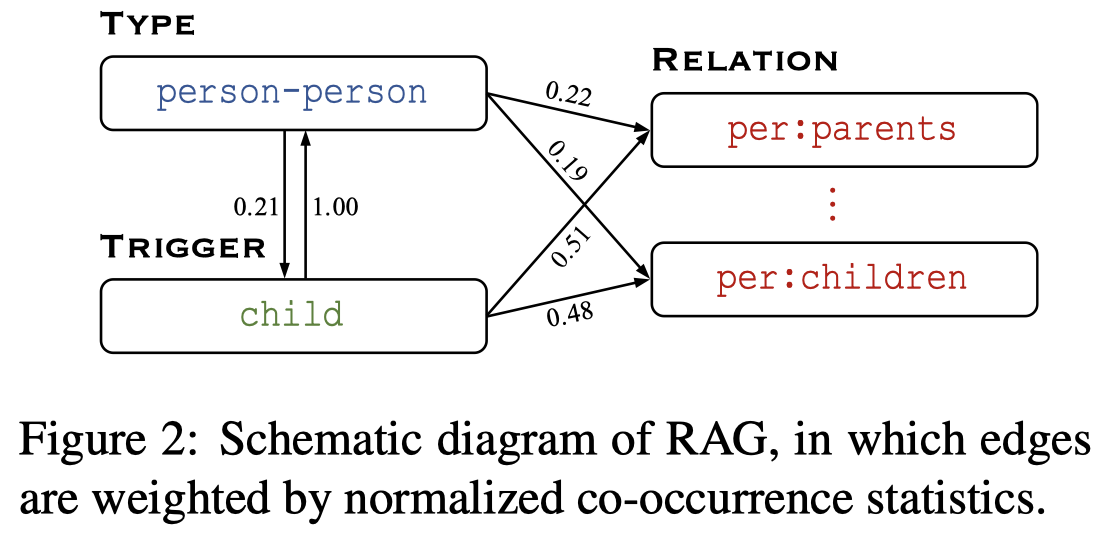
作者方法不仅仅会判别relation type,还会预测entity type以及检测触发词。
作者在文档级信息抽取数据集DialogRE和句子级别关系抽取数据集TACRED/TACREV进行了实验。下面是一个case study:
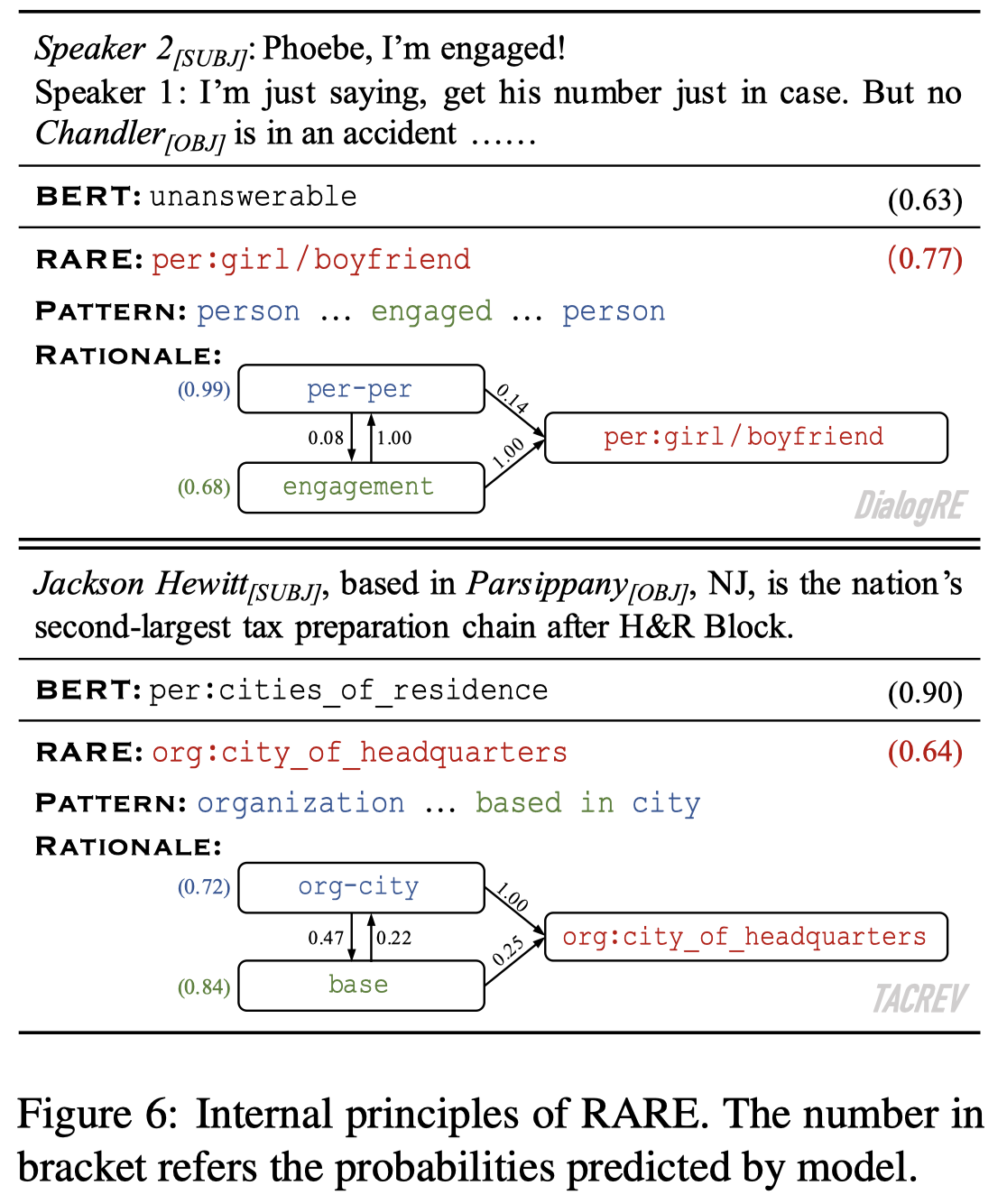
Riedel et al.
Relation Extraction with Matrix Factorization and Universal Schemas. University College London. NAACL 2012
Traditional relation extraction predicts relations within some fixed and finite target schema. Machine learning approaches to this task require either manual annotation or, in the case of distant supervision, existing structured sources of the same schema. The need for existing datasets can be avoided by using a universal schema: the union of all involved schemas (surface form predicates as in OpenIE, and relations in the schemas of preexisting databases). This schema has an almost unlimited set of relations (due to surface forms), and supports integration with existing structured data (through the relation types of existing databases). To populate a database of such schema we present matrix factorization models that learn latent feature vectors for entity tuples and relations. We show that such latent models achieve substantially higher accuracy than a traditional classification approach. More importantly, by operating simultaneously on relations observed in text and in pre-existing structured DBs such as Freebase, we are able to reason about unstructured and structured data in mutually-supporting ways. By doing so our approach outperforms state-of-the-art distant supervision.
Issue:作者认为利用现有的两种RE任务schema来拓展KB都存在问题:
- 使用predefined的schema进行标注是time-consuming的
- 另一种可能避免使用提前定义好的schema的策略是OpenIE。OpenIE的schema来自于输入的text本身,即观察到的entities之间的surface patterns被利用作为relation
Solution: 作者提出一种联合的schema,能够同时建模surface pattern的schema以及pre-defined schema。
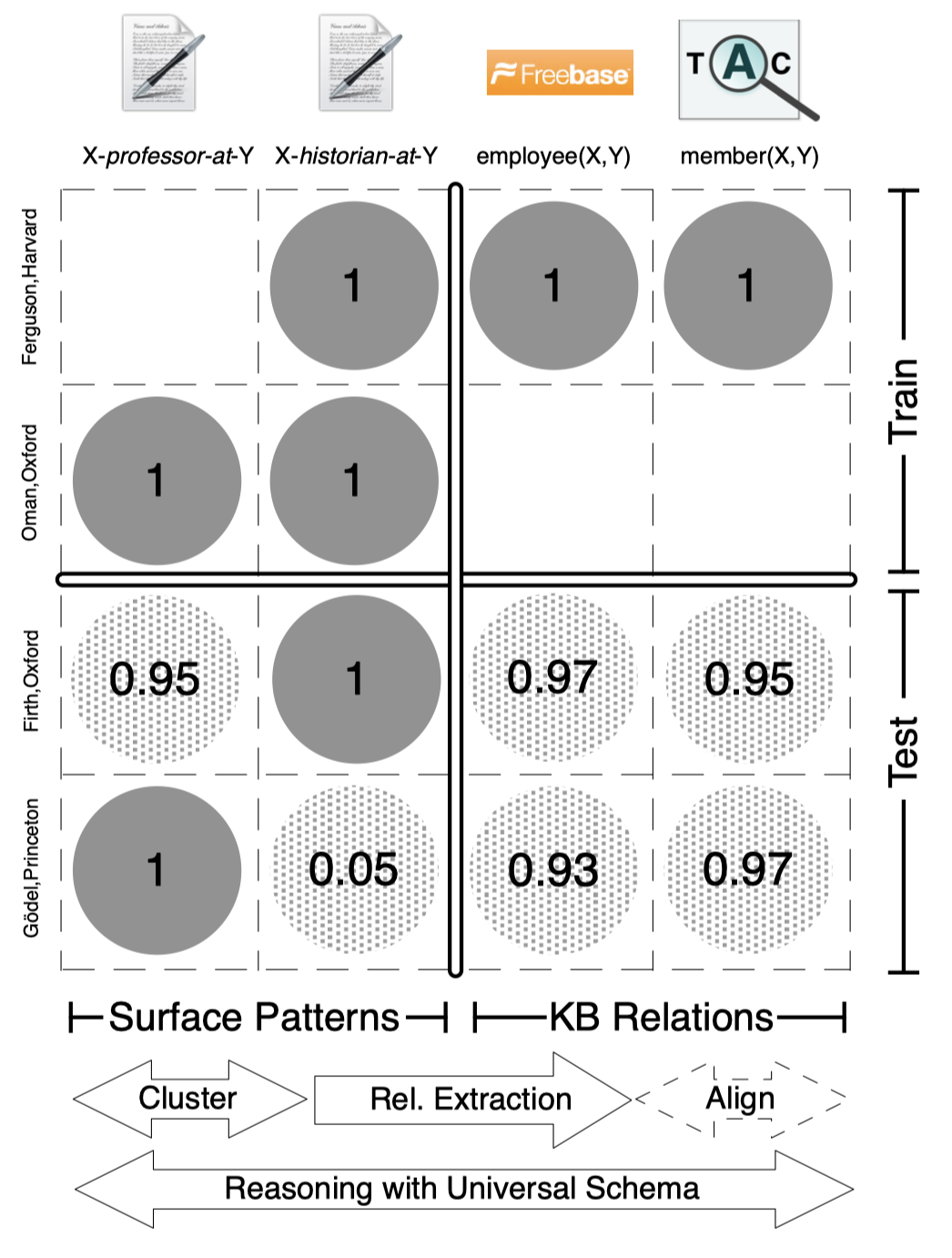
上图中的行是头尾实体对,列是relation label。获得这样的矩阵之后,作者通过矩阵分解的方法,获得隐式的表示,从而可以推导出没有被观测到的隐含的relation。
作者期望,能够根据surface pattern,来对应的提前定义的pre-defined pattern。
作者对于predefined schema的思考,任何提前定义的relational schema都脆弱的,存在模糊语义、错误定义的边界case以及不完备性:
In fact, we contend that any relational schema would inherently be brittle and ill-defined––having ambiguities, problematic boundary cases, and incompleteness.
At NAACL 2012 Lucy Vanderwende asked “Where do the relation types come from?” There was no satisfying answer. At the same meeting, and in line with Brachman (1983), Ed Hovy stated “We don’t even know what is-a means.”
所谓的surface pattern relation,在作者的实验中,就是指语法上的依赖路径作为surface pattern relation。lexicalized dependency path \(p\) between entity mentions。
For example, we get “<-subj<-head->obj->” for “M1 heads M2.”
NERO
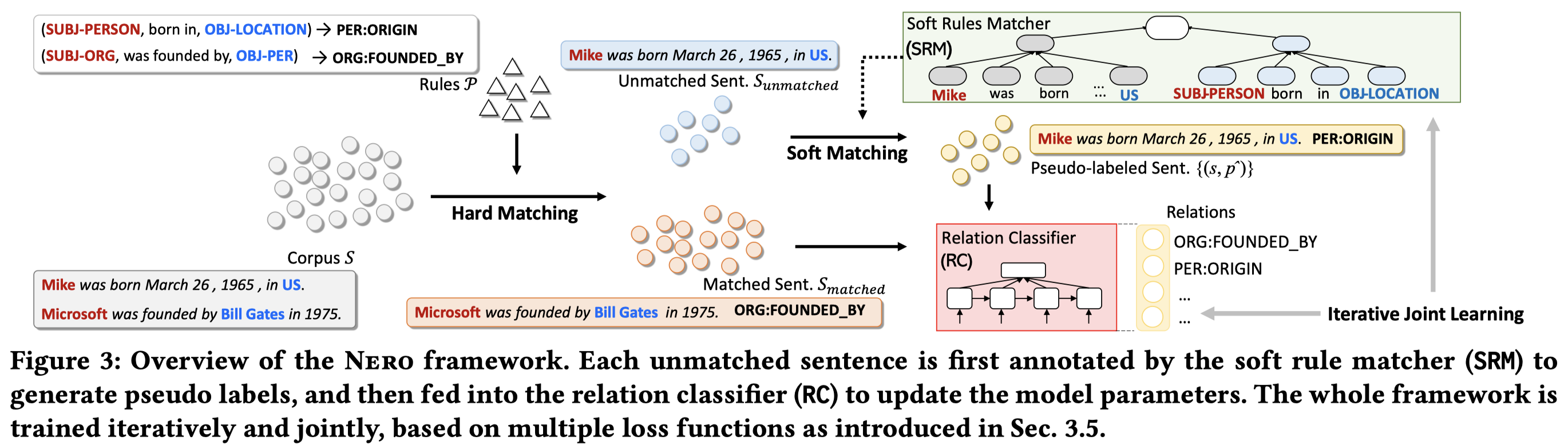
NERO: A Neural Rule Grounding Framework for Label-Efficient Relation Extraction. WWW 2020. 南加州大学. 代码.
Deep neural models for relation extraction tend to be less reliable when perfectly labeled data is limited, despite their success in label sufficient scenarios. Instead of seeking more instance-level labels from human annotators, here we propose to annotate frequent surface patterns to form labeling rules. These rules can be automatically mined from large text corpora and generalized via a soft rule matching mechanism. Prior works use labeling rules in an exact matching fashion, which inherently limits the coverage of sentence matching and results in the low-recall issue. In this paper, we present a neural approach to ground rules for RE, named Nero, which jointly learns a relation extraction module and a soft matching module. One can employ any neural relation extraction models as the instantiation for the RE module. The soft matching module learns to match rules with semantically similar sentences such that raw corpora can be automatically labeled and leveraged by the RE module (in a much better coverage) as augmented supervision, in addition to the exactly matched sentences. Extensive experiments and analysis on two public and widely-used datasets demonstrate the effectiveness of the proposed Nero framework, comparing with both rule-based and semi-supervised methods. Through user studies, we find that the time efficiency for a human to annotate rules and sentences are similar (0.30 vs. 0.35 min per label). In particular, Nero’s performance using 270 rules is comparable to the models trained using 3,000 labeled sentences, yielding a 9.5x speedup. Moreover, Nero can predict for unseen relations at test time and provide interpretable predictions. We release our code 1 to the community for future research.
Issue:RE深度model总是需要大量有标注的数据,而或者这种情况可以被远监督的方法缓解,但是远程监督由于它过于简单的假设,总是会引入大量的噪音。另一种思路,作者认为是可以考虑使用labeling rules。labeling rules可以从大规模语料中自动挖掘,并且也同样可以represents domain knowledge,此外还更加准确。但是之前的利用labeling rules的方法是hard matching的,造成了precision高,而recall低的问题。

