GNN-Collection
Collection of GNN papers
- Highway GNN(ACL 2018)
- HGSL(AAAI 2021)
- HGAT(EMNLP 2019)
- HetGNN(KDD 2019)
- HetSANN (AAAI 2020)
- RHINE(AAAI 2019)
- JK(ICML 2018)
- PATHCON(KDD 2021)
- HeteGNN(WSDM 2021)
- KGNN(IJCAI 2020)
- CPRL(NAACL 2021)
- CLHG(ACL 2021)
- EAGCN(Neurocomputing)
- ETGAT(ACL-IJCNLP 2021)
- GAEAT(CIKM 2020)
- M-GNN(IJCAI 2019)
- RDGCN(IJCAI 2019)
- SLiCE(WWW 2021)
- M2GNN(WWW 2021)
- LGNN(IJCAI 2021)
- RevGNN(ICML 2021)
Highway GNN
Semi-supervised User Geolocation via Graph Convolutional Networks ACL 2018
应用场景是社交媒体上的用户定位。单纯的在GNN上的创新点是使用Gate机制来控制传入的邻居的信息。
在每一层,借鉴Highway networks的思路,计算一个门weight
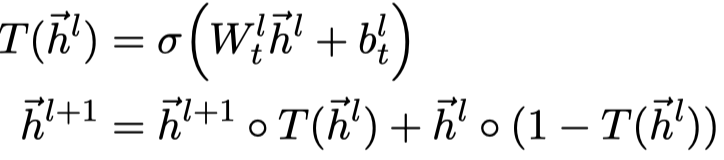
HGSL
Heterogeneous Graph Structure Learning for Graph Neural Networks AAAI 2021
[详细博客]作者声称是首个尝试为异质图神经网络寻找最优的图结构进行学习的方法,提出了HGSL(Heterogeneous Graph Structure Learning)。核心方法有两个,异质图结构学习和图神经网络。
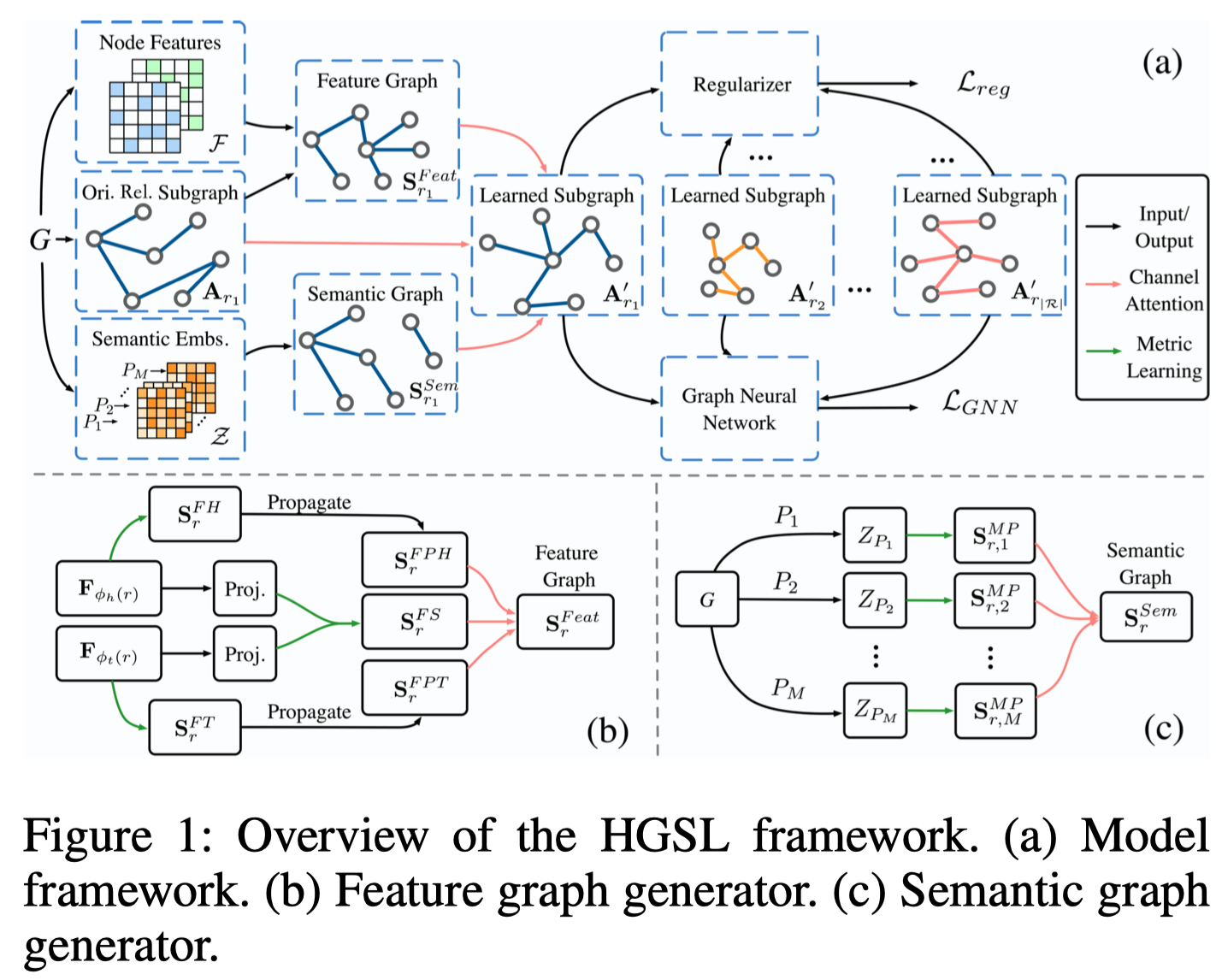
motivation:目前的异质图神经网络基于一个假设,学习使用的graph是足够好的。但是实际上这个假设不一定总能够满足。两个方面的原因,(1)在建模graph的时候,使用到的信息难免会包含错误的信息,导致最终的graph是不够好的(2)另一个原因是异质图结构本身与下游任务是独立的,不一定是有利于下游任务的最优解。为了解决上面的问题,图结构学习graph structure learning (GSL)被提出来,但是这些方法主要是在考虑同质图,无法很好的考虑异质图中的异质性以及异质图中存在的复杂的交互。
method:提出HGSL,首先学习合适的graph structure,然后在这个graph structure上使用GCN进行学习。这种heterogeneous graph structure learning是核心创新点,包括三种graph的融合,feature similarity graph,feature propagation graph,和semantic graph。
HGAT
Heterogeneous Graph Attention Networks for Semi-supervised Short Text Classification EMNLP 2019
为短文本分类任务(semi-supervised short text classification)设计了一个异质图神经网络HGAT。
首先是利用原始文本构造一个异质图(HIN),把不同来源的文本组合到一起。

重点在于,其中的node type各不相同,各自具有差异性很大的特征。
然后是设计的网络结构,重点在于设计了一个两层的attention。
不同type的node有不同的卷积核:

然后,type-level的attention,聚合邻居下所有相同type的node embedding,然后计算attention weight。这样同一type下的所有neighbor node共享一个type level的weight。
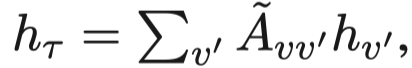

不同type之间softmax。
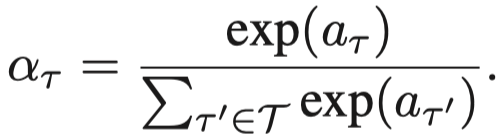
然后是node-level的attention,不同邻居node,计算attention。
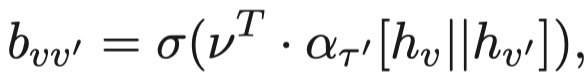
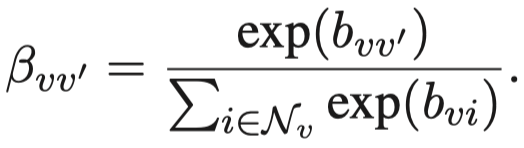
最后结果:
HetGNN
Heterogeneous Graph Neural Network KDD 2019
作者提出了一种同时处理node content和heterogeneous graph structure的GNN,HetGNN。
看一下整体结构:

核心模块有三方面:
Sampling Heterogeneous Neighbors:使用了random walk with restart (RWR)的邻居采样策略,需要注意的是这个采样策略保证对于node \(v\),能够采样到所有不同类型的邻居。然后相同类型的邻居聚合到一起。

Encoding Heterogeneous Contents:对于不同格式的content,使用不同的网络进行处理,然后使用Bi-LSTM进行融合,不同type的node有自己的Bi-LSTM网络。