Solution:作者的想法是应该使用soft-matching的策略,让挖掘出来的rule可以更好的召回更多的成立的unlabeled data。
首先是,什么叫做labeling rules:
labeling rules formalize human’s domain knowledge in a structured way, and can be either directly used for making predictions over test instances [2], or applied to generate labeled instances for model learning [25].
一个inductive rule包括rule body和rule head:
Formally, an inductive labeling rule consists of a rule body and a rule head.
作者定义的rule body是: \[ p = [subj-type; c; obj-type] \] 头尾实体的type,以及头尾实体中间的words作为context \(c\)。rule head就是\(p\)对应的relation label。
这篇论文还主要是使用的surface pattern来作为rule的格式,也就是非常简单的利用两个entity之间的所有word。当然有更多复杂的surface patterns,例如shortest dependency path [21, 24] and meta patterns [14]。
作者从原始语料中,首先利用NER工具,来标注实体和其对应的type。随后,然后两个entity之间的所有word作为候选rule body,并且确保其在整个语料库中出现的频率大于\(N\),之后利用人工进行标注,确定rule head。
 作者的relation classifier是一个bi-LSTM+ATT的架构:
作者的relation classifier是一个bi-LSTM+ATT的架构:
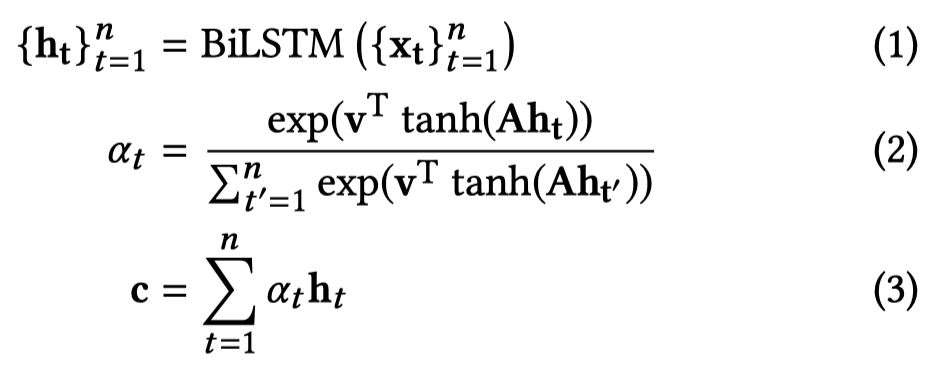
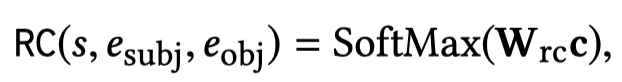
作者的soft matching是训练了一个Soft Rule Matcher,分别对rule和候选sentences中头尾实体之间的words进行编码,然后计算相似度。具体来说,Rule matcher是一个取值为\([-1,1]\)的函数,当rule能够被sentence hard matching的时候,取值为\(1\)。作者没有使用LSTM编码后的embedding,为了防止过拟合问题。而是直接使用rule和sentence的word embedding,然后进行基于attention的聚合:
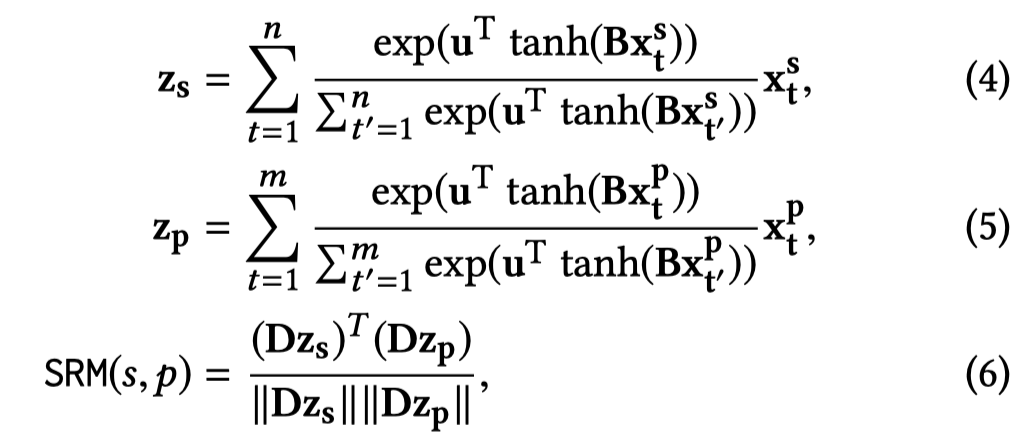
公式中,\(x_t^s,x_t^p\)分别表示sentence和rule的word embedding。\(D\)是对角矩阵,表示不同dimension的重要程度。
作者的实验场景是完全没有标注数据,只有少量的labeling rules。作者首先利用seed rules进行hard matching,获得hard-matched sentences \(S_{matched}\)。这部分数据能够有较好的标注准确度。在\(S_{matched}\),利用交叉熵训练relation classifier。
然后基于seed rules,作者又使用两个loss来训练relation classifier和soft rule matcher。一个是将rule也看做training data,让relation classifier使用交叉熵进行拟合;一个是作者期望一个好的matcher应该能够使得相同type的rule距离较近,而不同type的rule距离较远,利用contrastive loss:

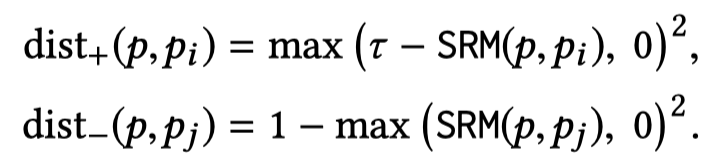
优化对比loss能够push相同type的rule的距离接近\(\tau\),而不同type的rule的距离接近\(0\)。
最后,为了能够让rule和unmatched data进行匹配,作者利用soft rule matcher取值相似度最大的rule对应的label。然后,为了减小label的noise,作者给每个batch下的unlabeled sample都有对应的instance weight。具体来说,就是soft rule matcher输出值,在batch范围内的softmax:
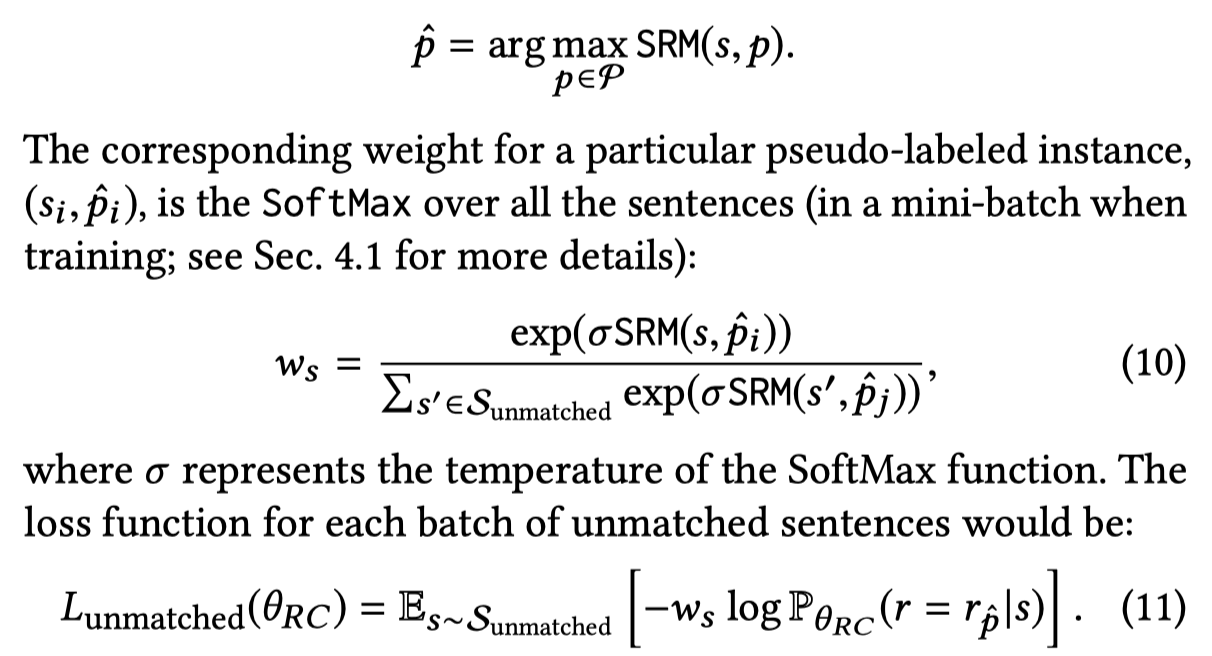
不同的loss相加,进行训练。
作者在实验的时候,利用TACRED和SemEval作为数据集:
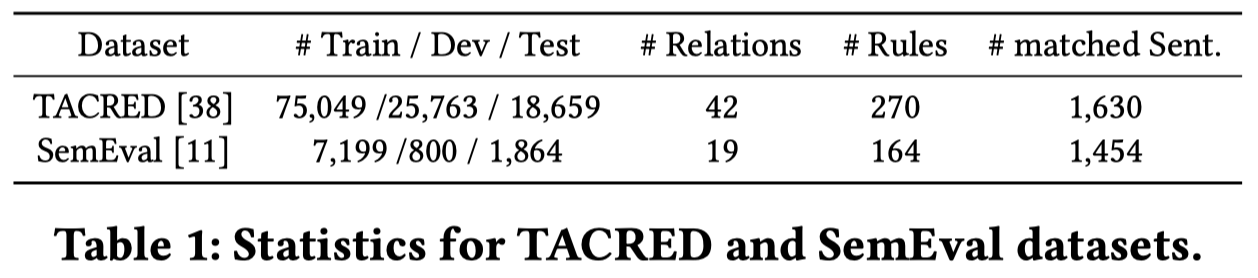
RoRED
RoRED: Bootstrapping labeling rule discovery for robust relation extraction. 武汉大学. Information Sciences
Labeling rules can be leveraged to produce training data by matching the sentences in the corpus. However, the robustness of the relation extraction is reduced by noisy labels generated from incorrectly matched and missing sentences. To address this problem, we propose the bootstrapping labeling rule discovery method for robust relation extraction (RoRED). Specifically, we first define PN-rules to filter incorrectly matched sentences based on positive (P) and negative (N) rules. Second, we design a semantic-matching mechanism to match missing sentences based on semantic associations between rules, words, and sentences. Moreover, we present a co-training-based rule verification approach to refine the labels of matched sentences and improve the overall quality of bootstrapped rule discovery. Experiments on a real-world dataset indicate that RoRED achieves at least a 20% gain in F1 score compared to state-of-the-art methods.
Issue:利用labeling rules为无标注进行标注,属于一种弱监督学习。但是这一过程中存在问题,被rule错误匹配的sentences的问题以及missing matching问题。这两个问题一定程度上是互相冲突的。
- pattern matching和semantic matching相比,semantic召回率更高,但是可能引入更多的错误
- 匹配后的sentences也不是完全正确的,同样存在noise label
Solution:作者提出了一个从多个环节考虑上述问题的方法,同时考虑positive 和negative rules,然后解决两种rule冲突的问题;此外,提出了新的semantic matching方法。
作者定义的labeling rules定义:

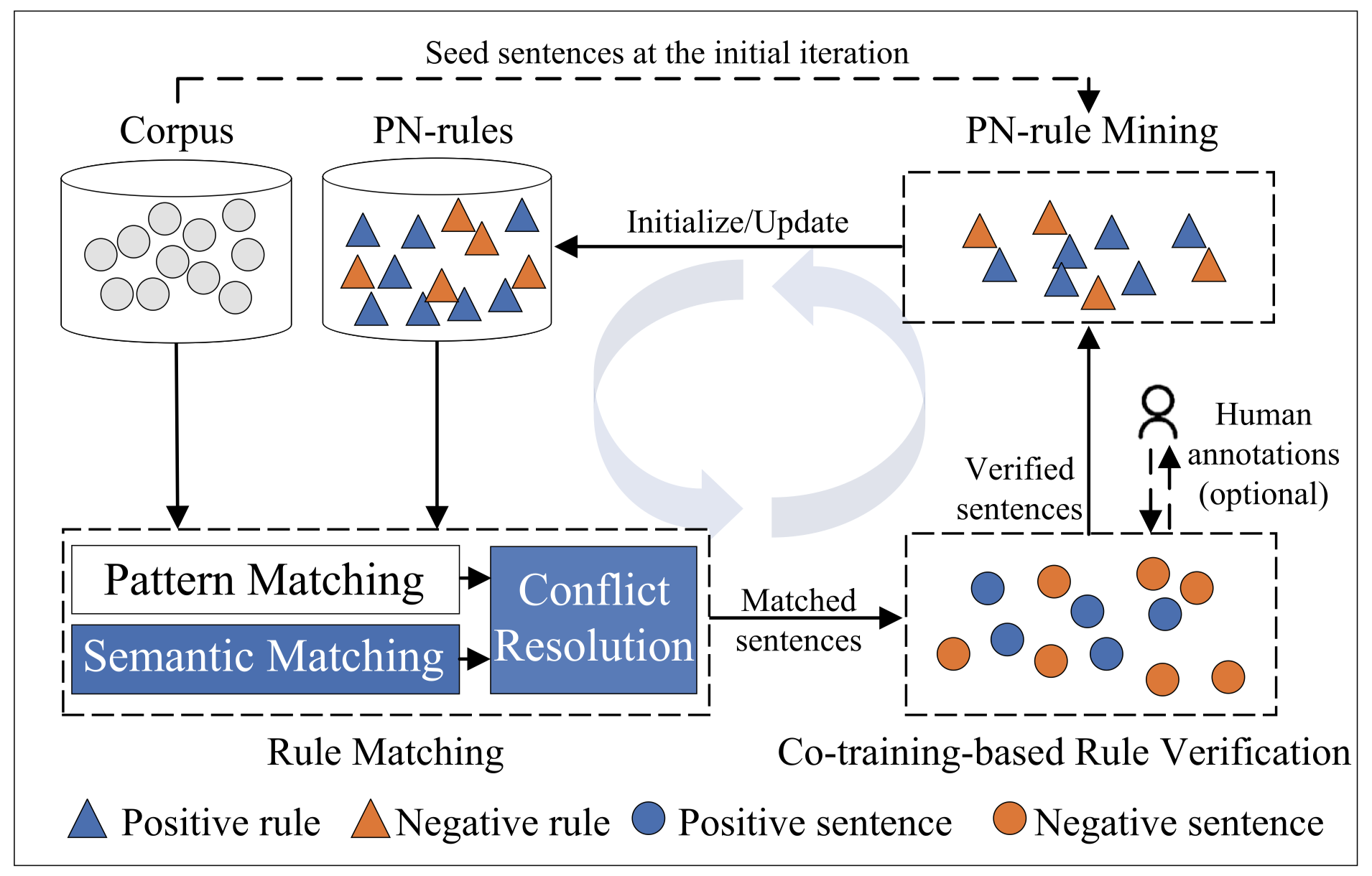
下面是作者的流程图,核心思想是从一个seed set出发,挖掘出初始的rules,利用这个rules再去获得更多被匹配的sentences,这些sentences可能也存在noise,所以再被作者训练的验证器或者加入人工进行修正。最后的sentences再经过rule mining,获得更多rule:
作者定义的对于特定关系的PN-rules(注意不是所有relation通用): \[ r.body \rightarrow (r.tag, I_t(r)) \\ r.body = p = [w,@sub-type,w,@obj-type,w] \\ r.tag = 1 / -1 / 0 \] 利用word序列作为捕获的pattern。\(r.tag\)表示是positive rule还是negative rule还是invalid,其是基于importance weight \(I_t(r)\)被决定的:
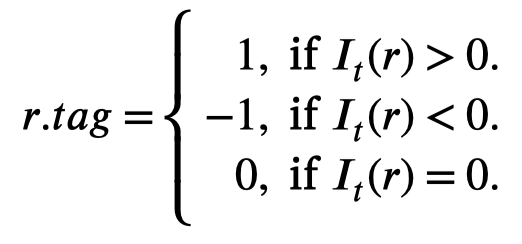
然后rule对应的两种hard matching和soft matching策略定义为:
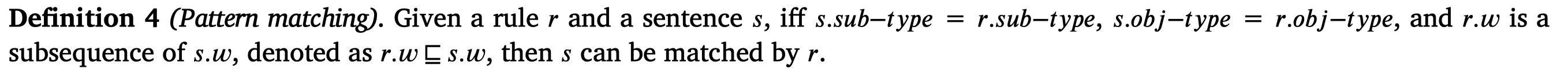