Aggregating Heterogeneous Neighbors:对于相同类型的邻居,先基于Bi-LSTM进行聚合。然后不同类型的邻居基于attention进行聚合。
HetSANN
[个人详细博客]An Attention-based Graph Neural Network for Heterogeneous Structural Learning AAAI 2020 HetSANN
提出了Heterogeneous Graph Structural Attention Neural Network (HetSANN),主要创新点有三个:
- 对于预测标签任务,采用多任务学习,不同type的节点进行预测有不同的classifier(实际是全连接层+softmax)
- 针对edge和reversed edge,除了一般的基于拼接的方法计算attention外,提出了voice-sharing product的计算注意力方法。
- 在不同type的邻居信息转换中,提出了一个保持weight matrix的cycle consistent的方法。
看一下模型的整体结构:
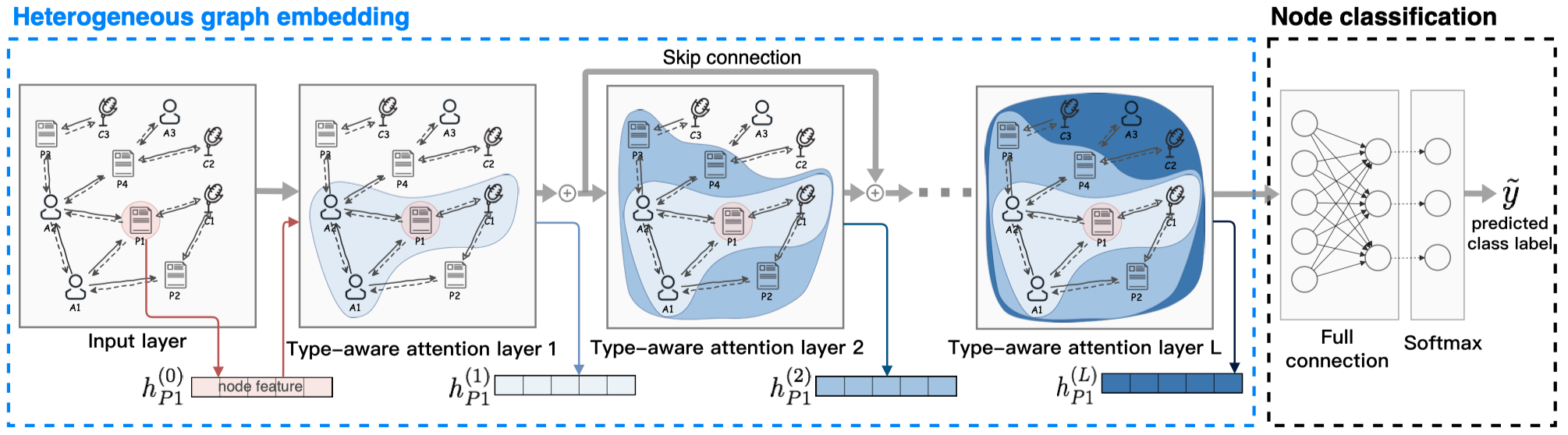
核心是一个注意力层,TAL层如图所示。
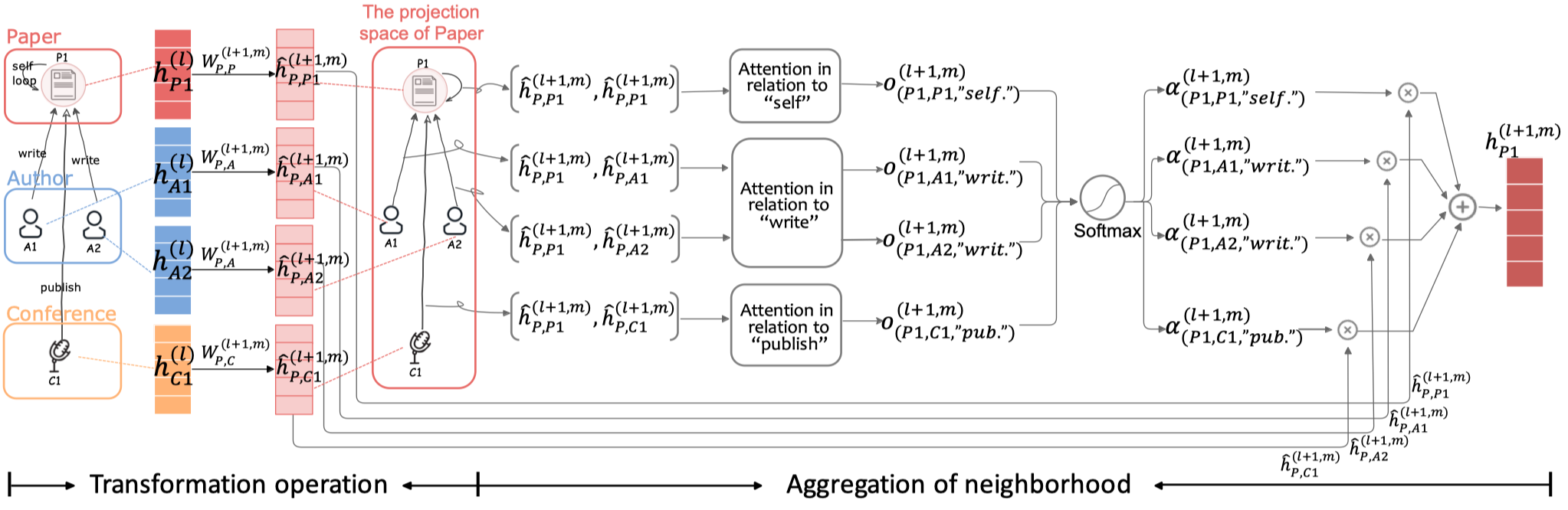
首先是基于type的邻居信息转化,node \(i\) 提供给node \(j\)。
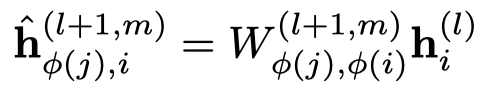
然后基于注意力聚合邻居信息,下面的是一般的GAT的方法,作者叫做concat product。
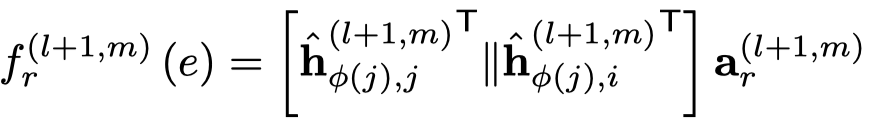
需要注意的是,这里的注意力向量\(\alpha_r\),是每个edge type各有一个。然后就是基于softmax的attention聚合。
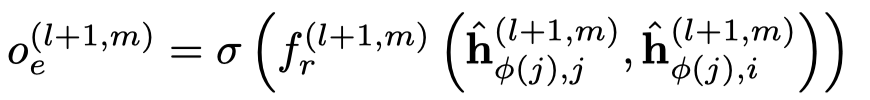
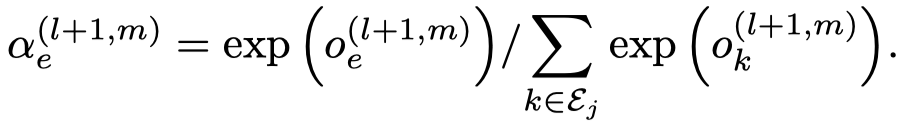
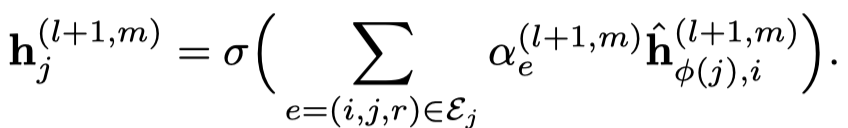
实际上,作者还提出了voice-sharing的注意力计算方法,主要是希望考虑关系和逆关系之间的对应联系。让注意力向量\(\alpha_r\)互为负数,然后利用相加计算注意力。详见博客。
RHINE
Relation Structure-Aware Heterogeneous Information Network Embedding AAAI 2019
这篇文章不是GNN领域的文章,但是由于它也尝试捕获relation在结构上的角色,所以干脆放到一起了。
它核心创新点是把所有的relation划分为了两类:
- Affiliation Relations (ARs):one-centeredby-another structures
- Interaction Relations (IRs):peer-to-peer structures
划分的依据是作者根据不同relation的头尾节点类型的平均数量比,对于关系\(<u,r,v>\):
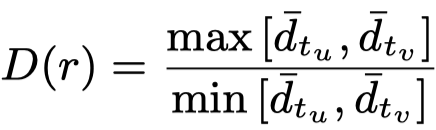
里面的\(\overline{d}_{t_u}\),\(t_u\)表示的是头节点\(u\)的类型,\(\overline{d}_{t_u}\)是指这一类型下的所有节点的平均度degree。在这样的网络中,能够确定某个relation两边的entity type,所以可以这样评估。但是在KG中,无法确定entity的type,也就无法这样计算。
\(D(r)\)比较小的划分为IR关系,\(D(r)\)比较大的划分为AR关系。
这样划分完之后,对于AR关系和IR关系使用两种不同的embedding model。
AR,直接评估两个点之间的欧氏距离。
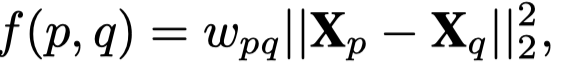
IR,借助TransE的思想,建模这种1-1的关系。
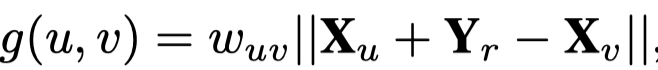
JK
Representation Learning on Graphs with Jumping Knowledge Networks ICML 2018
作者认为一般GCN模型实际假定了为不同的node都学习固定范围/半径的邻居信息,这种情况下不一定是最优解。比如通常GCN只需要两层就达到了最优解,但是对于一个graph来说,有的node可能是tree-like的,两层邻居也只包含了很少的邻居信息,而有的node是expander-like core,两层邻居就包含了非常多的邻居信息。比如下面的GooglePlus社交网络:
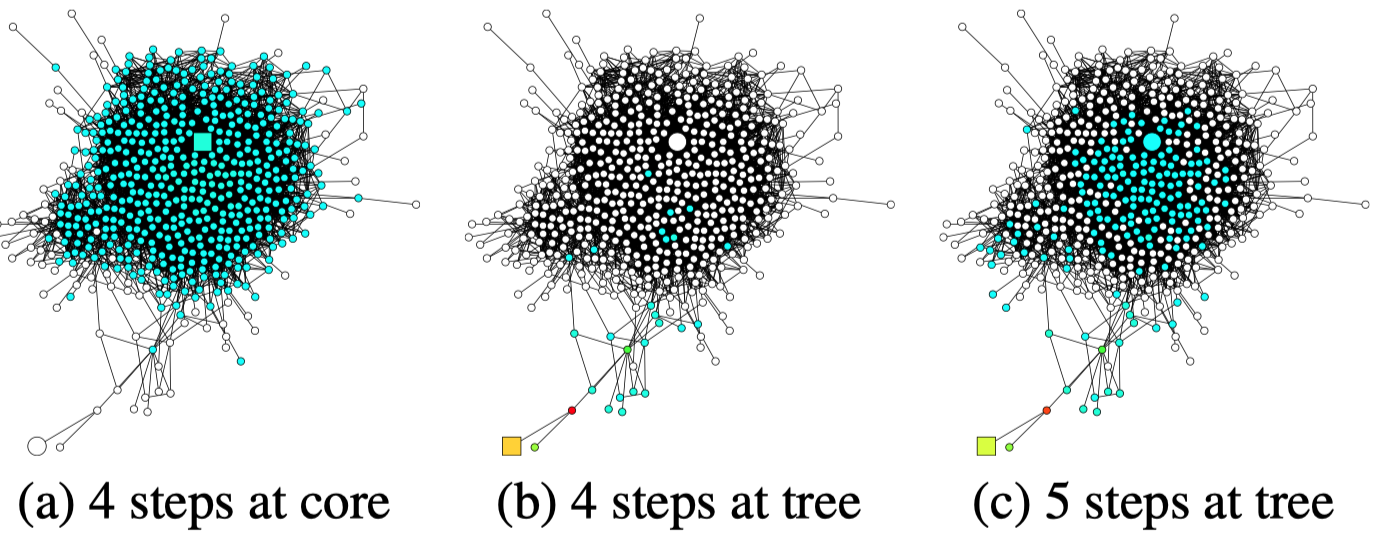
因此,作者希望设计一种方法能够实现adaptively adjust (i.e., learn) the influence radii for each node and task。提出了Jumping Knowledge Networks (JK-Nets)。
主要结构:

JUMP的意思是每一层输出都jump到最后一层,在最后一层进行layer aggregation。
作者提出三种方法
- Concatenation
- Max-pooling
- LSTM-attention:双向LSTM
简单的论文的实验结果看,前两个方法还不错,但是后面的LSTM-attention,效果并不好。通过使用前面的JK设计,作者能够在不同数据集下,基于更多更深的GCN层达到最好的结果。
PATHCON
Relational Message Passing for Knowledge Graph Completion KDD 2021
[个人详细博客]在这篇论文中,作者只考虑了KG中的relation embedding,没有学习entity embedding。更具体的说,学习两个方面的结构信息,relational context和relation paths。前者是头/尾实体的邻居relation,后者是头尾实体在KG中相连的relational path。提出了PATHCON
作者预测的是relation prediction,\(<h,?,t>\),区别于常见的head/tail prediction,这样情况下relation prediction的候选项是所有的relation,会少很多候选项。这篇文章,作者还提出了一个新的数据集,DDB14,基于医药和疾病的一个知识图谱。
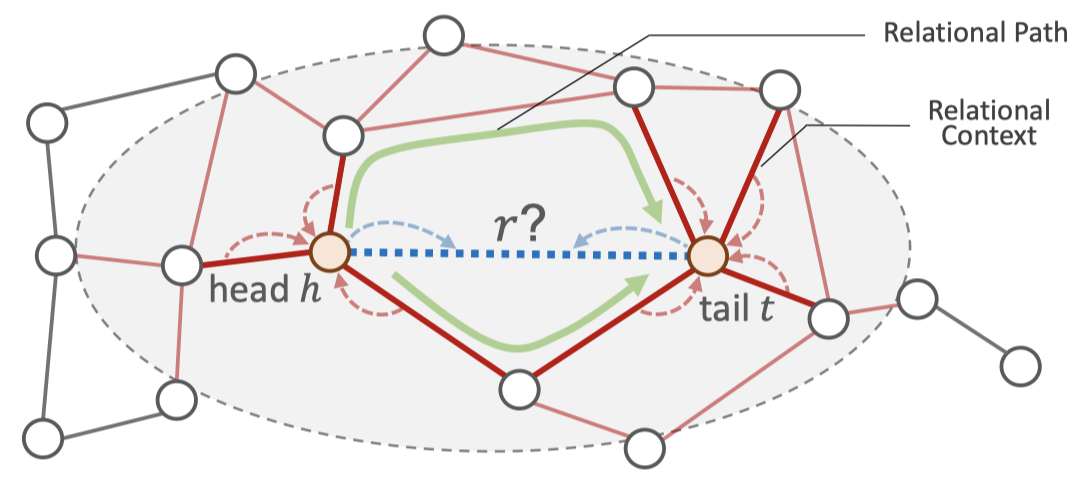
HeteGNN
HeteGCN: Heterogeneous Graph Convolutional Networks for Text Classification WSDM 2021
针对文本预测任务,简化TEXTGCN,将原来整个TEXTGCN中使用的graph分解为几个不同的小graph,每个graph有自己的\(W_r\)。

KGNN
KGNN: Knowledge Graph Neural Network for Drug-Drug Interaction Prediction IJCAI 2020
针对DDI问题(Drug-drug interaction),首先从数据集中构造一个关于drug的KG,然后使用GNN捕获drug的邻居信息。在GNN上没有太大的创新,发现在聚合的时候使用自身embedding与邻居embedding各自具有不同的weight matrix比较合适。
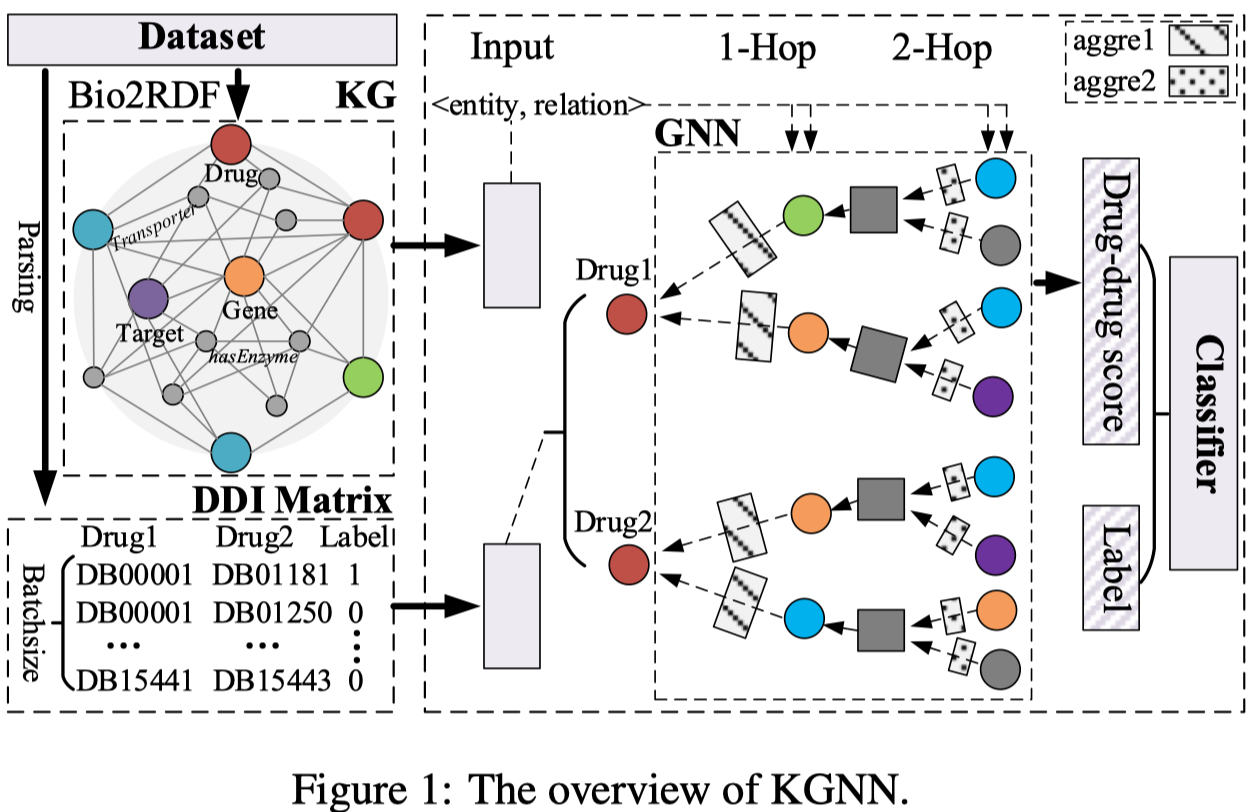
CPRL
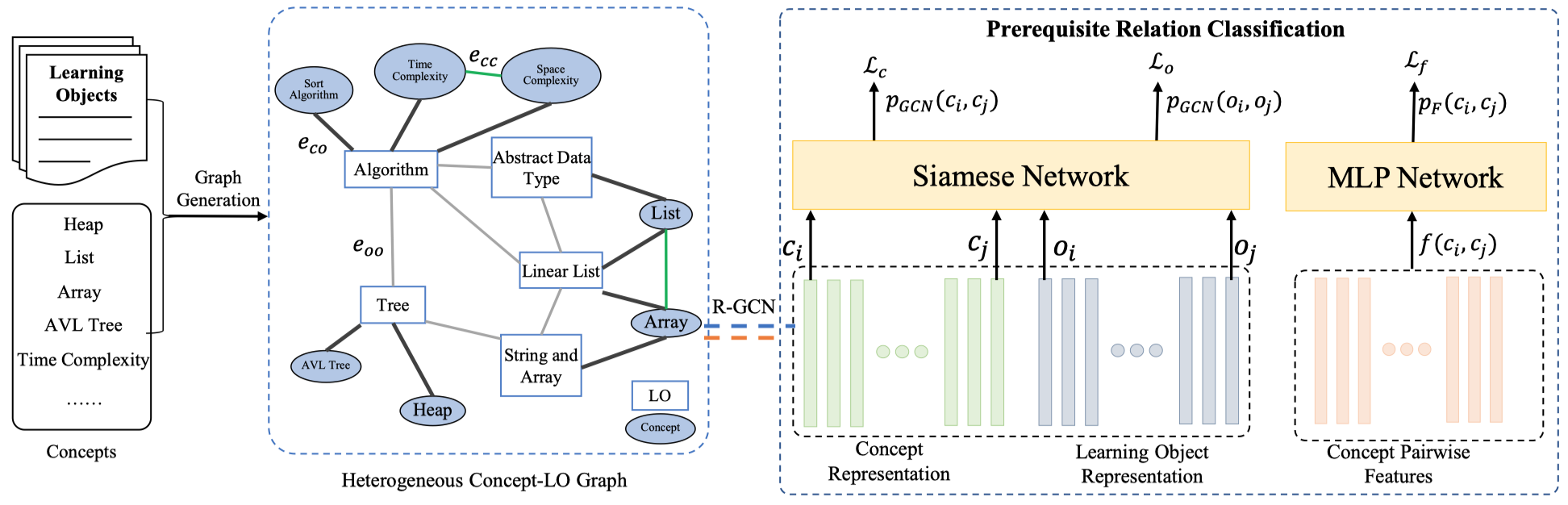
Heterogeneous Graph Neural Networks for Concept Prerequisite Relation Learning in Educational Data NAACL 2021
CPRL(concept prerequisite relation learning),在GNN上没有太大创新,主要是属于应用场景的一个创新。针对概念之间的依赖关系进行预测,作者创建了一个异质图,然后直接使用R-GCN进行学习,方法上没有太多可以借鉴的地方。
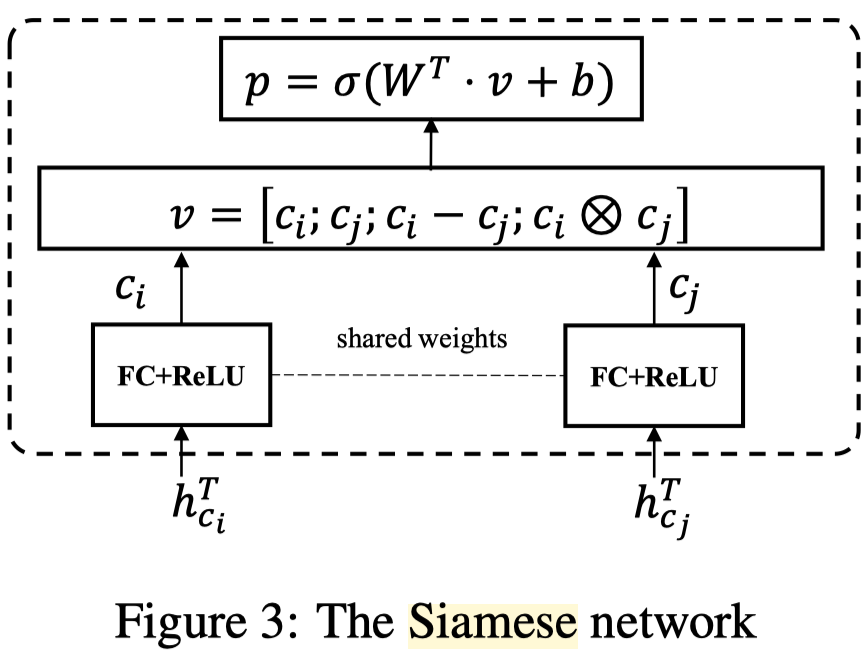
这里使用了一个Siamese network,以前没见过。
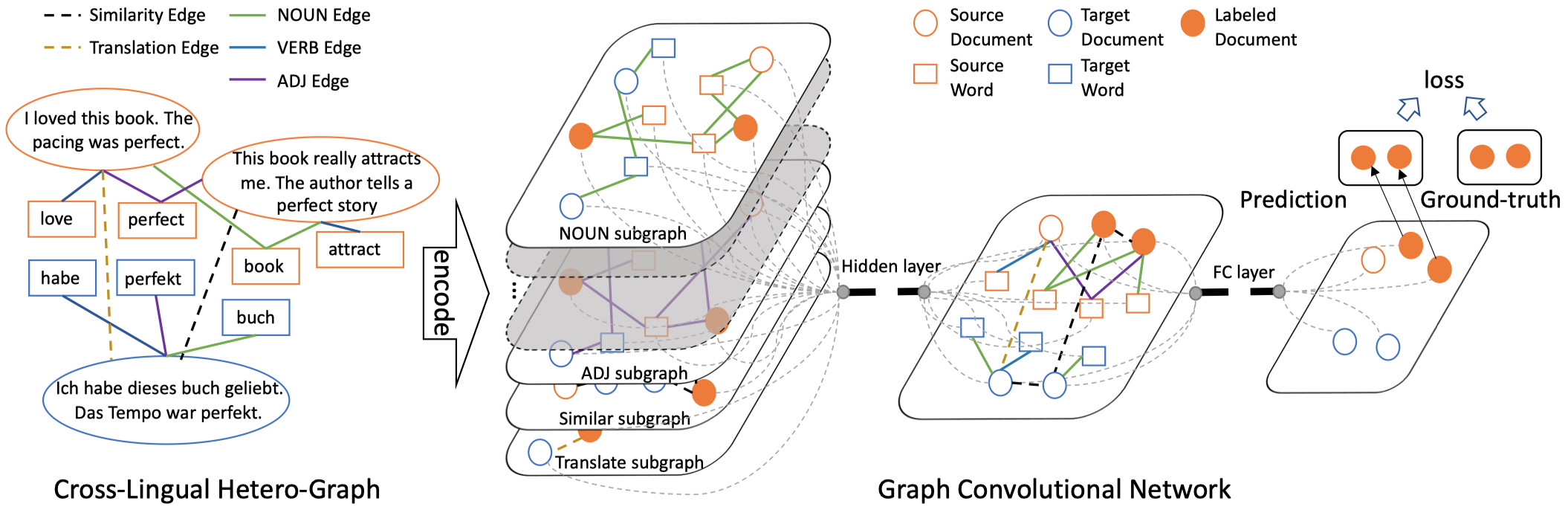
CLHG
Cross-lingual Text Classification with Heterogeneous Graph Neural Network ACL 2021
CLHG(Cross-Lingual Heterogeneous GCN),针对跨语言的文本分类任务,使用HGCN捕获不同语言的异质信息。这篇文章在GNN上没有太大创新,直接使用了前面HGAT的方法,根据邻居节点类型有不同的weight matrix。
EAGCN
Multi-view spectral graph convolution with consistent edge attention for molecular modeling Neurocomputing
EAGCN,预测任务是molecular graph property prediction,核心创新点个人认为是把异质图根据edge type分为不同view的graph,然后在molecular graph的背景下,同一个type的edge有不同的取值,这些取值会有不同的weight scalar。
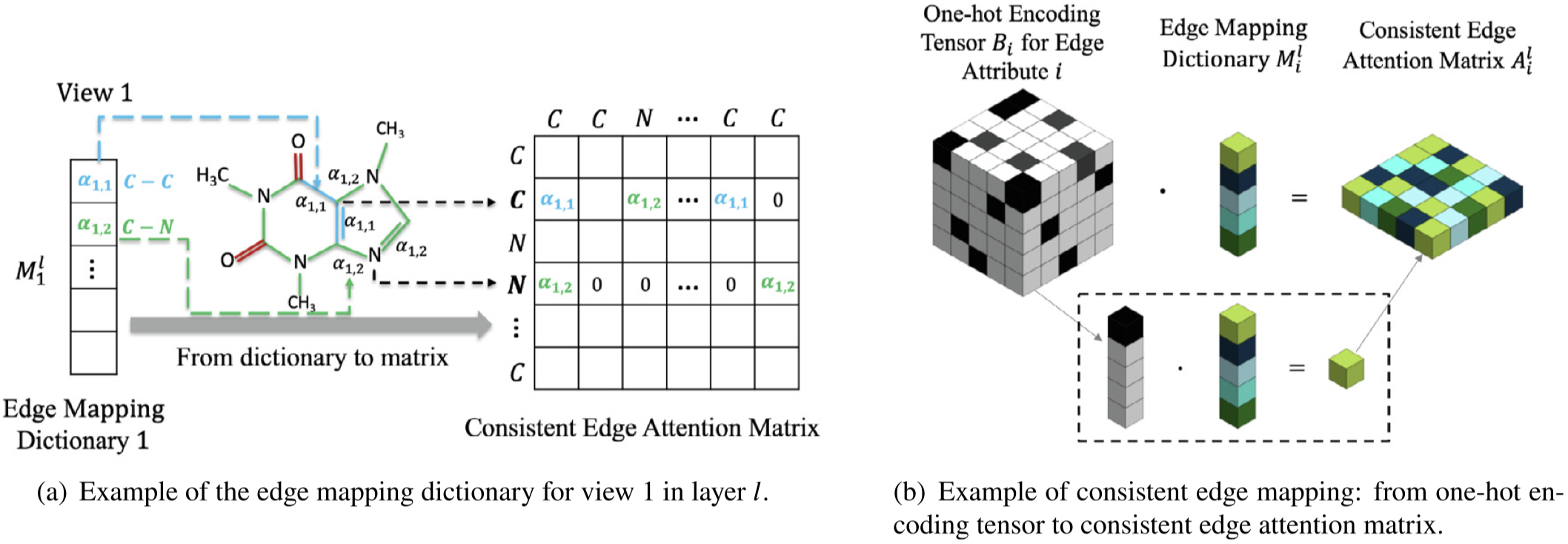
另外作者开源了项目,里面有attention的可视化这些操作,如果需要可以参考。
EIGAT
Incorporating Global Information in Local Attention for Knowledge Representation Learning ACL 2021
核心创新点在于建模KG中实体的重要性,为每个实体赋值一个实数scalar,然后根据邻居实体的重要性评估中心实体的重要性。
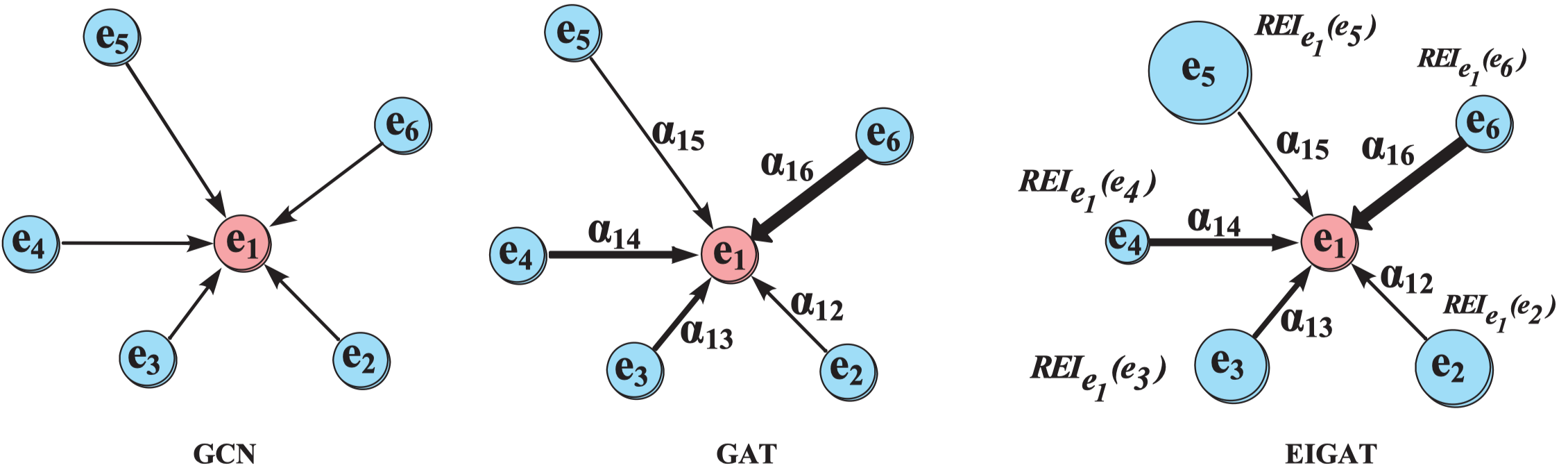
local attention
与KBGAT的方法一样。