从一个子集出发,作者的规则挖掘算法是多轮迭代的。首先利用NER model [Research on Chinese naming recognition model based on BERT embeddin. 2019]去标注头尾实体type;然后替换掉原来的entity mentions,通过frequent sequence mining algorithms 频繁子序列挖掘算法 Prefix span来获得rule body。
然后是如何确定rule importance weight。作者从3个维度统计:
Credibility:检查rule是否可用,被rule匹配的sentence预测的label是否正确。正确的情况更多则大于0,否则小于0
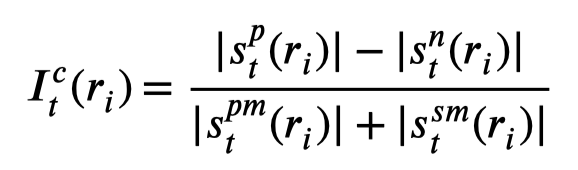
Frequency:labeling rules匹配的频率
Redundancy:同时被其它rule match的次数的频率,越频繁则代表越common,没有什么特殊的信息
最后,计算重要度:
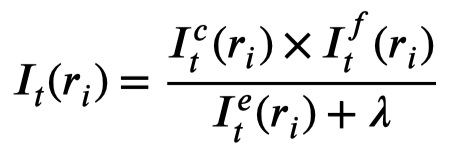
在有了rule之后,还需要研究如何能够让其匹配sentence,作者设计了一种基于随机游走的估计算法:
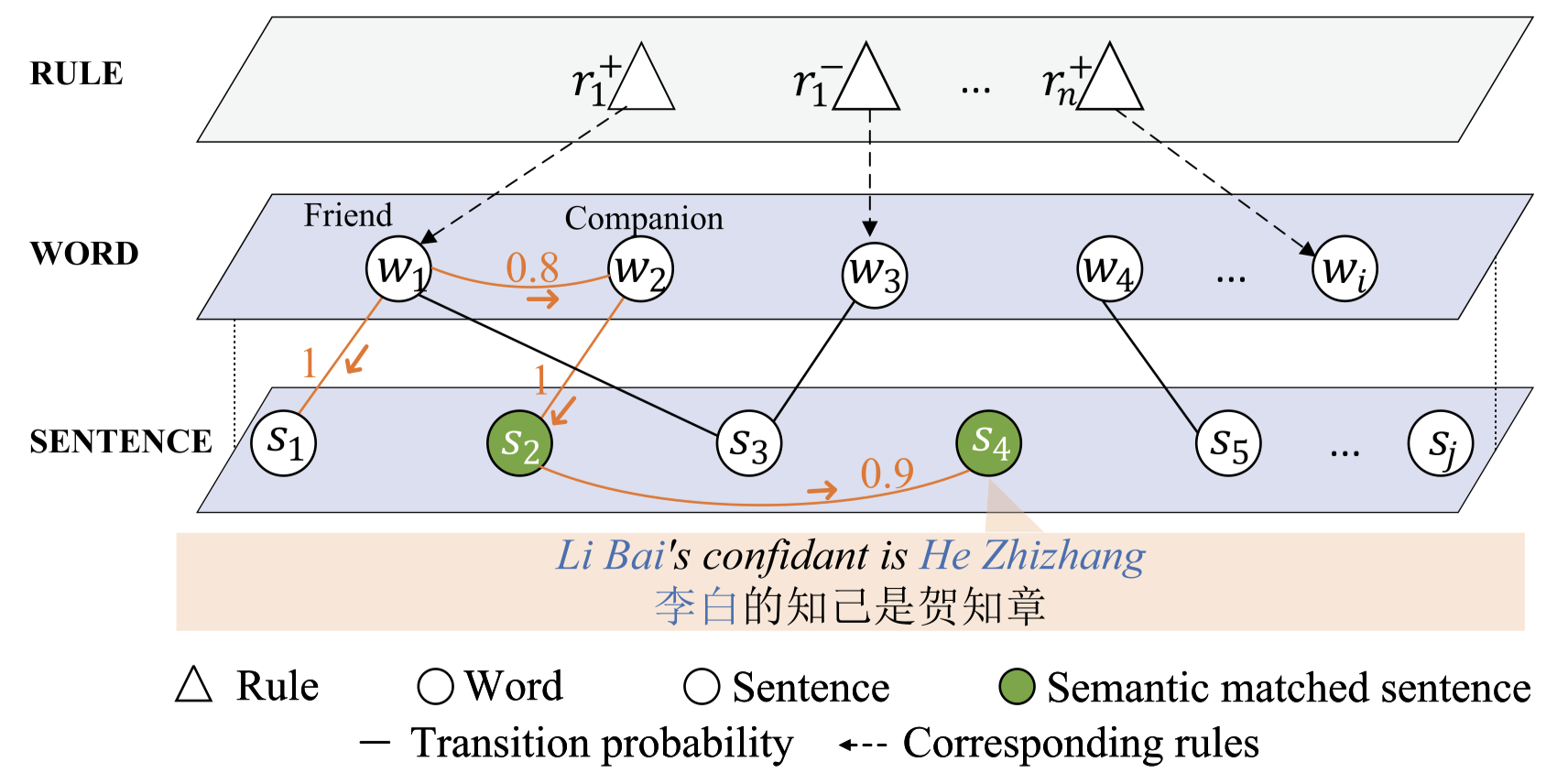
细节参考论文,这里记录下要点:
- node包括:(1)entity type匹配了的sentences(2)sentences和rule的所有words
- edge包括:(1)如果node都是sentence,或都是rule,建立建立余弦相似度edge;(2)如果一个node是word,一个node是包含其的sentence,建立包含关系,取值0/1。
- 计算从rule的context word \(w\)出发,最后能够到达某个candidate sentence的概率
- 从rule的多个context word出发,能够到达该candidate sentence的概率都大于了阈值,则认为该sentence被rule匹配
最后,如果同时被positive和negative rule匹配,则根据rule importance weight和匹配相似度,相加计算最后的匹配结果。如果结果大于0,就是positive,否则就是negative。
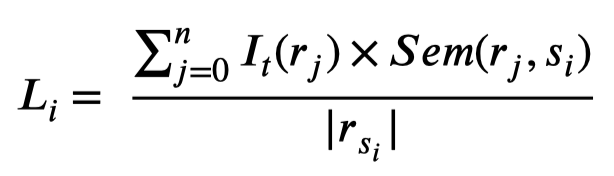
为了进一步减少被rule错误匹配的情况,作者利用两个SVM,基于pattern features和semantic features构建了两个分类器(PC和SC),会协同的判断结果是否正确:
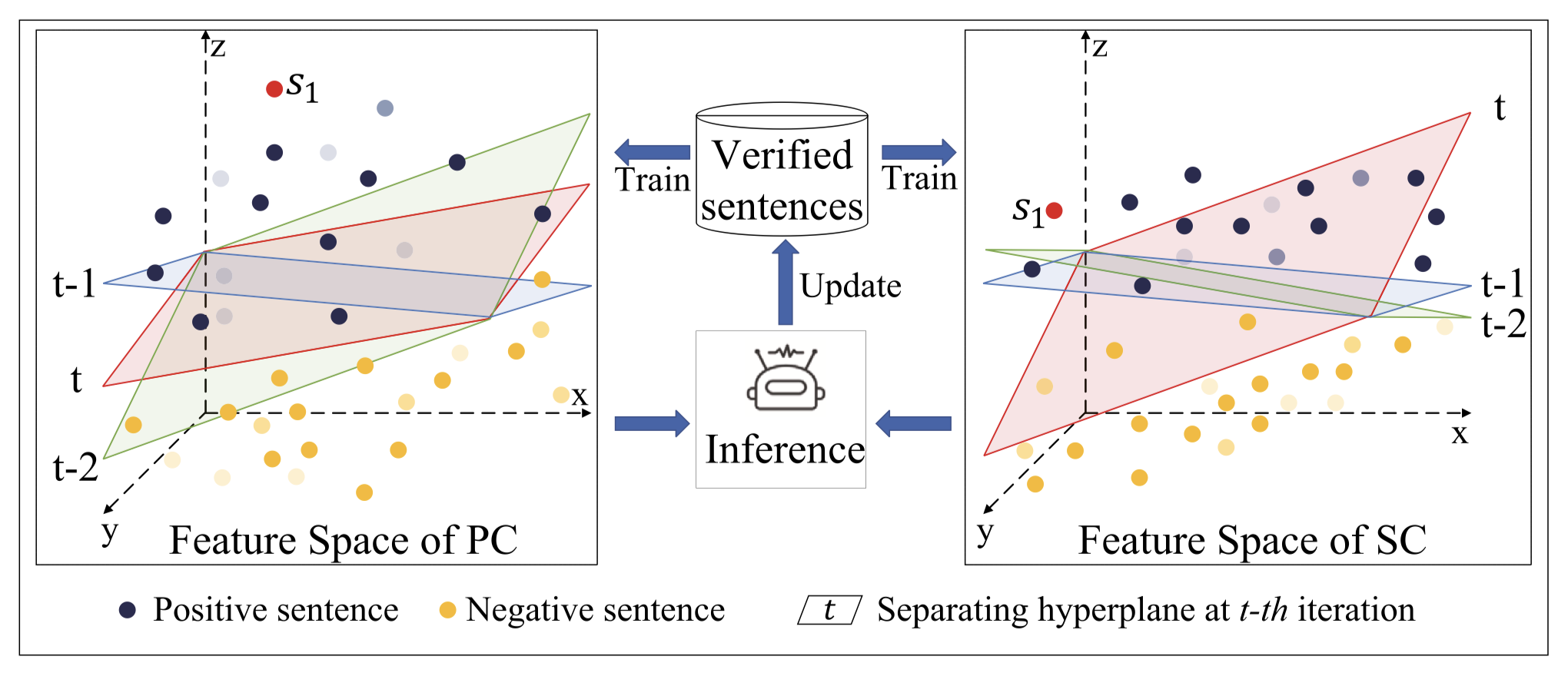
作者的实验是基于Chinese sentence-level personal RE dataset (IPRE)数据集 [IPRE: a dataset for inter-personal relationship extraction. 2019.]。
作者挖掘到的规则:

TruePIE
TruePIE: Discovering Reliable Patterns in Pattern-Based Information Extraction. University of Illinois at Urbana-Champaign. University of Illinois at Urbana-Champaign. KDD 2018
Pattern-based methods have been successful in information extraction and NLP research. Previous approaches learn the quality of a textual pattern as relatedness to a certain task based on statistics of its individual content (e.g., length, frequency) and hundreds of carefully-annotated labels. However, patterns of good contentquality may generate heavily conflicting information due to the big gap between relatedness and correctness. Evaluating the correctness of information is critical in (entity, attribute, value)-tuple extraction. In this work, we propose a novel method, called TruePIE, that finds reliable patterns which can extract not only related but also correct information. TruePIE adopts the self-training framework and repeats the training-predicting-extracting process to gradually discover more and more reliable patterns. To better represent the textual patterns, pattern embeddings are formulated so that patterns with similar semantic meanings are embedded closely to each other. The embeddings jointly consider the local pattern information and the distributional information of the extractions. To conquer the challenge of lacking supervision on patterns’ reliability, TruePIE can automatically generate high quality training patterns based on a couple of seed patterns by applying the arity-constraints to distinguish highly reliable patterns (i.e., positive patterns) and highly unreliable patterns (i.e., negative patterns). Experiments on a huge news dataset (over 25GB) demonstrate that the proposed TruePIE significantly outperforms baseline methods on each of the three tasks: reliable tuple extraction, reliable pattern extraction, and negative pattern extraction.
Issue:之前的pattern更多的是从content-based criteria来统计,比如frequency。作者提出需要考虑pattern的reliability
Solution:作者提出了一些迭代的挖掘pattern的框架,并且利用对应实体的数量作为约束arity-constraints,来评估pattern可信度的方法。从少量数据出发,利用大规模无标注数据,挖掘越来越多的patterns。
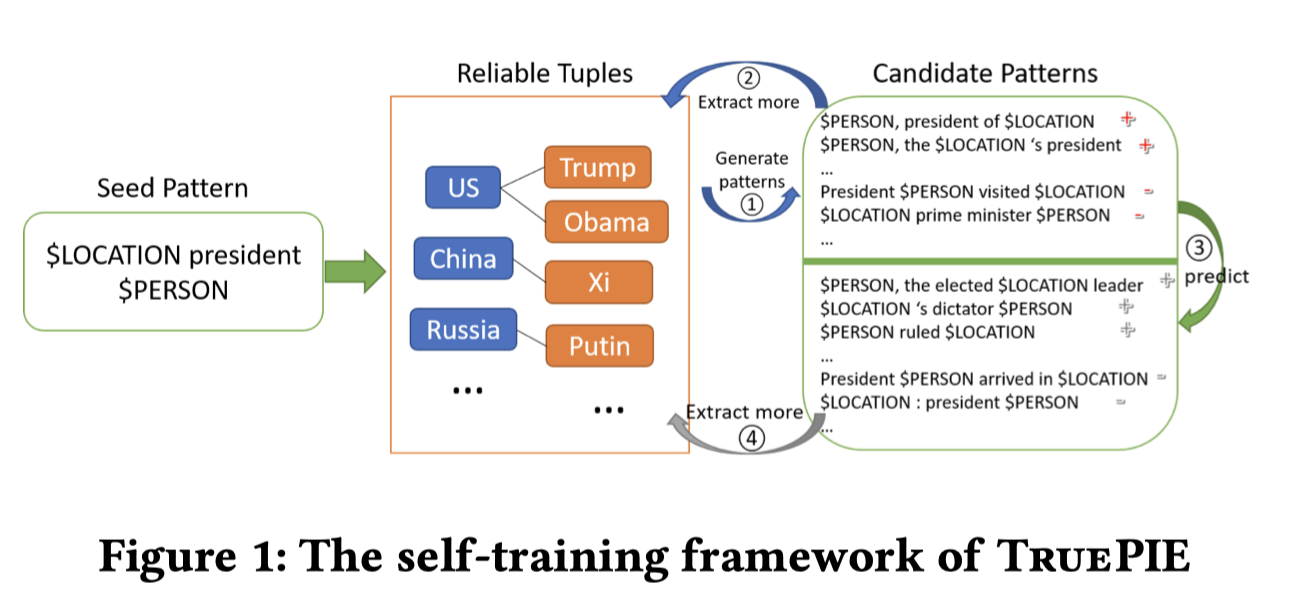
textual pattern的定义:
A textual pattern is a sequential pattern of the tokens from the set of entity types (e.g., $Location, $Person), data types (e.g., $Digit, $Year), phrases (e.g., “prime minister”), words (e.g., “president”), and punctuation marks.
一个合格的pattern应该考虑:good frequency, concordance, completeness, informativeness, and coverage。以及作者提出的Reliability。
之前有很多相关的工作:
- Automatic acquisition of hyponyms from large text corpora. 1992. 利用NP such as NP, NP, and NP pattern来抽取上下位关系hyponymy relations
- Snowball是一个能够抽取大量patterns的工具。Snowball: Extracting relations from large plain-text collections. 2000
- 谷歌提出了E-A pattern A of E和E ’s A来从用户查询当中抽取,E指entity,A指attribute。Biperpedia: An ontology for search applications. VLDB 2014
- ReNoun提出了S-A-O patterns,如S’s A is O和O, A of S。ReNoun: Fact extraction for nominal attributes. 2014
- MetaPAD提出了meta pattern的概念
作者定义的pattern的Reliability就是值利用这个pattern来抽取信息,有多大的概率抽取出来的信息是正确的。
作者的方法基于的pattern可以是现有的任意pattern,但是默认是基于MetaPAD方法来生成候选的pattern。利用word embedding来表示pattern embedding。例如对于$Location president $Person pattern,分别根据关键词\(president\)和其抽取出来的元组来表示pattern embedding:

作者提出了一个头尾实体的数量约束,叫做Arity-Constraint。一个entity关联的value数量可能是有限的。比如one president总是应该只和one country关联,如果有两个国家的话,肯定有一个是错误的。
作者评估pattern的正确性,要根据其抽取出来的tuple的正确性来判断。对于抽取出来的一个tuple:
- 没有在seed set中出现的tuple,并且违背了Arity-Constraint约束的,认为是
negative; - 如果tuple在seed set中出现,则是
positive; - 否则就是
undecidable
Arity-Constraint约束是可以人为指定,也可以统计得到。作者提出考虑到常见的长尾分布,可以利用实体分布的中位数来指定:
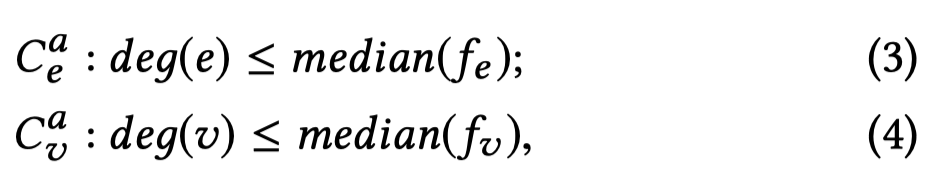
确定了单个tuple的正确性与否后,可以判断其对应的pattern的可靠性:
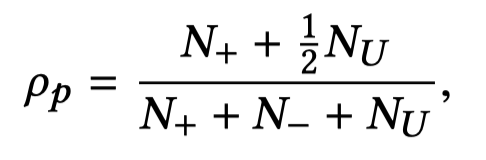
如果计算出来的值\(\rho_p\)大于阈值接近1,则认为pattern是positive;如果接近0,则是negative;如果接近0.5,则是undecidable。
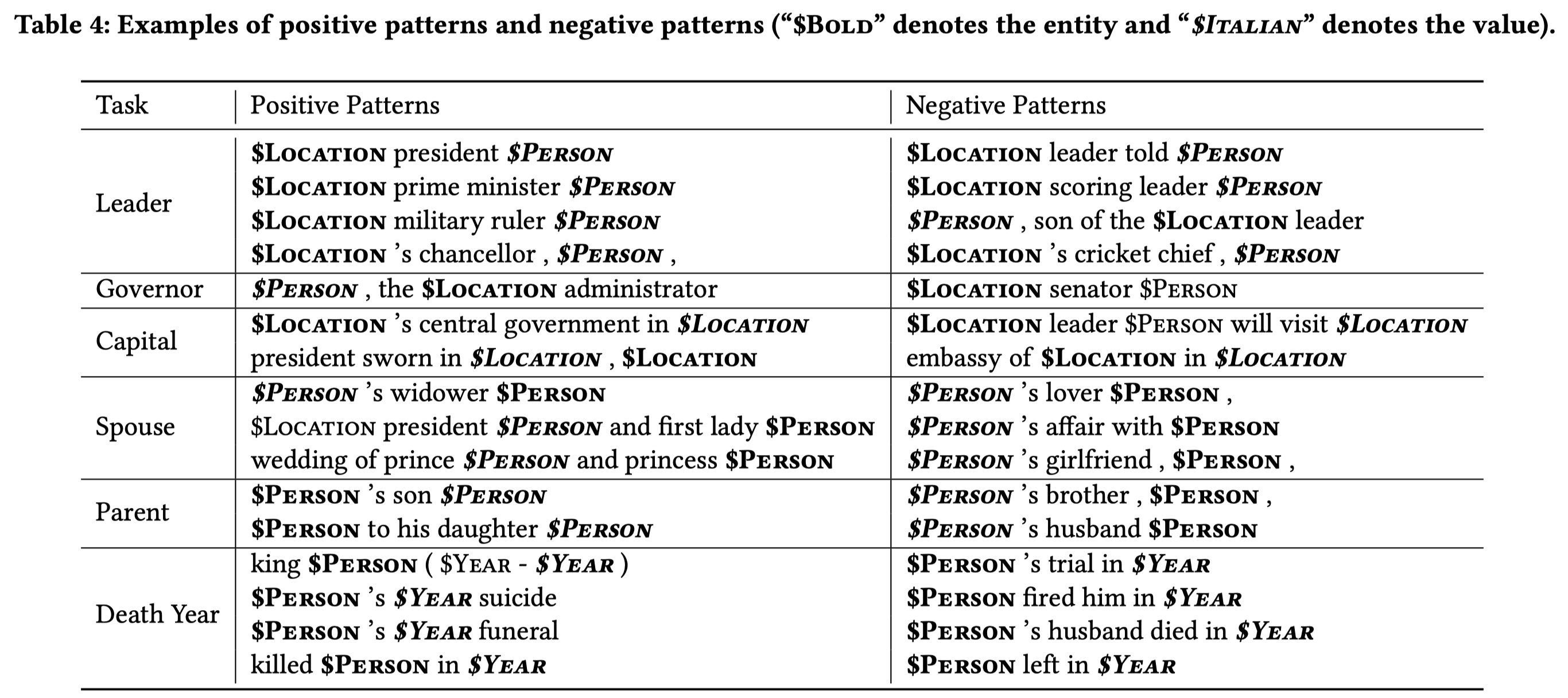
PRBoost
PRBoost: Prompt-Based Rule Discovery and Boosting for Interactive Weakly-Supervised Learning. Georgia Tech. ACL 2022. 代码.
Weakly-supervised learning (WSL) has shown promising results in addressing label scarcity on many NLP tasks, but manually designing a comprehensive, high-quality labeling rule set is tedious and difficult. We study interactive weakly-supervised learning—the problem of iteratively and automatically discovering novel labeling rules from data to improve the WSL model. Our proposed model, named PRBoost, achieves this goal via iterative prompt-based rule discovery and model boosting. It uses boosting to identify large-error instances and then discovers candidate rules from them by prompting pre-trained LMs with rule templates. The candidate rules are judged by human experts, and the accepted rules are used to generate complementary weak labels and strengthen the current model. Experiments on four tasks show PRBoost outperforms state-of-the-art WSL baselines up to 7.1%, and bridges the gaps with fully supervised models.Our Implementation is available at https: //github.com/rz-zhang/PRBoost.
Issue:现有的弱监督学习方法面临两个问题:
- first, it is challenging to provide a comprehensive and high-quality set of labeling rules a priori. 如何寻找到高质量的labeling rules。之前的方法要么是experts写的,成本很高;要么是自动化的方法,常常被局限在frequent patterns or predefined types
- Second, most existing WSL methods are static and can suffer from the noise in the initial weak supervision. 一旦确定了rule set,就是固定的,initial error会一直存在。
Solution:作者提出了通过构造template,让LM生成相应的rule,然后与人工协同,迭代的提升效果的方法。
先来看labeling rule和弱监督学习的关系:
Weakly-supervised learning (WSL) has recently attracted increasing attention to mitigate the label scarcity issue in many NLP tasks. In WSL, the training data are generated by weak labeling rules obtained from sources such as knowledge bases, frequent patterns, or human experts. The weak labeling rules can be matched with unlabeled data to create large-scale weak labels, allowing for training NLP models with much lower annotation cost. WSL has recently achieved promising results in many tasks including text classification (Awasthi et al., 2020; Mekala and Shang, 2020; Meng et al., 2020; Yu et al., 2021b), relation extraction (Zhou et al., 2020), and sequence tagging (Lison et al., 2020; Safranchik et al., 2020; Li et al., 2021b).
也就是说,所谓的弱监督学习就是利用weak labeling rules去获得更多的training data。
弱监督学习在其它论文中的定义 Training Subset Selection for Weak Supervision. NeurIPS 2022:
Weak supervision uses expert-defined “labeling functions” to programatically label a large amount of training data with minimal human effort. Labeling functions are often simple, coarse rules, so the pseudo-labels derived from them are not always correct. There is an intuitive tradeoff between the coverage of the pseudo-labels (how much pseudo-labeled data do we use for training?) and the precision on the covered set (how accurate are the pseudo labels that we do use?).
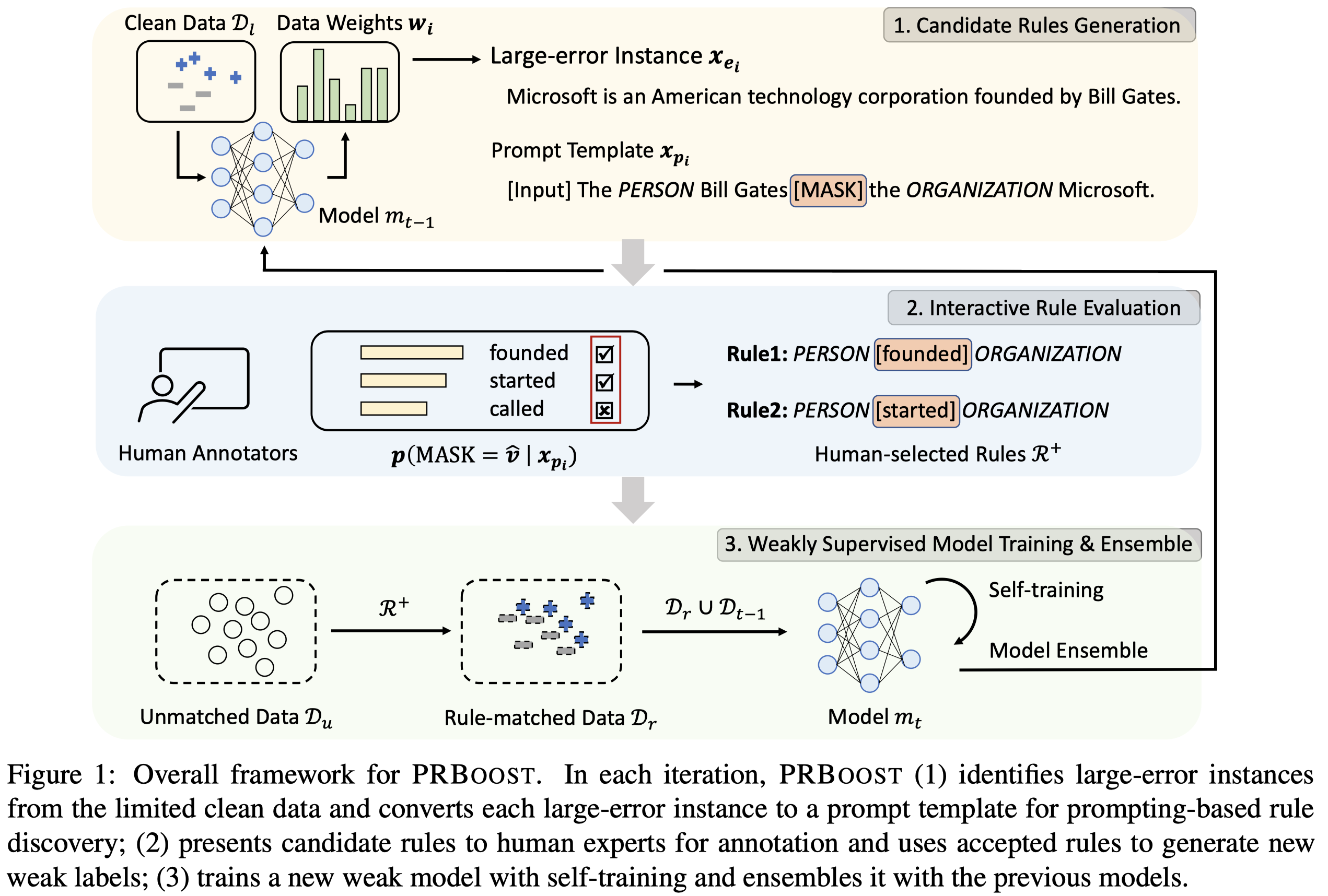
初始状态,作者有个小规模的标注数据集作为clean dataset(对于TACRED数据集使用5%的训练数据),然后使用NERO方法提供的labeling rules作为initial weak supervision source(没理解这个的作用何在)。
\(t\)轮迭代,作者每次都是从clean dataset \(D_l\)中选择最容易出错的\(10\)个large-error instances来不断的总结新的rule。每个instance \(i\)都有一个对应的weight \(w_i\),这个weight统计task model \(m_t\)犯错的累积:

上面的\(\alpha_t\)是model \(m_t\)的weight,预测正确的越多,weight越大。而此时model对于某个instance犯错越多,这个instance的易错weight \(w_i\)越来越大。
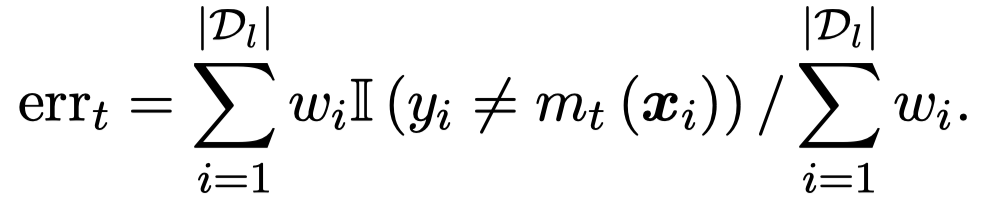
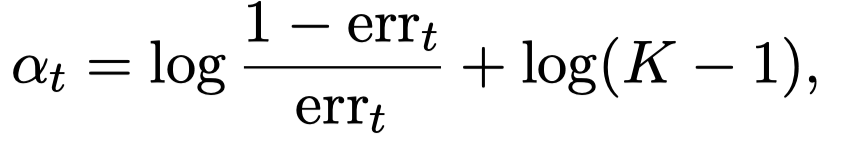
选择出来易出错的instances之后,作者定义的rule以及其对应的prompt template如下:

这些prompt被创建后,输入RoBERTa-base,然后取其输出[MASK] token最大的前\(10\)个tokens作为候选rules。候选rules之后要被3个experts人工判断accepted or not。
通过了人工判断后的rule,要matching sentences的话,作者提出了2种角度匹配方法,一起加起来匹配score大于阈值,才能被认为是matched:
- 一个是直接计算rule和sentence embedding的相似度
- 一个是把sentence放入template,导出候选words,然后和已知的rule words比较,计算重叠的words数量
获得了更多的标注数据之后,作者在\(t\)轮就可以训练新的model \(m_t\)了(利用交叉熵)。训练完毕之后,由于还存在没有被rule匹配的无标注数据,为了让有标注数据向无标注数据propagate information,作者又用了self-training的策略,通过给定无标注数据soft伪标签,来进一步训练model。具体参考论文。
每一轮都训练出来一个了model,最后集成,作为boosting方法:
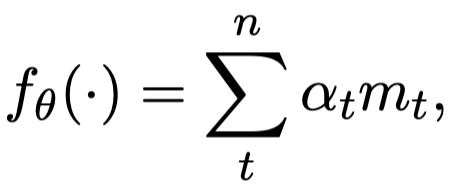
实验结果:
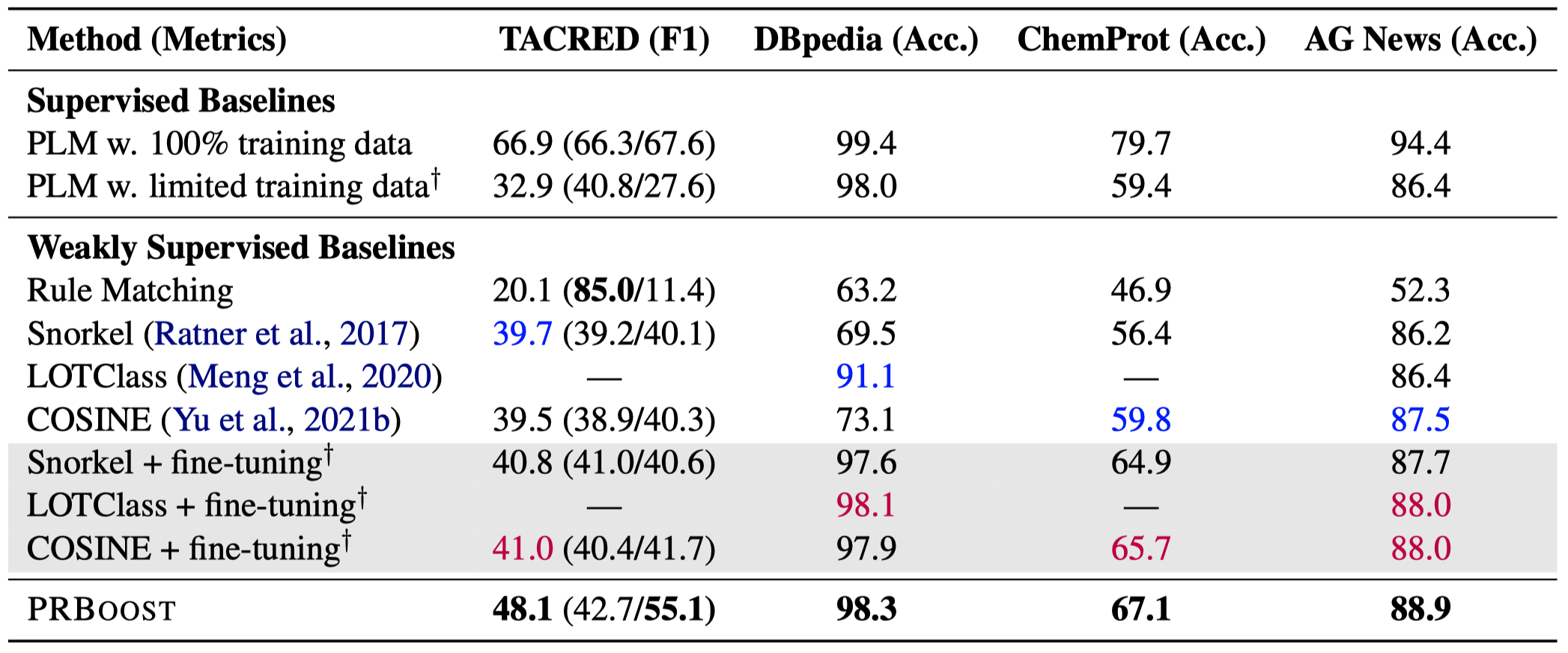
实验,挖掘到的规则示例:
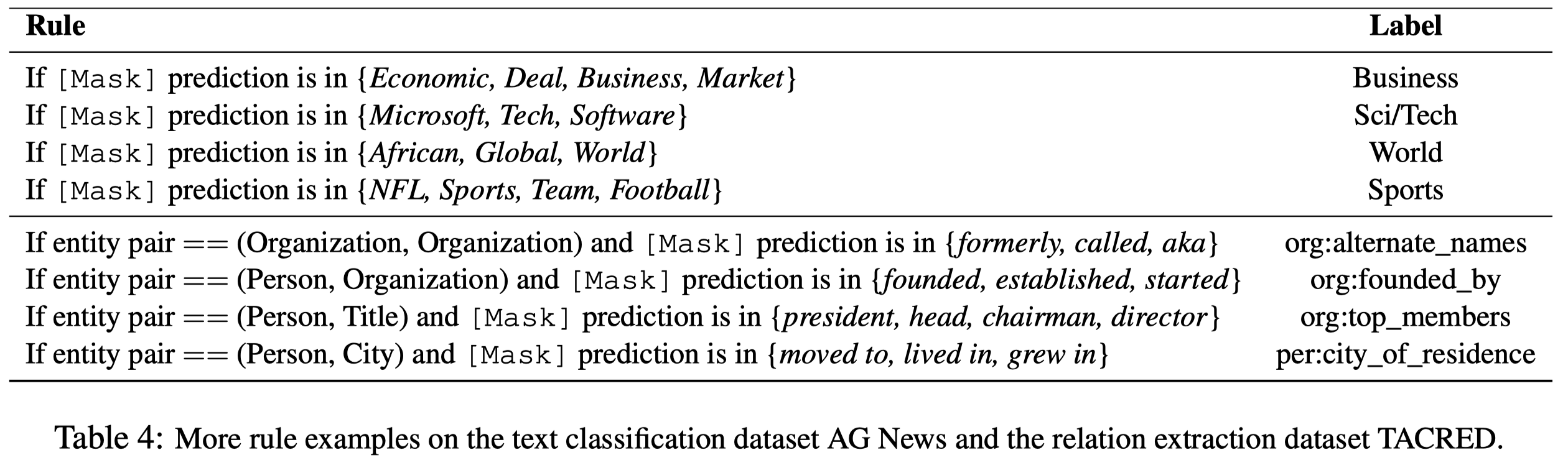 ## ARI
## ARI
Automatic Rule Induction for Efficient Semi-Supervised Learning. Microsoft. EMNLP 2022 Findings. 代码.
Semi-supervised learning has shown promise in allowing NLP models to generalize from small amounts of labeled data. Meanwhile, pretrained transformer models act as black-box correlation engines that are difficult to explain and sometimes behave unreliably. In this paper, we propose tackling both of these challenges via Automatic Rule Induction (ARI), a simple and general-purpose framework for the automatic discovery and integration of symbolic rules into pretrained transformer models. First, we extract weak symbolic rules from low capacity machine learning models trained on small amounts of labeled data. Next, we use an attention mechanism to integrate these rules into high-capacity pretrained transformer models. Last, the rule-augmented system becomes part of a self-training framework to boost supervision signal on unlabeled data. These steps can be layered beneath a variety of existing weak supervision and semi-supervised NLP algorithms in order to improve performance and interpretability. Experiments across nine sequence classification and relation extraction tasks suggest that ARI can improve state-of-the-art methods with no manual effort and minimal computational overhead.
Issue: 训练神经网络需要很多标注数据,这激发了人们研究如何同时利用标注数据和无标注数据。另外,单纯的神经网络缺乏解释性,同时有时是unreliable的。
Solution: 作者提出了一种比较通用的rule discovery框架。
首先,作者从少量的标注数据中归纳rule,要先把文本形式的rule转化为数值特征形式。作者考虑了N-gram(二元向量,词袋size为\(V\))和基于PCA的方法。PCA是在N-gram基础上,考虑到如果只有少量的data,N-gram表示向量中的common ngrams可能是spuriously correlated with the labels。因此,PCA方法利用SVD将N-gram表示的原始text data矩阵进行分解,然后每个data sample的N-gram向量都减去first principal component。
其次,基于简单的机器学习来构造rule。作者考虑了线性模型和决策树两种方法: - linear model:能够用于N-gram的特征向量表示。训练一个简单的带有element wise的分类器。然后从分类器的权重矩阵\(W\)中取出前\(R\)最大的权重weight,然后对于每个样本\(x_j\)如果其对应的ngram和weight计算出来的label是正确的,就可以创建一个rule - decision trees:能够用于N-gram和PCA的特征向量表示。使用深度为3的随机森林,对于任意一棵决策树,如果它能够正确预测样本\(x_j\)的label的概率大于阈值,就可以创建一个rule
为了对错误的rule进行过滤,作者对于某个rule和匹配的样本\(x_j\)以及预测label \(l\)。然后,作者利用Sentence BERT表示样本\(x_j\)和现有数据集中所有具有label的样本。作者计算其之间的余弦相似度,如果最大的余弦相似度都低于\(0.8\),那么就过滤掉rule。
作者设计了一个同时集成rule的预测结果和一个基于BERT的backbone的RE model的预测结果。记BERT的预测结果是\(b(\cdot)\)。作者引入一个rule aggregation layer,每个rule都有自己的embedding \(e_j\),BERT的backbone有自己的embedding \(e_s\)。取能够和样本匹配的所有rule集合,计算和样本embedding \(p(h_i)\)之间的相似度,然后相似度和预测结果进行weighted sum:

最后,联合训练BERT的backbone的RE model以及rule aggregation layer。
实验部分,作者对训练集5% / 95% split between labeled data and unlabeled data。
KICE
KICE: A Knowledge Consolidation and Expansion Framework for Relation Extraction. 浙大. AAAI 2023
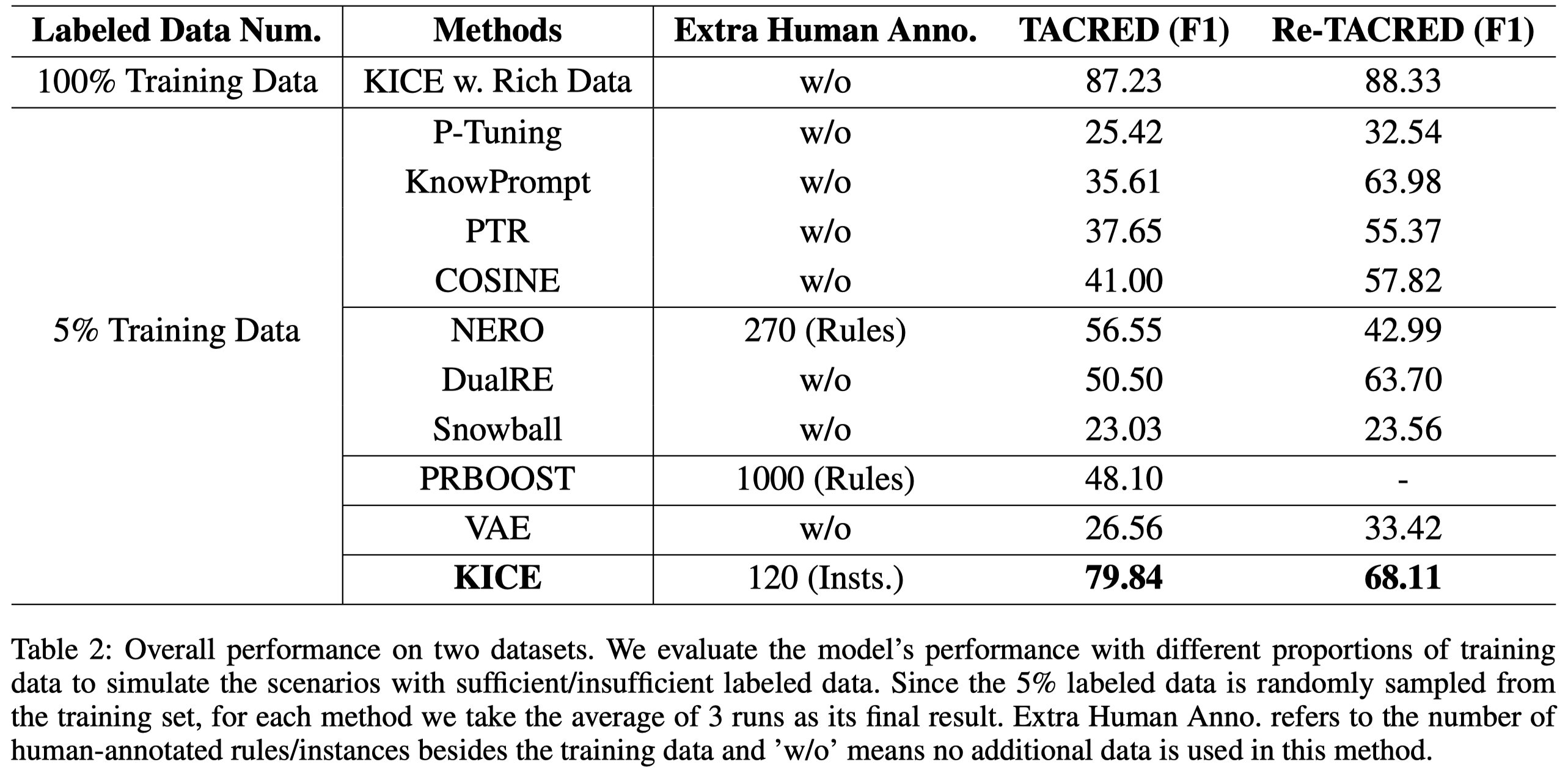
Machine Learning is often challenged by insufficient labeled data. Previous methods employing implicit commonsense knowledge of pre-trained language models (PLMs) or pattern-based symbolic knowledge have achieved great success in mitigating manual annotation efforts. In this paper, we focus on the collaboration among different knowledge sources and present KICE, a Knowledge-evolving framework by Iterative Consolidation and Expansion with the guidance of PLMs and rule-based patterns. Specifically, starting with limited labeled data as seeds, KICE first builds a Rule Generator by prompt-tuning to stimulate the rich knowledge distributed in PLMs, generate seed rules, and initialize the rules set. Afterwards, based on the rule-labeled data, the task model is trained in a self-training pipeline where the knowledge in rules set is consolidated with self-learned high-confidence rules. finally, for the low-confidence rules, KICE solicits human-enlightened understanding and expands the knowledge coverage for better task model training. Our framework is verified on relation extraction (RE) task, and the experiments on TACRED show that the model performance (F 1 ) grows from 33.24% to 79.84% with the enrichment of knowledge, outperforming all the baselines including other knowledgeable methods.
Issue:获取大规模的RE任务标注数据是很困难的。特别是从relation数量的角度来说,现在还没有数据集包括了超过200种关系。而实际上,现实中往往有更多的关系,比如Wikidata有超过6000种关系。
为了减少人工成本,一些研究开始使用不同外部knowledge source来获取标注。比如从外部KG获取标注数据,或者是基于active learning为confusing data获取额外的human annotations。这种做法分别存在问题:
- 外部KG的coverage是有限的
- 基于active learning的方法在一开始的时候由于冷启动问题,很难准确评估data的uncertainty
Solution: 作者把rules看做是一种能够在多个knowledge source之间进行信息传递的可解释的形式,同时还能够提供weak labels的方法:
Specifically, we engage the rule-based patterns as transferred and explainable forms among different knowledge sources, which are also beneficial to match large-scaled unlabeled instances and provide weak labels for those data.
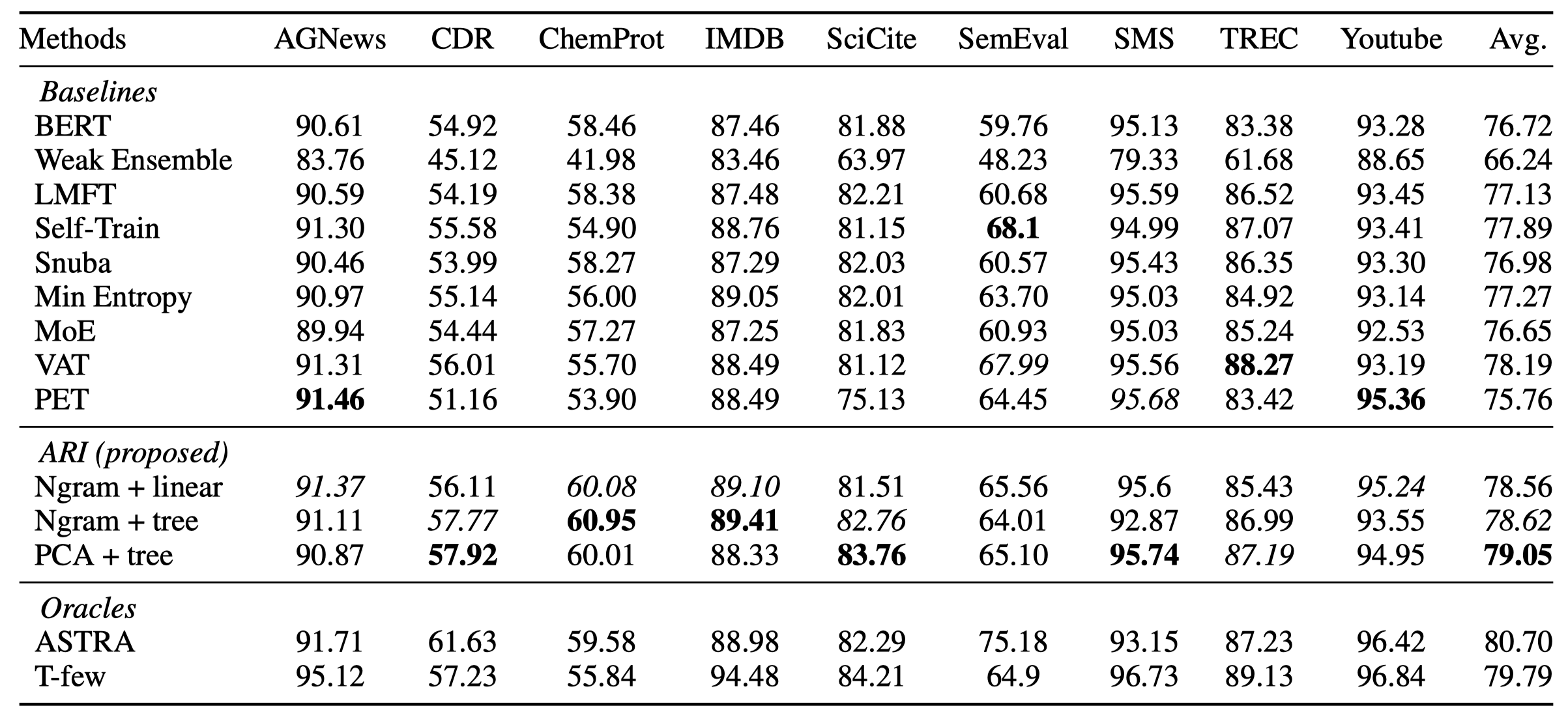
方法图:
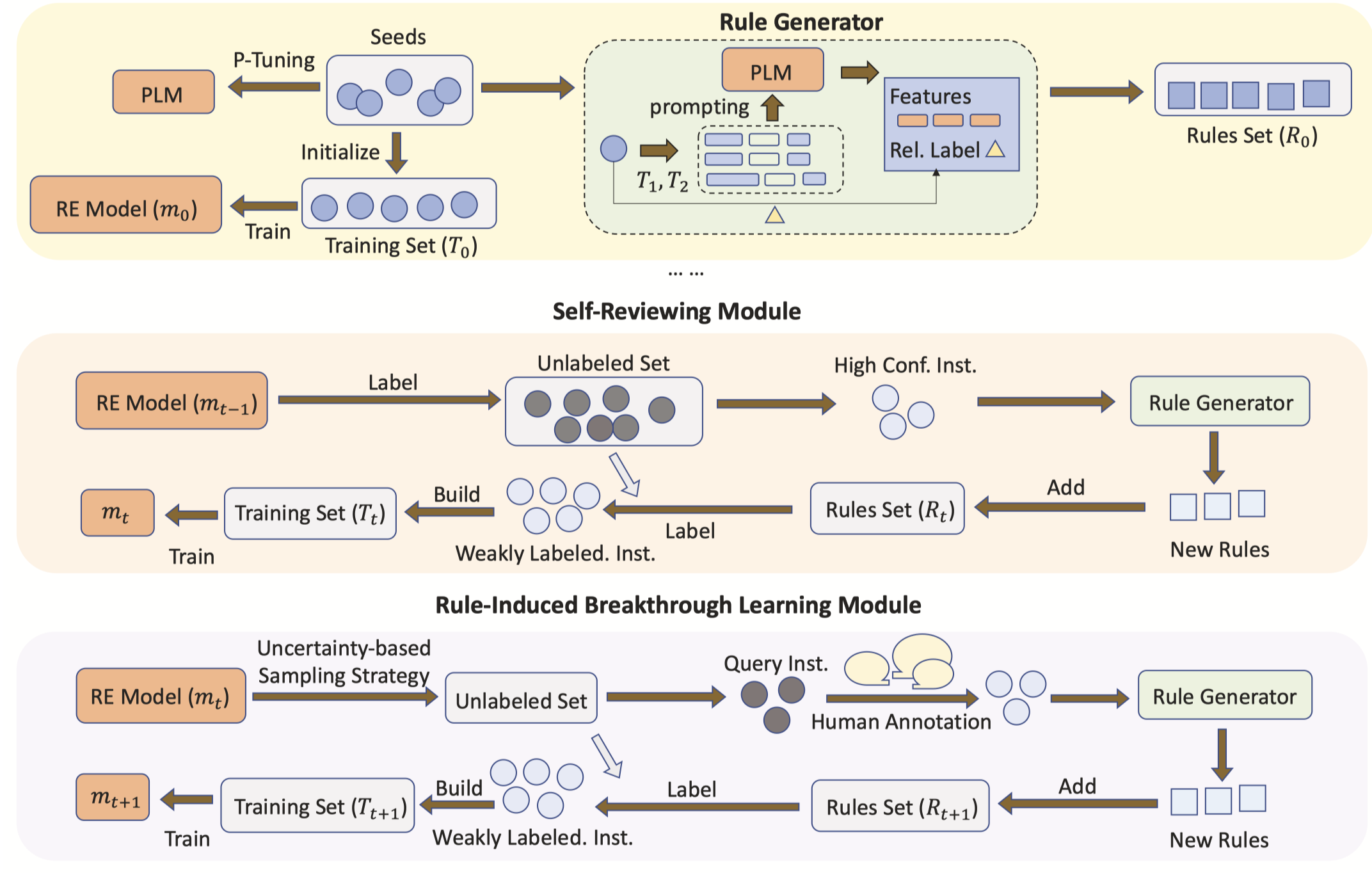
作者的规则定义,包括entity pattern、relation pattern,label,threshold和similarity function:

匹配的阈值作者人工设置为\(0.97\)。
考虑到training sample和rule可能使用同义词作为patterns来表示相同的relation,因此仅仅是hard matching的方法可能导致low rule coverage。rule和instance匹配使用soft-matching策略,利用BERT word embedding去表示pattern words,以平均作为总体的表征,然后计算余弦相似度:
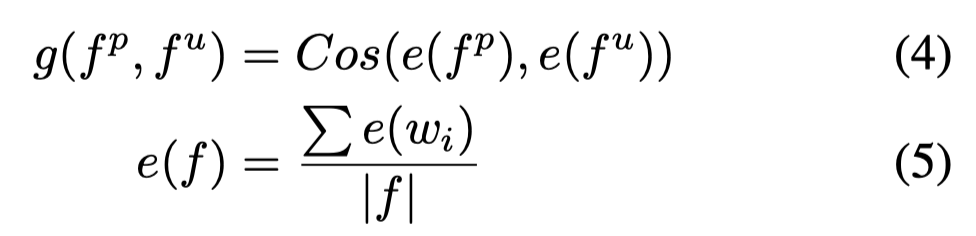
基于一个small-sized seed instances,作者先利用P-tuning训练了一个PLM用作rule generator,训练任务是输入带有[MASK]的prompt,然后填充prompt,输出的多个结果作为rules。为了训练,作者构造了两种template和对应的拟合目标:
- Template1: 作者把initial small seed里的entity,对应在Microsoft Concept Graph上的concept找出来作为优化目标。这里就是利用rule连接了外部KG的knowledge。
- Template2: 把能够填充relation mentions作为优化目标,例如把'city_of_birth'这个relation,转化为'{city birth}'这两个words。
在获得了一个rule set之后,去匹配unlabeled data。多个rule都匹配了的话,就投票选择label最多的那个作为rule匹配的weak label \(l\)。
基于rule匹配的方法,也可以统计预测confidence,多个匹配的rules(对应最后的weak label \(l\))的相似度相加作为label confidence:
接下来是作者的Self-Reviewing Module,迭代的训练RE model。\(t-1\)轮训练好的model \(m_{t-1}\)对unlabeled data进行预测,选择高confidence的样本创建新rules,新rules又能够找到更多新标注data。
上述的做法迭代self-training策略,会让model倾向于选择特定的patterns,
Simply repeating the Self-Reviewing Module may narrow the model’s comprehension for some relations and stick in specific patterns (as reported in Snowball (Gao et al. 2020)).
因此作者有个Rule-Induced Breakthrough Learning Module选择confusing data获取human knowledge。具体做法是,选择某个unlabeled instance \(u\),利用rule generator生成rule,但是没有正确的relation label;然后基于规则匹配找到另外一个unlabeled instance \(\bar{u}\)。两个具有相似pattern的unlabeled instance的RE model预测\(y\)分布差异越大,说明RE model对此类pattern下的instances预测的不确定性更高:

评估所有unlabeled instance的\(KLD\),选择最模糊的\(60\)个confusing data来进行human annotation。标注之后,重新从这些instances里生成新的rules,存入rule set。
最后,在利用带有weak label的训练集合迭代训练task model的时候,作者follow COSINE工作采用了一种denoising训练策略。具体参考论文。
作者的实验,在TACRED和Re-TACRED上,大致上取了5%作为initial training set,剩下的作为unlabeled data。验证集规模和训练集保持一致。具体说是 86 seed data per relation for TACRED and 73 seed data per relation for Re-TACRED。
总体实验结果:
ARIA
Reasoning Makes Good Annotators : An Automatic Task-specific Rules Distilling Framework for Low-resource Relation Extraction. EMNLP 2023 Findings. 浙大.
Relation extraction is often challenged by insufficient labeled data. Previous methods exploit knowledge from unlabeled data by generating pseudo labels in a self-training pipeline, which suffers a gradual drift problem. Logic rules, a transferable and explainable form of expert knowledge, have achieved promising success by improving the model with weak labels. But manually writing comprehensive rules set is challenging and tedious. To alleviate the human labor of writing high-quality rules, in this work, we propose ARIA, an Automatic task-specific Rules dIstilling frAmework. Specifically, we guide the pre-trained language model to reason rules as experts and compose them into robust compound rules for data labeling. Besides, ARIA could continuously enrich the rules set to power the labeling ability by discovering reliable model-labeled data for distinguishable rules generation. Experiments on two public datasets demonstrate the effectiveness of ARIA in a low-resource scenario.
Issue: 半监督学习能够从大量无标注数据中获取信息。经典做法是self-training,这种做法缺点是model预测的错误标注会不断累积(gradual drift problem)。另外一种做法是利用logic rules,人工写rule是很费力的,因此有很多方法讨论如何自动创建rule。远程监督的方法也可以看做是利用labeling rules,即只要出现特定头尾实体,就认为sentence存在特定关系。后续出现了一些利用PLM来寻找关键信息,构造rule的方法,但是其没有考虑task-specific reasoning process,总结出来的rule是less transferred和explainable的。
The logic rule is an explainable and transferred form to summarize knowledge, which could replace human for weak labels generation.
Solution:作者主要利用PLM来生成rules,并且是考虑了4种不同的推理情况:

首先,为了能够生成rule,作者总结的4种prompt template:

每个训练sample,都会创建4个prompt,输入PLM之后,获得4种rule的premise。然后考虑到不同的推理过程可能能够帮助进行更加robust reasoning。作者遍历4种premise的组合排列,然后再进行过滤,输入到PLM询问premise和label是否能够对应的成立:
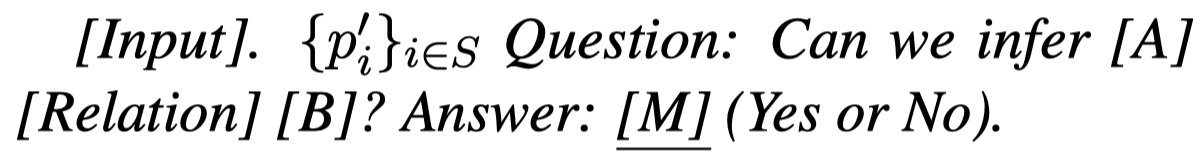

PLM输出”Yes“的概率就是评估的score,然后作者只选择top \(N_c=8\) 的组合rule。
随后要利用组合的rule \(p_s\)和unlabeled data进行match。作者的做法是用PLM先用于unlabeled sample,总结出premise,也就是对应的4种rule的被填充的mask words。每个mask token使用Glove embedding表示,然后和\(p_s\)中的对应rule的mask words计算余弦相似度,只要大于阈值\(TH=0.8\)就认为匹配:
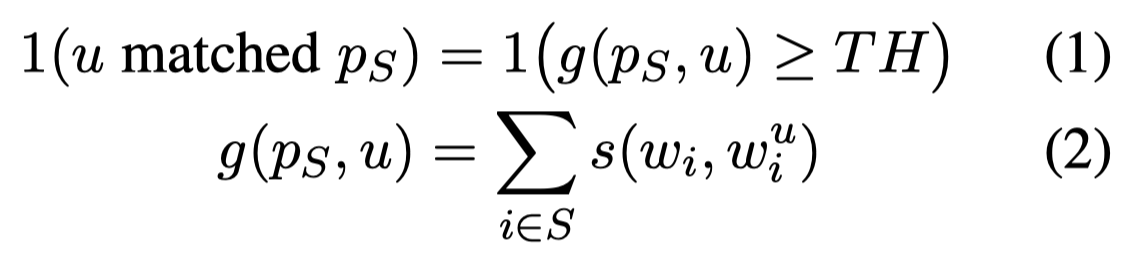
如果多个rule都匹配,并且互相之间冲突。那么就取最大相似度的rule对应的label。每次迭代取匹配相似度top \(N_d=100\)的rule-labeled data放入到training set,然后训练RE model。
RE model继续在无标注data中进行标注,获得model-labeled data。为了进一步过滤掉新标注数据的错误标注,寻找具有和relation一致features的新data,作者提出了graph-based data filter方法。核心思想是,在有真实标注的seed data和model-labeled data之间基于相似度构造graph。对于不同的relation,seed data有对应的\(0/1\)的二元标注。利用GAT聚合邻居信息,那么学习到的data embedding可以被用来预测某个data是否属于特定的relation。具体过程:
- 初始化embedding:拼接每个data sample的4种rule的reasoning words,也就是graph的每个node都是rule
- graph construction:k-NN,余弦相似度,结合seed data和model-labeled data构造graph。对于relation \(r\),seed data的每个node都有对应的\(0/1\)二元标注
- Inference Features Propagation:2层GAT聚合
- loss:seed data能够进行二元分类的二元交叉熵;以及鼓励邻居之间特征相似的loss
- High-quality Data Filtering:为了选择具有consistent features的新rule的data,计算unlabeled samples和averaged positive以及negative中心embedding的相似度,然后相减,排序,选择top \(N_p=15\)的进行下一步的rule生成
作者的方法使用使用Roberta-base作为PLM,BERT作为RE model。
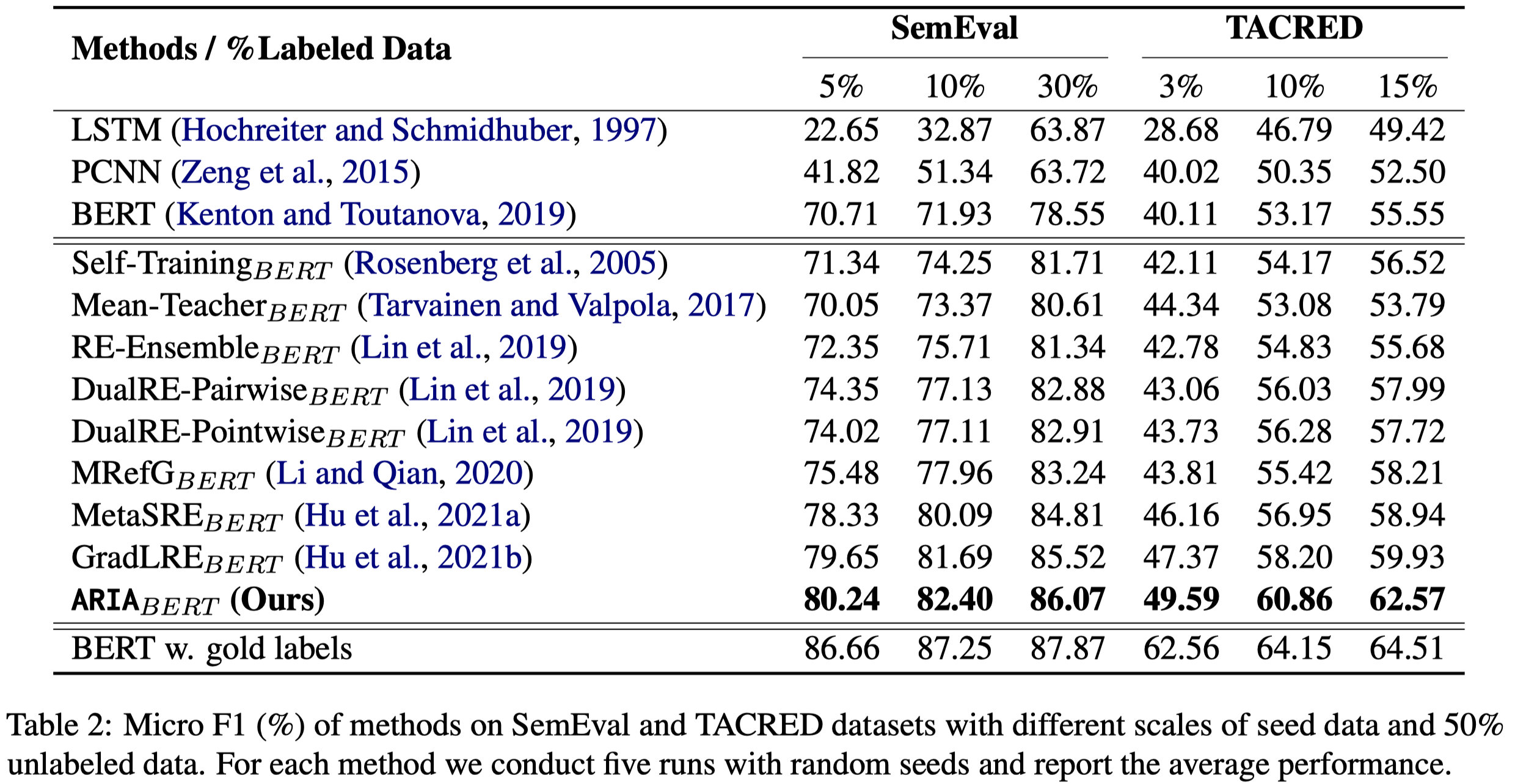
作者总结出来的rule示例:
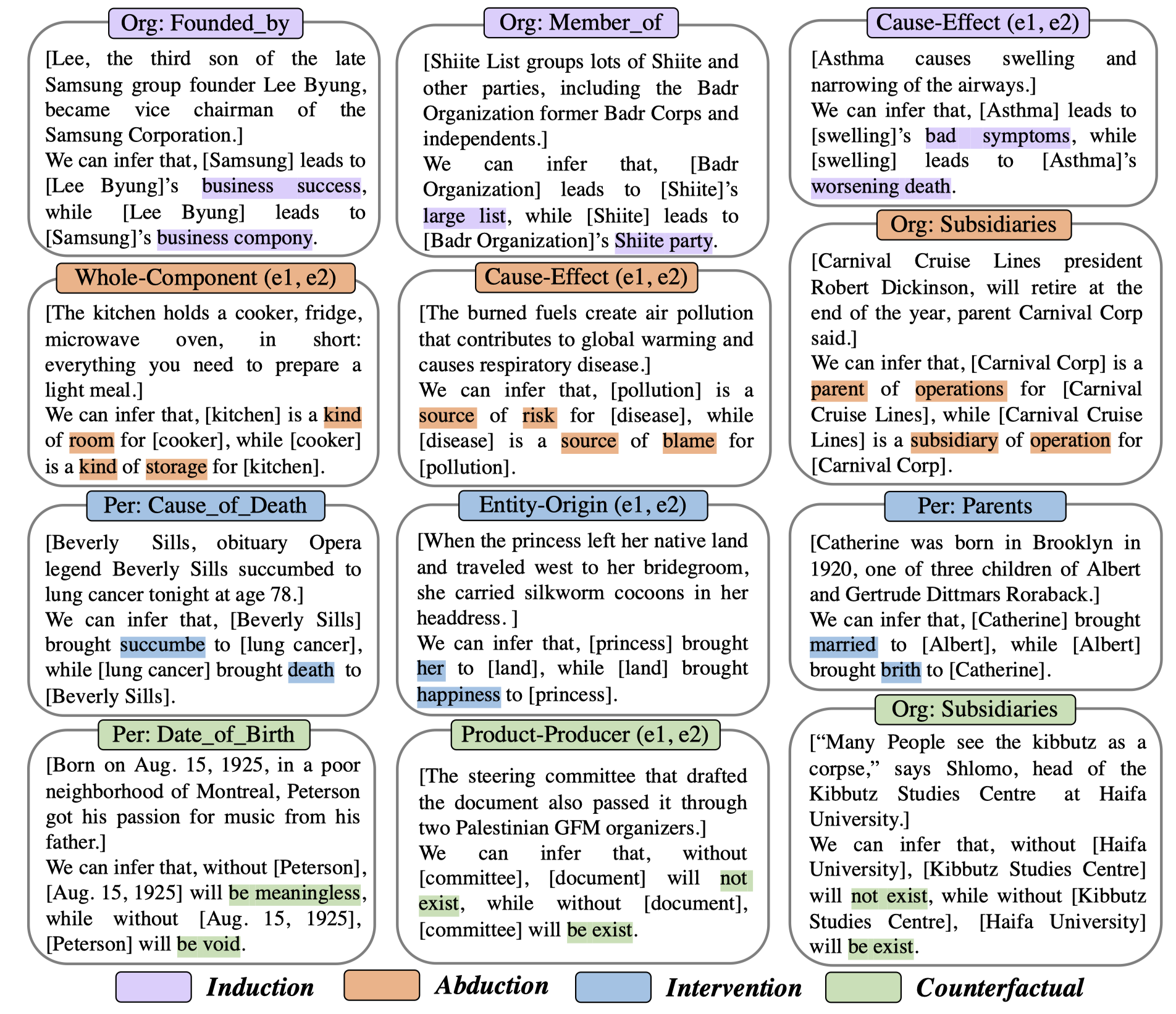
此外,作者还进一步利用了ChatGPT来替代PLM进行实验。下面是作者输入给GPT的生成rule的prompt:

为了利用rule,作者还尝试了将rule作为demonstration的一部分,来增强推理能力(ICL-R):

对于ICL和ICL-R,作者随机的从每个label寻找1个demonstration。利用GPT预测5次,然后进行majority voting。从SemEval (5%)实验结果来看,GPT作为rule generator并超越使用RoBERTa:
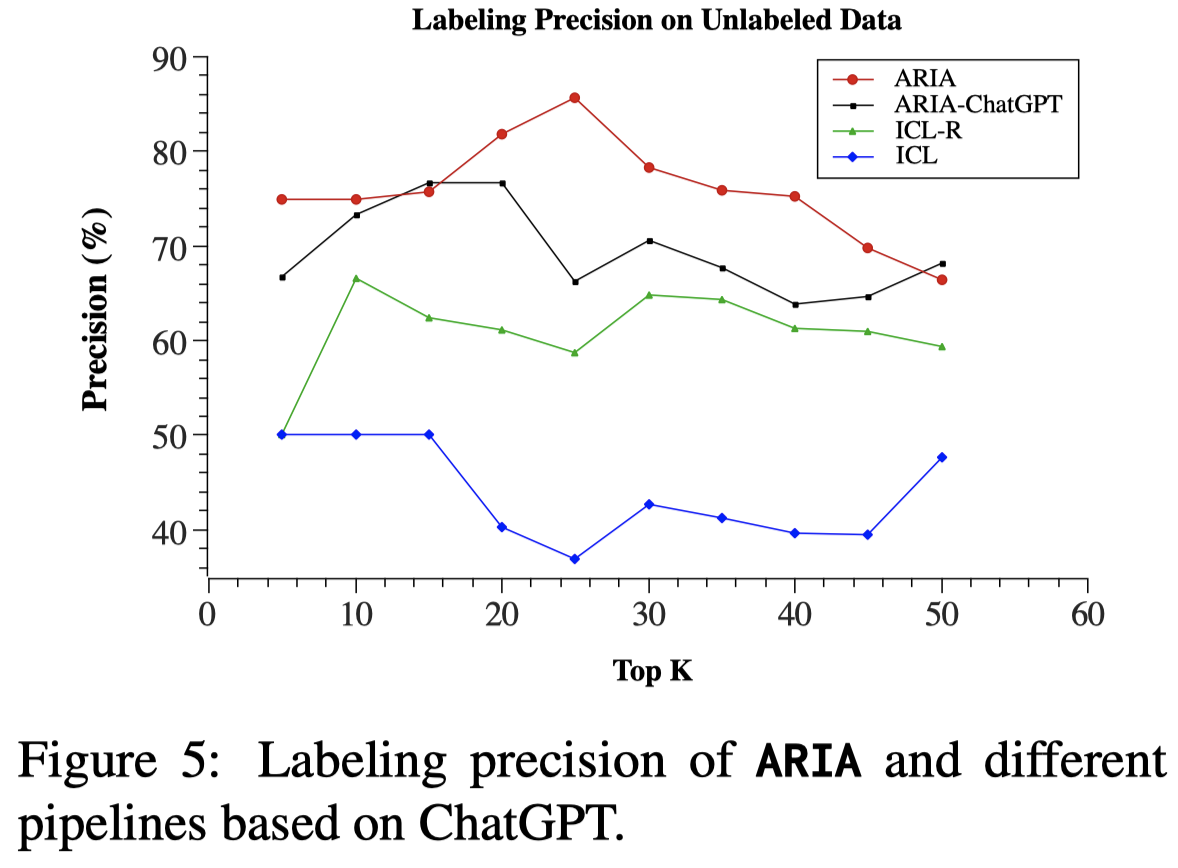
作者认为这是因为GPT的幻觉导致生成了不可信的rule,特别是在处理None关系的时候,会生成无意义的reasoning words。反而RoBERTa生成了有意义的words。此外,把推理出来的rule和demonstrations结合起来,比原始的ICL提升了20%的效果。
Boostrapping rule
Bootstrapping Neural Relation and Explanation Classifiers. University of Arizona. ACL 2023 Short. 代码.
We introduce a method that self trains (or bootstraps) neural relation and explanation classifiers. Our work expands the supervised approach of (Tang and Surdeanu, 2022), which jointly trains a relation classifier with an explanation classifier that identifies context words important for the relation at hand, to semisupervised scenarios. In particular, our approach iteratively converts the explainable models’ outputs to rules and applies them to unlabeled text to produce new annotations. Our evaluation on the TACRED dataset shows that our method outperforms the rule-based model we started from by 15 F1 points, outperforms traditional self-training that relies just on the relation classifier by 5 F1 points, and performs comparatively with the prompt-based approach of Sainz et al. (2021) (without requiring an additional natural language inference component).
作者的方法是一种neuro-symbolic+boostrapping的方法:
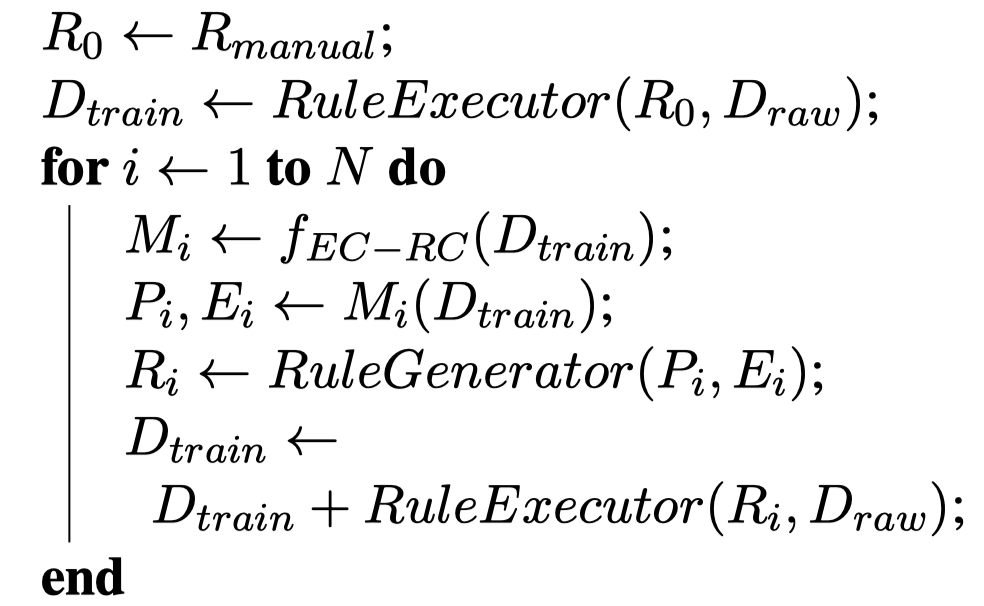
作者假设一开始没有训练集,但是保留了1%的验证集。随后,利用人工写的rules,从Tang et al. [It Takes Two Flints to Make a fire: Multitask Learning of Neural Relation and Explanation Classifiers.]创造的rules作为初始集合。
其rule是a combination of the surface patterns of Angeli et al. (2015), and syntactic rules written in the Odin language (ValenzuelaEscárcega et al., 2016)。举例为:if predicate=born and nsubj is PERSON and nmod_in is CITY then relation=per:city_of_birth.。
平均每个relation有7个rules。Tang et al. 论文中报告的,创造这些rule不需要特别大的人工,一个人几个小时内可以完成。
有了初始rules之后,作者基于Odin系统执行rule,创造出有标注数据集。这个有标注数据集被用来训练a relation classifier (RC)和an explanation classifier (EC),依旧是follow了Tang et al. 的方法。EC分类器用于判断每个word是否对于预测relation重要;RC分类器根据EC识别的重要word对应的embedding,进行关系分类。
关系生成器,是基于EC和RC的输出,(a) connecting the EC output to the trigger of the rule; (b) generating subject and object arguments that are connected to the trigger through the shortest syntactic dependency path, and (c) assigning the RC output (the label) to this syntactic pattern.
生成的rule会在1%的验证集上验证,如果准确率低于0.5,会被丢弃。
实验结果:
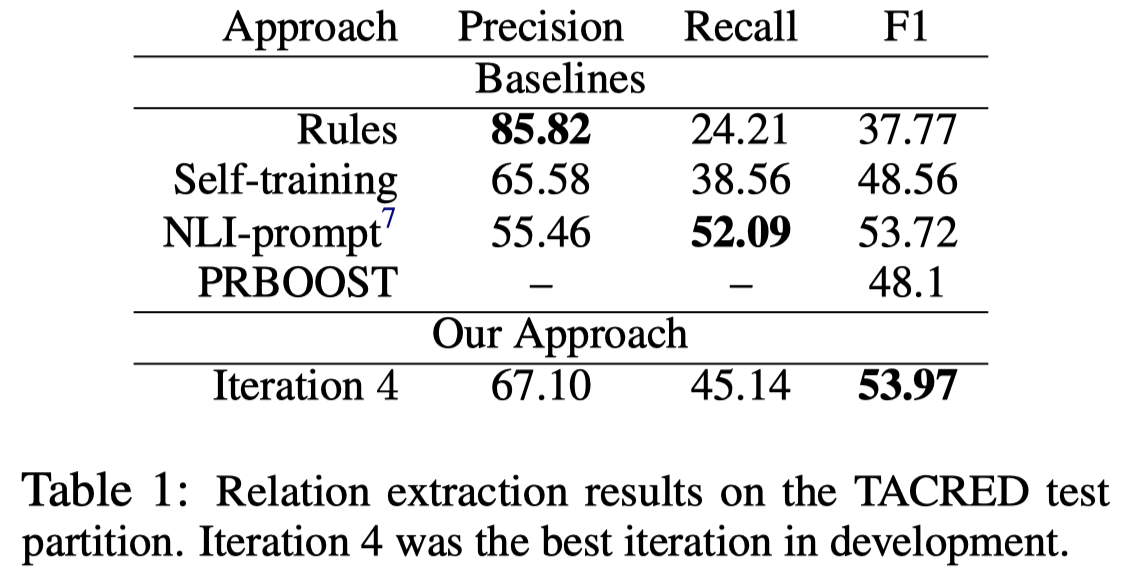
GLaRA
GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition. 密歇根大学. EACL 2021. 代码.
Instead of using expensive manual annotations, researchers have proposed to train named entity recognition (NER) systems using heuristic labeling rules. However, devising labeling rules is challenging because it often requires a considerable amount of manual effort and domain expertise. To alleviate this problem, we propose GL A RA, a graph-based labeling rule augmentation framework, to learn new labeling rules from unlabeled data. We first create a graph with nodes representing candidate rules extracted from unlabeled data. Then, we design a new graph neural network to augment labeling rules by exploring the semantic relations between rules. We finally apply the augmented rules on unlabeled data to generate weak labels and train a NER model using the weakly labeled data. We evaluate our method on three NER datasets and find that we can achieve an average improvement of +20% F1 score over the best baseline when given a small set of seed rules.
Issue:NER的模型训练需要大量标注数据。最近有工作讨论通过利用启发式规则,来获取更多weak labels。但是人工编码rules是很困难的,
Devising accurate rules often demands a significant amount of manual effort because it requires developers to have deep domain expertise and a thorough understanding of the target data.
Solution:作者基于少量的seed rules,从大量的无标注数据中获得更多rules。核心思想是如果两个rules能够match同一类的entities,那么这两个rules是语义相似的:
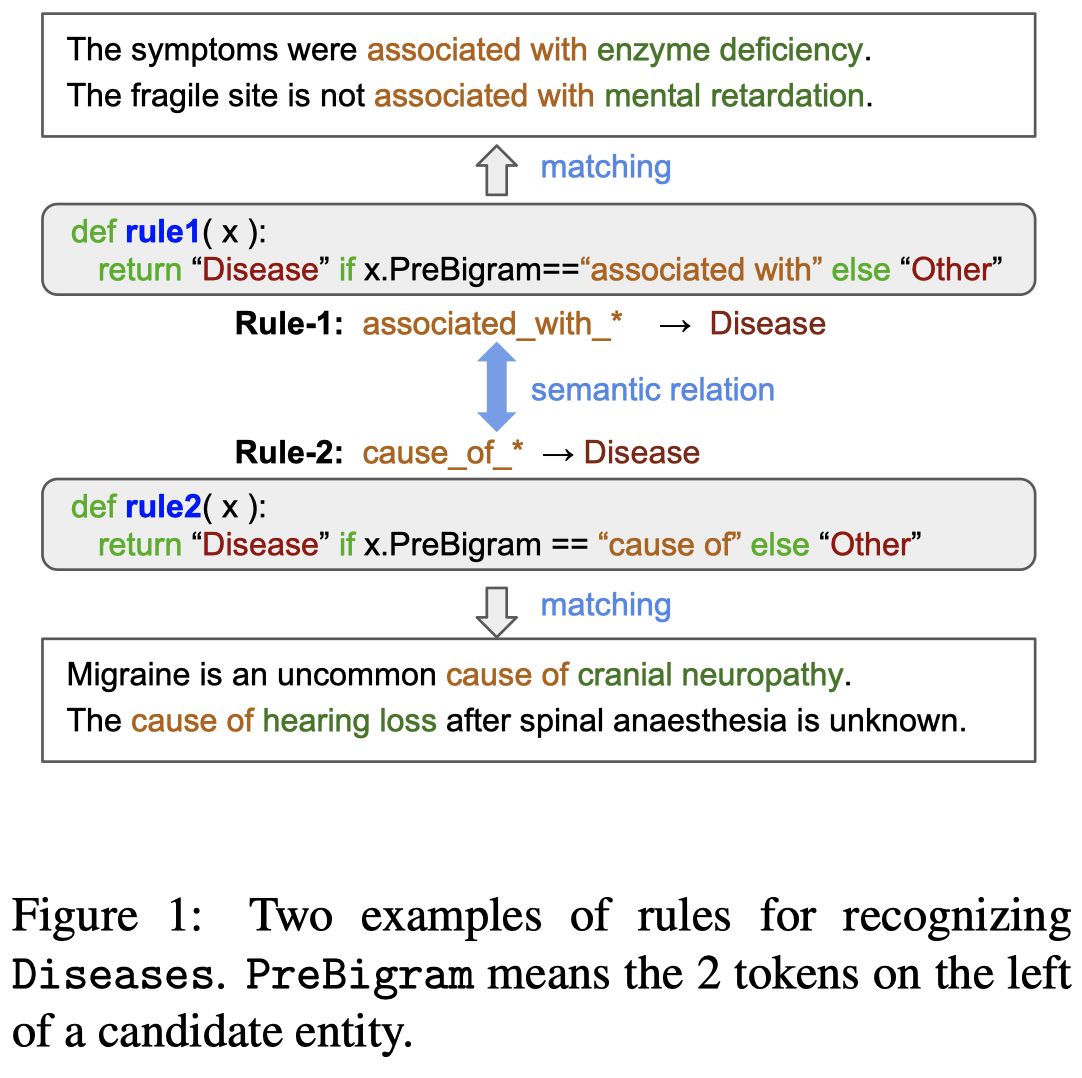
作者的方法图:

一开始,作者的seed rules是来自于Safranchik et al. (2020) [Weakly supervised sequence tagging from noisy rules. AAAI 2020]总结的rules,以及部分作者人工写的rules。统计如下表:
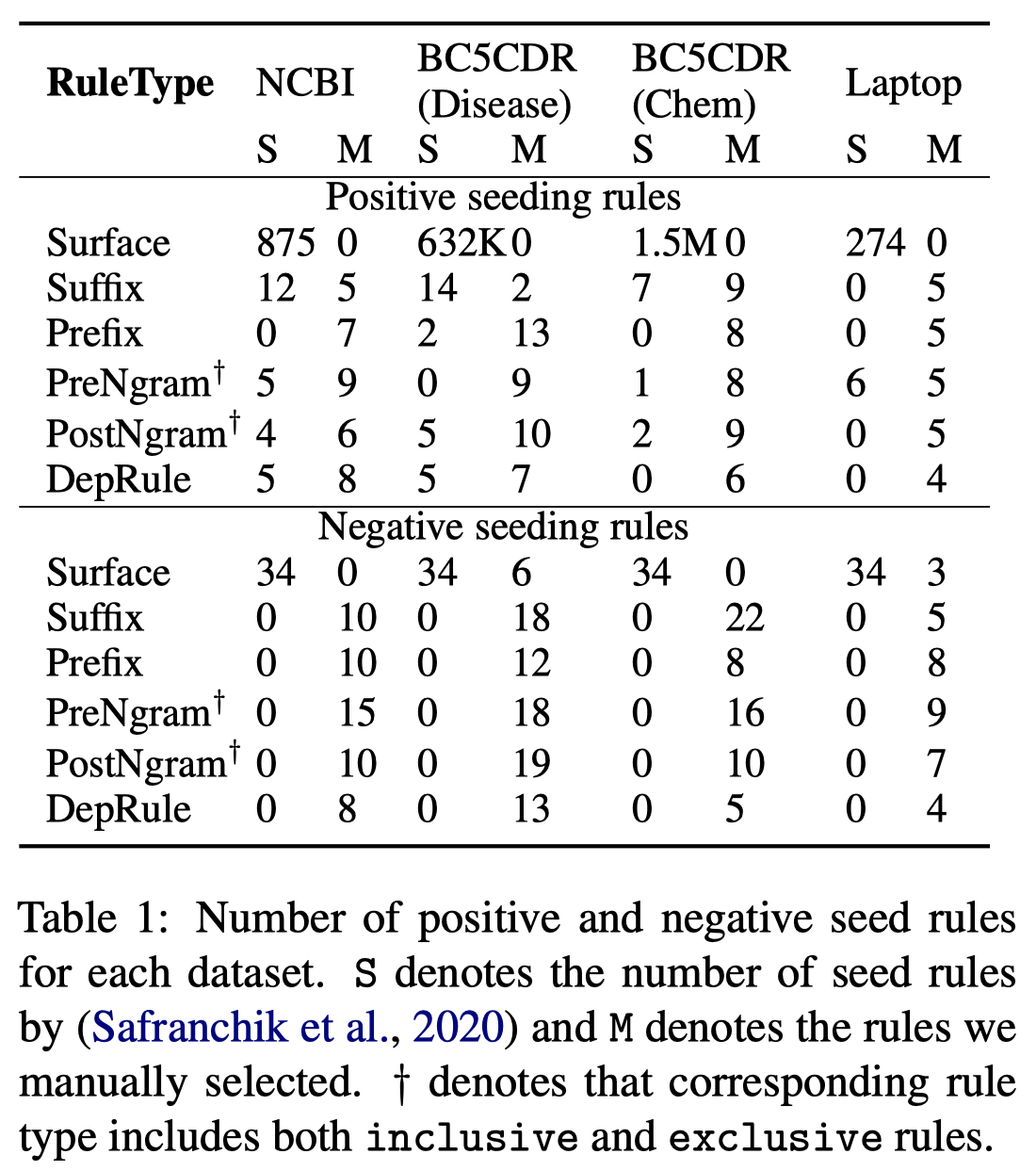
作者定义的rules,主要从lexical, contextual, and syntax三个层面考虑。作者首先从某个unlabeled instance中,通过词性标注POS,找到名词短语noun phrases,作为candidate entity mentions。(这里没有提到到底是如何确实这个entity mention应该属于哪一类entity type?)词性标注使用的patterns是包括JJ? NN+,JJ表示形容词,NN表示名词;以及在development set中15个entity mentions出现最频繁的patterns。
以名词短语作为候选entity,然后构造作者定义的\(6\)种rules:

具体每种rule的定义,参考论文。上面的rules是positive rules,能够分类到某一类具体的entity type。实际上,作者还定义了negative rules,用来判断候选entity不是某一类具体实体类型,属于Other class。但是论文中没有给出具体的说明。
为了判断这些从unlabeled instances中构造出来的rules到底是否成立。作者将seed rules和构造的新rules构造起来,通过统计rule embeddings之间的相似度(rule embedding是通过取所有能够被该rule match的entity mentions的平均ELMo向量取得),构造了一个rule graph。在rule graph上训练GAT网络,拟合能够预测seed rules是positive还是negative。最后,利用训练好的GAT,给每一个新构造的rule一个新的表征,这个表征用来判断新rule到positive和negative rule中心点的相似度距离,然后排序,选择距离positive最近的新rule作为新的positive rule。具体公式参考paper。
为了解决多个rules用于在unlabeled data上进行标注时出现的冲突问题,作者用了个LinkHMM模型。
作者的实验使用了NCBI、BC5CDR、LaptopReview三个数据集。这三个数据集的实体type都很少。
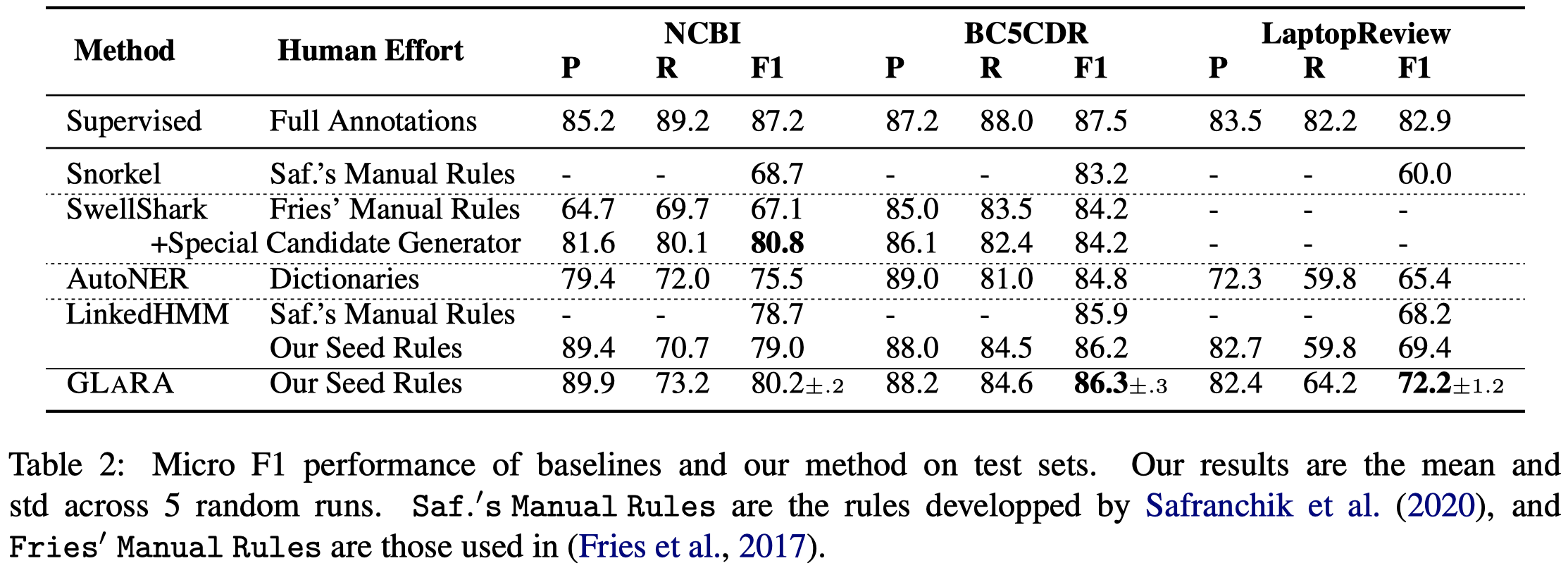
下面是作者方法学习到的rules示例:

Logical Rule for Triple Extraction
Integrating Deep Learning with Logic Fusion for Information Extraction. 南洋理工大学. AAAI 2020.
Information extraction (IE) aims to produce structured information from an input text, e.g., Named Entity Recognition and Relation Extraction. Various attempts have been proposed for IE via feature engineering or deep learning. However, most of them fail to associate the complex relationships inherent in the task itself, which has proven to be especially crucial. For example, the relation between 2 entities is highly dependent on their entity types. These dependencies can be regarded as complex constraints that can be efficiently expressed as logical rules. To combine such logic reasoning capabilities with learning capabilities of deep neural networks, we propose to integrate logical knowledge in the form of first-order logic into a deep learning system, which can be trained jointly in an end-to-end manner. The integrated framework is able to enhance neural outputs with knowledge regularization via logic rules, and at the same time update the weights of logic rules to comply with the characteristics of the training data. We demonstrate the effectiveness and generalization of the proposed model on multiple IE tasks.
Issue:作者认为现有的DNN方法用于信息抽取存在两个问题:
- the complex networks make learning harder when the amount of training data is insufficient. 需要大量训练数据
- the automation in DNNs makes it challenging to inject prior knowledge to guide the training process. 很难将先验知识注入到DNN的训练过程
Solution:作者认为symbolic logic systems provide an effective way to express complex domain knowledge in termcs of logic rules and have proven to be advantageous when data is scarce. 因此,作者考虑将DNN和logical rules结合在一起。
作者的方法图:
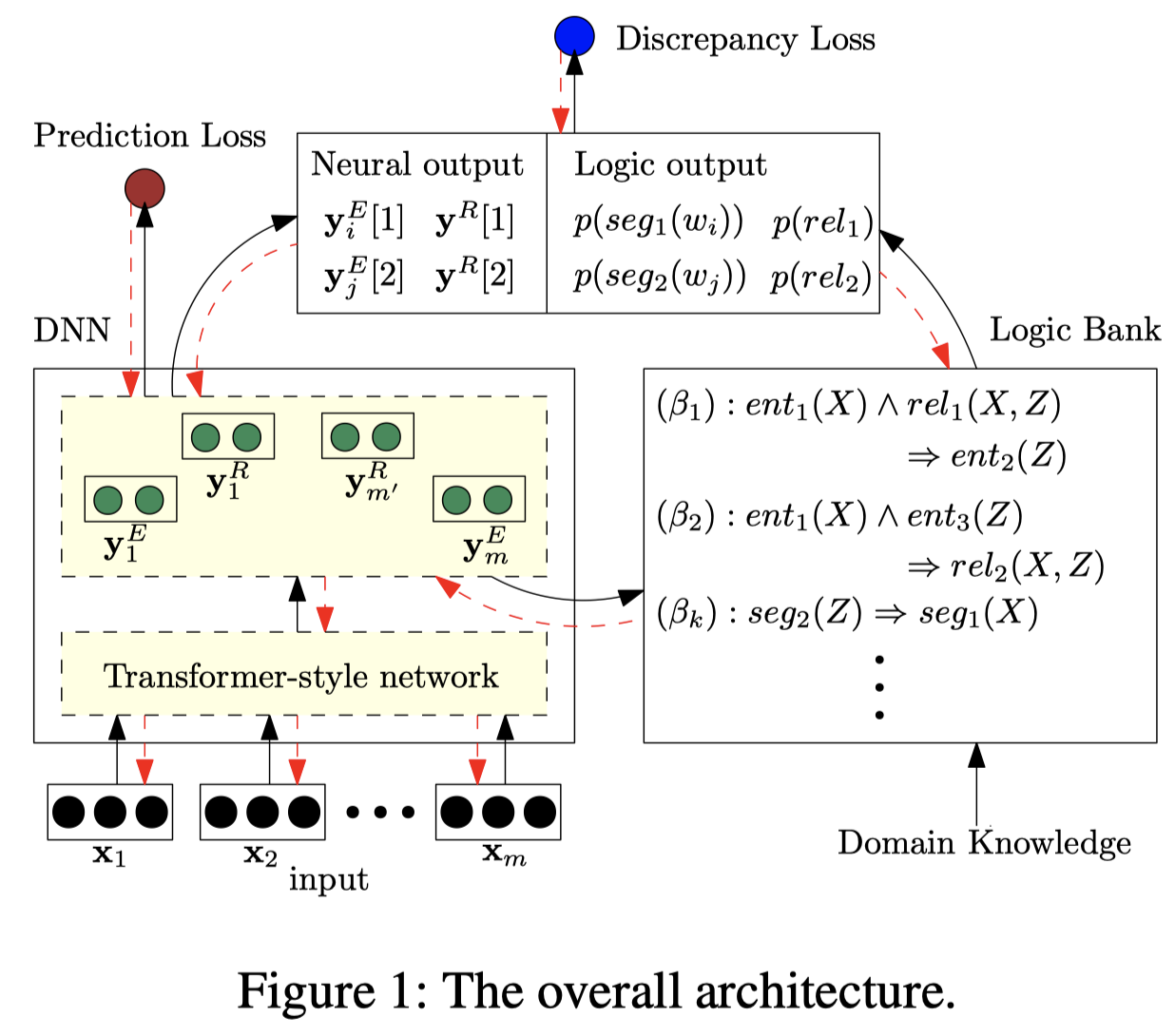
作者的logical rules采用一阶逻辑的形式。对于三元组抽取来说,主要用一阶逻辑来建模标签之间的依赖关系。作者提出了两种一阶逻辑:
- The first type focuses on the dependencies of segmentation labels. 如\(seg_b(Z) \Rightarrow seg_a(X)\) ,\(a,b\)是NER label \(\{B,I,O\}\)。用来表示NER label之间的依赖,比如\(seg_B(w_i) \Rightarrow seg_O(w_{i-1})\),指\(B\)之前的label一定是\(O\)。
- The second rule models the correlations between entity types and relations, e.g. \(entity_{c}(X) \wedge rel_l(X,Z)\Rightarrow entity_d(Z)\)表示头尾实体之间的label依赖。
作者的方法包括了基于Transformer架构的DNN module,以及一阶逻辑模块。一阶逻辑模块会输入DNN的输出,然后生成自己的输出;DNN的输出会和logical rules的输出进行度量。具体参考论文。