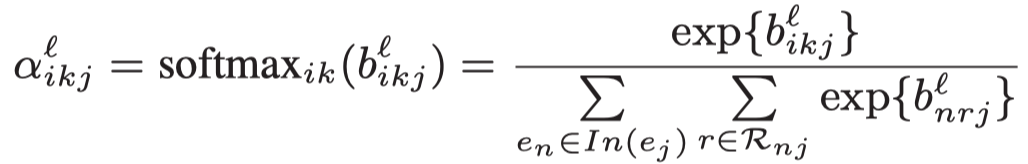
entity importance
核心创新点,
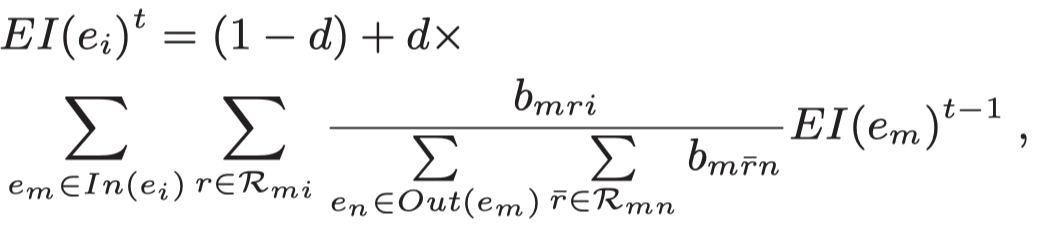
从in edge出发,聚合邻居的重要性,注意,这里融合了前面计算的message的重要性。每个邻居提供的重要性是相对于自身所有的out message重要性来计算的。
其中\(d\)是一个超参,第一项是为了给KG中没有in-degree的实体一个初始值。
在实验时,所有的\(EI\)初始化为0.1,\(d\)初始化为0.85。
最后,两种attention进行融合。

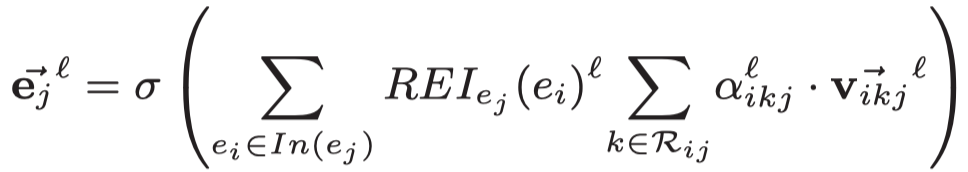
GAEAT
GAEAT: Graph Auto-Encoder Attention Networks for Knowledge Graph Completion CIKM 2020
CIKM的short track。实际没有什么创新,使用KBGAT作为编码器,然后DistMult作为解码器。不过可以作为对比的Baseline。

M-GNN
Robust Embedding with Multi-Level Structures for Link Prediction IJCAI 2019
[个人详细博客]这篇文章提出了一种multi-level graph neural network,M-GNN。使用GIN中的MLP学习结构信息,然后提出了一种基于KG中图的不同粒度进行建模的方法。它会从原始的KG出发,不断合并邻居节点,合并边,构造出一系列不同粒度的graph,在这些graph上进行图卷积操作,得到最后的输出。除了一般的链路预测实验,作者还进行了在不同稀疏度以及加入noising edges的实验。
和一般的GNN消息聚合方式不同,M-GNN希望能够建模KG中不同尺度中的信息。
首先构造k个Coarsened graph:

 最后模型结构。
最后模型结构。
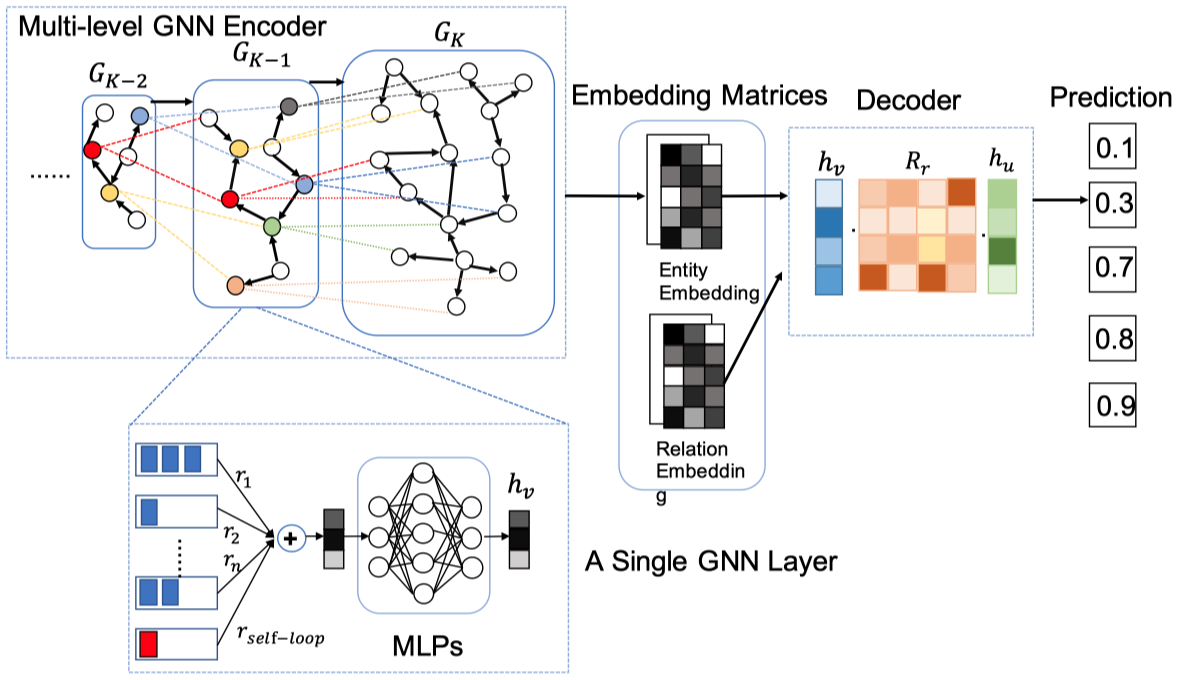
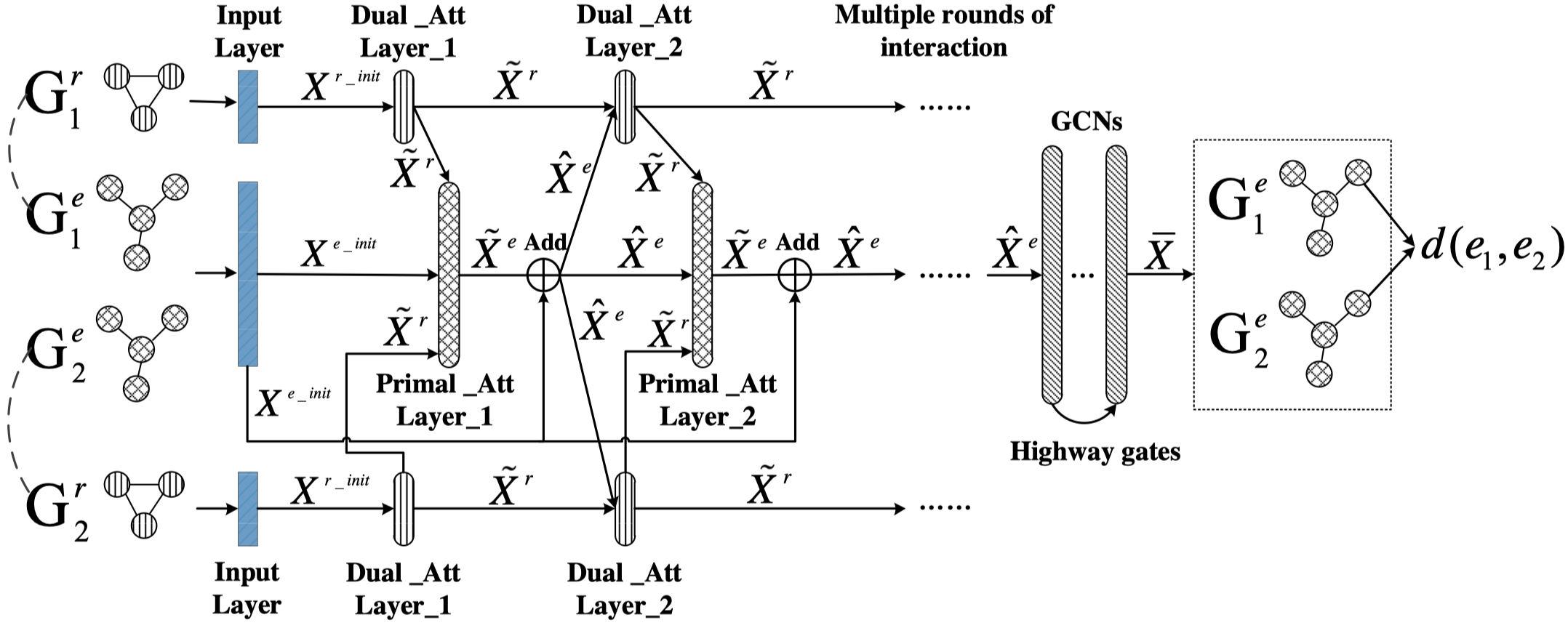
RDGCN
Relation-Aware Entity Alignment for Heterogeneous Knowledge Graphs IJCAI 2019
Post not found: gnn/RDGCN [个人详细博客]RDGCN (Relation-aware Dual-Graph Convolutional Network),预测任务是KG的实体对齐,主要是为了捕获更多的在dual KG中的relation的信息。核心创新点是对于dual KG(即要对齐的两个KG),构造了Dual Relation Graph,捕获relation和relation之间的联系。之后在这个Dual Relation Graph上学习relation的表示,融入到original KG中进行entity的表示学习,最终用于entity之间的对齐。
SLiCE
Self-Supervised Learning of Contextual Embeddings for Link Prediction in Heterogeneous Networks WWW 2021
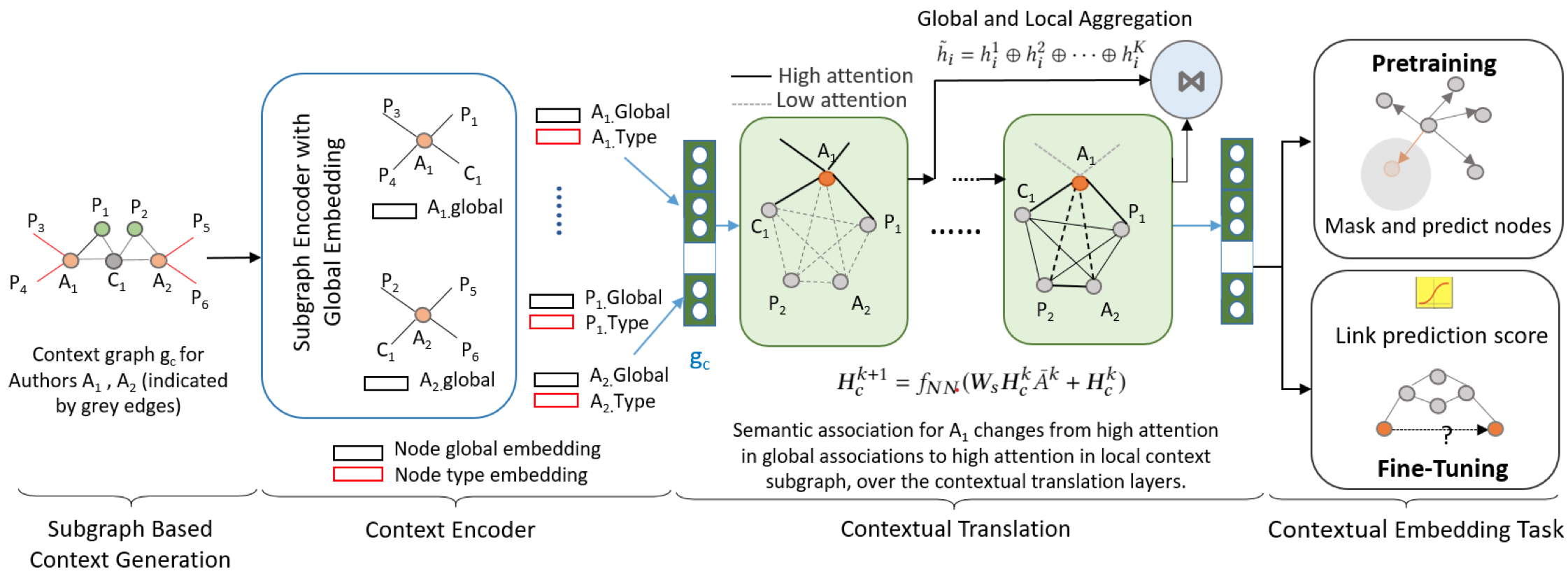
作者希望考虑的是,单个节点在特定的subgraph下的表示。对于节点对,利用随机游走寻找两个节点之间的context subgraph。首先,利用一个embedding function,在全图下学习每个node的初始表示,作为global embedding。
然后,有两个阶段,pre-training和Fine-tuning。pre-training预测被mask掉的node,fine-tuning进行link prediction。

M2GNN
Mixed-Curvature Multi-Relational Graph Neural Network for Knowledge Graph Completion WWW 2021
首个将mixed-curvature geometry与GNN联系起来学习KGE的方法,作者尝试利用不同的空间对KG中的异质性结构进行建模。但是由于对mixed-curvature space和manifold不了解,看不懂论文内容。之后可以找时间仔细补充下基本知识。可参照
John M Lee. 2013. Smooth manifolds. In Introduction to Smooth Manifolds. Springer, 1–31.
LGNN
Node-wise Localization of Graph Neural Networks IJCAI 2021
作者认为对于整个图学习同样的weight matrix,可能导致模型倾向于建模最常见的pattern,而不是针对不同node的不同的local context进行学习。作者让graph中不同node拥有不同的weight matrix。
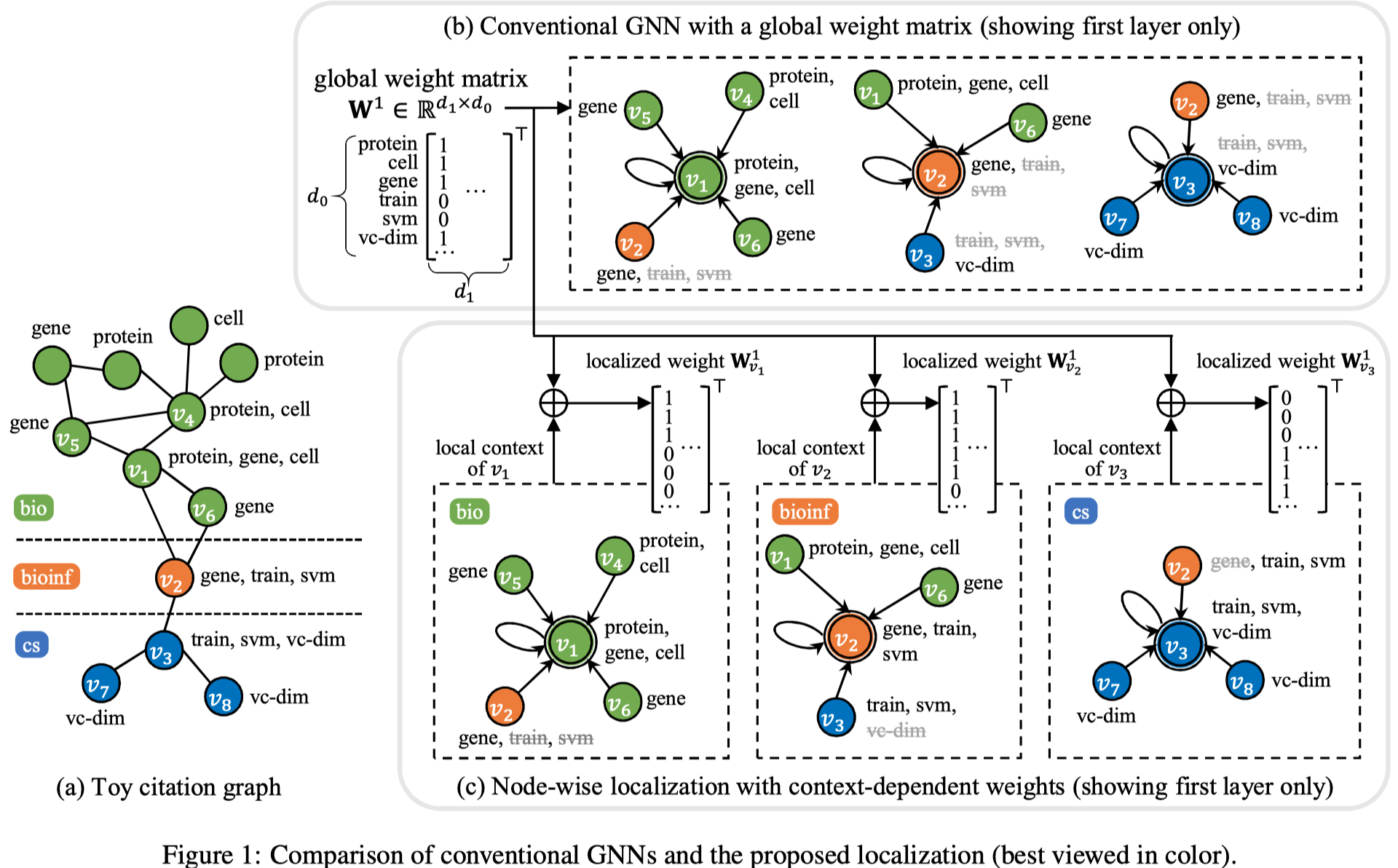
具体有两个Node-level localization和Edge-level localization.
Node-level localization
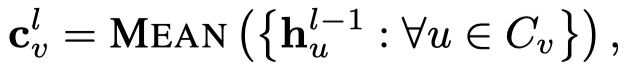

注意,这里没有给不同node都定义新的vector,而是直接从上一层的邻居直接mean聚合,然后进行转换,生成的向量\(a_v\)和\(b_v\)之后用于生成node \(v\)的weight matrix。
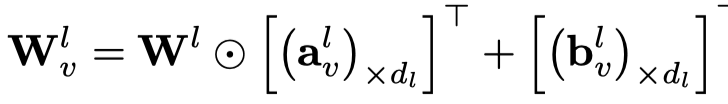
注意这里,是把\(a_v\)和\(b_v\)作为一行,然后复制,最后作用到graph global matrix\(W_l\)上。
Edge-level localization
作者对node \(v\)的不同邻居edge进一步建模:

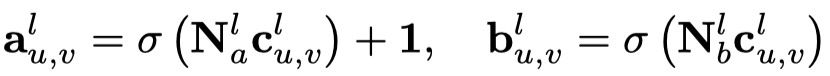
最后聚合:
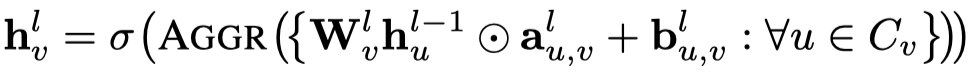
SRGCN
SRGCN: Graph-based multi-hop reasoning on knowledge graphs Neurocomputing 2021
这篇文章在预测\(<h, r, t>\)的时候,首先构建\(h\)和\(t\)之间的graph,然后在这个graph上,逐步使用R-GCN得到对于尾实体的预测embedding,最后使用MLP获得score。
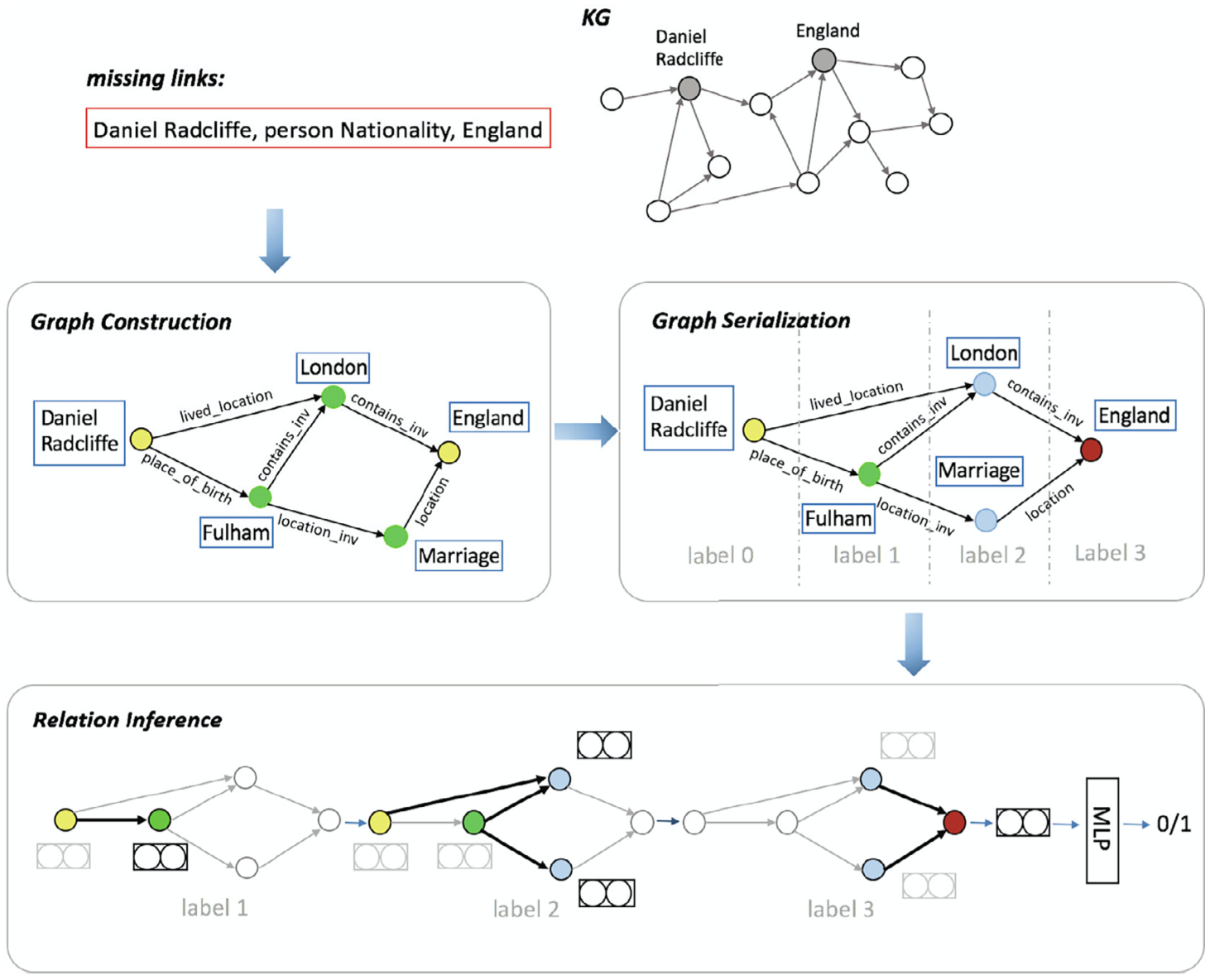
图中的label指的是从头实体出发,遇到的第几阶邻居。一个实体与头实体之间存在多个不同长度的path时,以最长的path作为label。
之后在使用R-GCN进行图卷积时,并不是以头实体为中心不断的聚合邻居。而是将头实体作为一开始,不断聚合到下一阶邻居实体上,直到聚合到具有最大label的实体上。
Chen et al.
Learning graph attention-aware knowledge graph embedding Neurocomputing 2021
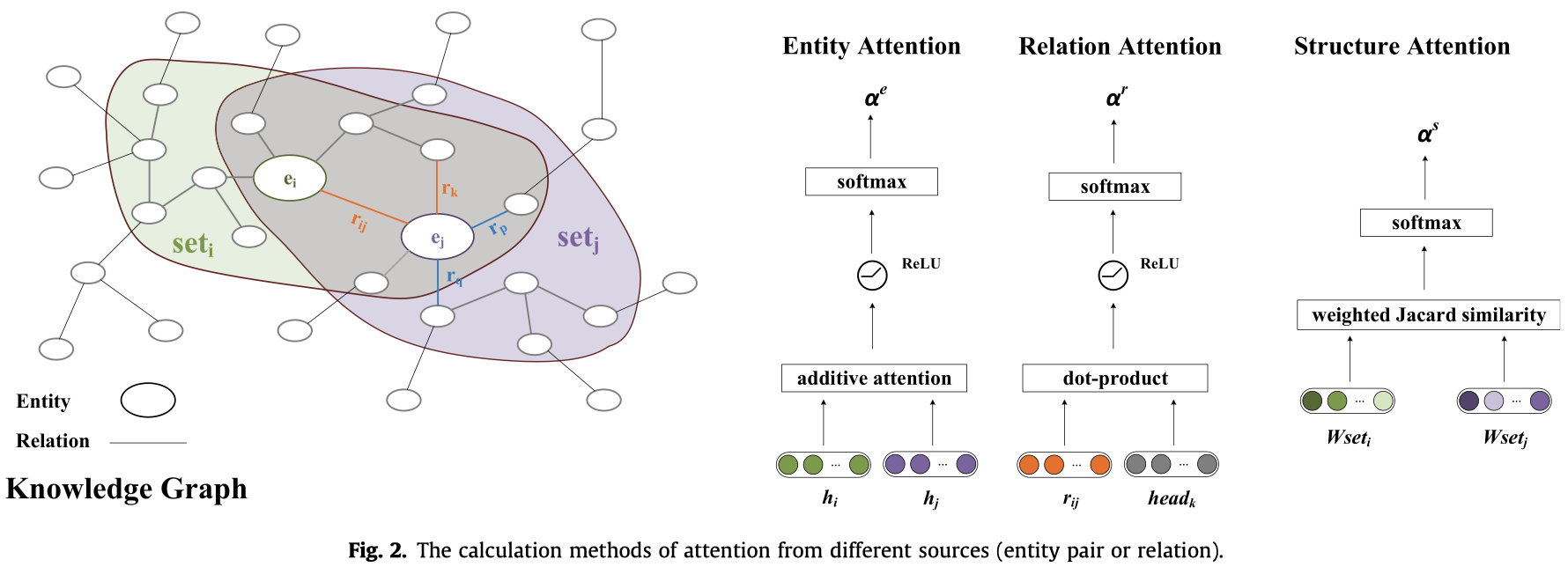
这篇文章核心是提出了一种新的在KG上计算attention的方法,有三个部分:entity attention、relation attention和structure attention。最核心的创新点是计算structural attention。
Entity attention:
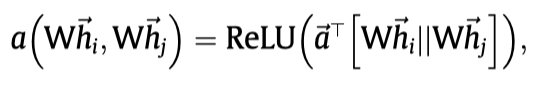
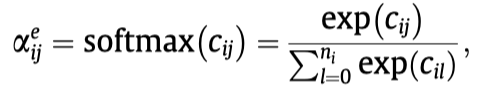
Relation attention:
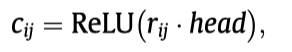

Structure attention:
使用带重启机制的随机游走方法(Random Walk with Restart,RWR),
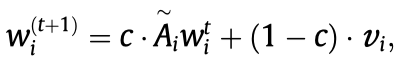
其中,\(w_i \in \mathbb{R}^{N\times 1}\),其中的entry \(p\)表示实体\(i\)通过随机游走到达实体\(p\)的概率,这个概率越大,表示这两个实体在结构上的相关性越大。
然后,由于每个实体\(i\)都有一个对应的\(w_i\),计算邻居边\(<i,j>\)在结构上的权重,使用了jaccard相似度计算方法,核心思想是某个实体\(p\)如果同时出现在实体\(i\)和实体\(j\)的邻居中,那么如果实体\(i\)和实体\(j\)的结构相似度越大,实体\(p\)在\(w_i\)和\(w_j\)中的差距应该越小。因此有:
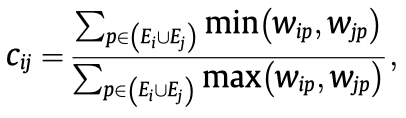
最后是softmax:
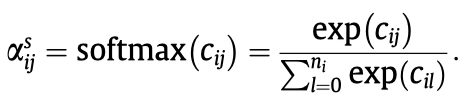
整体结构图:
MTE
Relation-based multi-type aware knowledge graph embedding Neurocomputing 2021
这篇文章将本体(ontology)考虑到了GNN当中,从而学习KGE。ontology是描述entity的类型的语法树。
作者将ontology树使用bi-directional transformer model获得关于type的embedding。其中的输入是从root到leaf的序列。

获得type的embedding之后,对于某个具体实体\(e\),不同type的比重应该不同。作者认为如果实体\(e\)链接的triples中,关系\(r\)属于某个type \(t\)的数量越多,则比重越大。比如在上图,对于实体Ang_Lee,类型director的比重应该比actor更大,因为属于\(director\)的triple数量更多。
实体\(e\)的type embedding应该是:
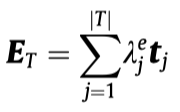
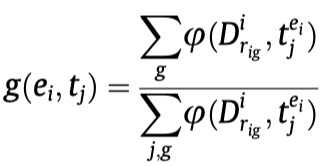
上面第二个公式的含义就是统计属于某个type \(t\)的triples的数量占比。
之后,作者提出一种基于relation的attention聚合方法。
单个relation下的实体聚合:
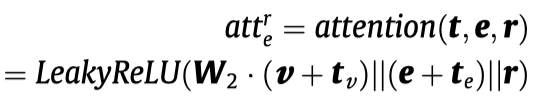


多个relation的聚合:
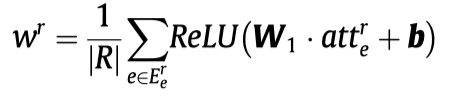
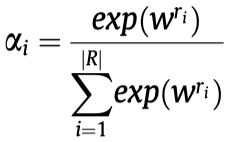

RevGNN
Training Graph Neural Networks with 1000 Layers ICML 2021
[个人详细博客]这篇文章通过在GNN中引入grouped reversible connections,实现了将GNN拓展到1000层,可能是当前最深的GNN之一。这篇文章的意义在于,实现了GNN的层数与模型所需的显存无关,使用较少的显存就可以在显存基本不增加的情况下,任意增加GNN深度。