Code-Prompt-LLM1
使用Code-style prompt的LLM工作
工作总结合集1。
PAL
PAL: Program-aided Language Models. ICML 2023,CMU,代码。
Large language models (LLMs) have demonstrated an impressive ability to perform arithmetic and symbolic reasoning tasks, when provided with a few examples at test time (“few-shot prompting”). Much of this success can be attributed to prompting methods such as “chainof-thought”, which employ LLMs for both understanding the problem description by decomposing it into steps, as well as solving each step of the problem. While LLMs seem to be adept at this sort of step-by-step decomposition, LLMs often make logical and arithmetic mistakes in the solution part, even when the problem is decomposed correctly. In this paper, we present ProgramAided Language models (PA L): a novel approach that uses the LLM to read natural language problems and generate programs as the intermediate reasoning steps, but offloads the solution step to a runtime such as a Python interpreter. With PAL, decomposing the natural language problem into runnable steps remains the only learning task for the LLM, while solving is delegated to the interpreter. We demonstrate this synergy between a neural LLM and a symbolic interpreter across 13 mathematical, symbolic, and algorithmic reasoning tasks from BIG-Bench Hard and others. In all these natural language reasoning tasks, generating code using an LLM and reasoning using a Python interpreter leads to more accurate results than much larger models. For example, PAL using CODEX achieves state-of-the-art few-shot accuracy on GSM8K, surpassing PaLM-540B which uses chain-of-thought by absolute 15% top-1.
Issue: 这篇文章主要是解决虽然LLM能够理解问题,并且把问题的推理过程分别为不同步骤,但是在最后根据推理过程计算答案的时候出现错误的问题。有时候即便是推理过程是正确的,LLM最后的计算答案是错误的。
Solution: 因此作者提出对问题的理解,以及推理步骤的拆分和规划让LLM完成。计算答案、根据推理过程推导答案由外部工具完成。这样就能够缓解推理链正确,最后对应的推理结果错误的问题。让LLM做自己擅长的部分,不擅长的部分让其它工具完成。
让LLM生成推理答案的时候同时生成编程语言,最后使用外部的工具如python interpreter计算答案:


实验基于code-davinci-002,在Mathematical Reasoning、Symbolic Reasoning、algorithmic reasoning等数据集上进行了实验。
KB-Coder
Code-Style In-Context Learning for Knowledge-Based Question Answering. 北航. AAAI 2024. 代码.
Current methods for Knowledge-Based Question Answering (KBQA) usually rely on complex training techniques and model frameworks, leading to many limitations in practical applications. Recently, the emergence of In-Context Learning (ICL) capabilities in Large Language Models (LLMs) provides a simple and training-free semantic parsing paradigm for KBQA: Given a small number of questions and their labeled logical forms as demo examples, LLMs can understand the task intent and generate the logic form for a new question. However, current powerful LLMs have little exposure to logic forms during pre-training, resulting in a high format error rate. To solve this problem, we propose a code-style in-context learning method for KBQA, which converts the generation process of unfamiliar logical form into the more familiar code generation process for LLMs. Experimental results on three mainstream datasets show that our method dramatically mitigated the formatting error problem in generating logic forms while realizing a new SOTA on WebQSP, GrailQA, and GraphQ under the few-shot setting. The code and supplementary files are released at https://github.com/Arthurizijar/KB-Coder.
Issue: 作者认为在KBQA中,之前的研究工作主要是考虑利用ICL技术,让LLM直接生成对应的logical forms,这种logical forms实际上是LLM不熟悉的。这就导致了两个后果:1)生成的logical forms格式常常出错;2)zero-shot泛化效果差,特别是很多情况下训练集中不存在相应的demonstrations。
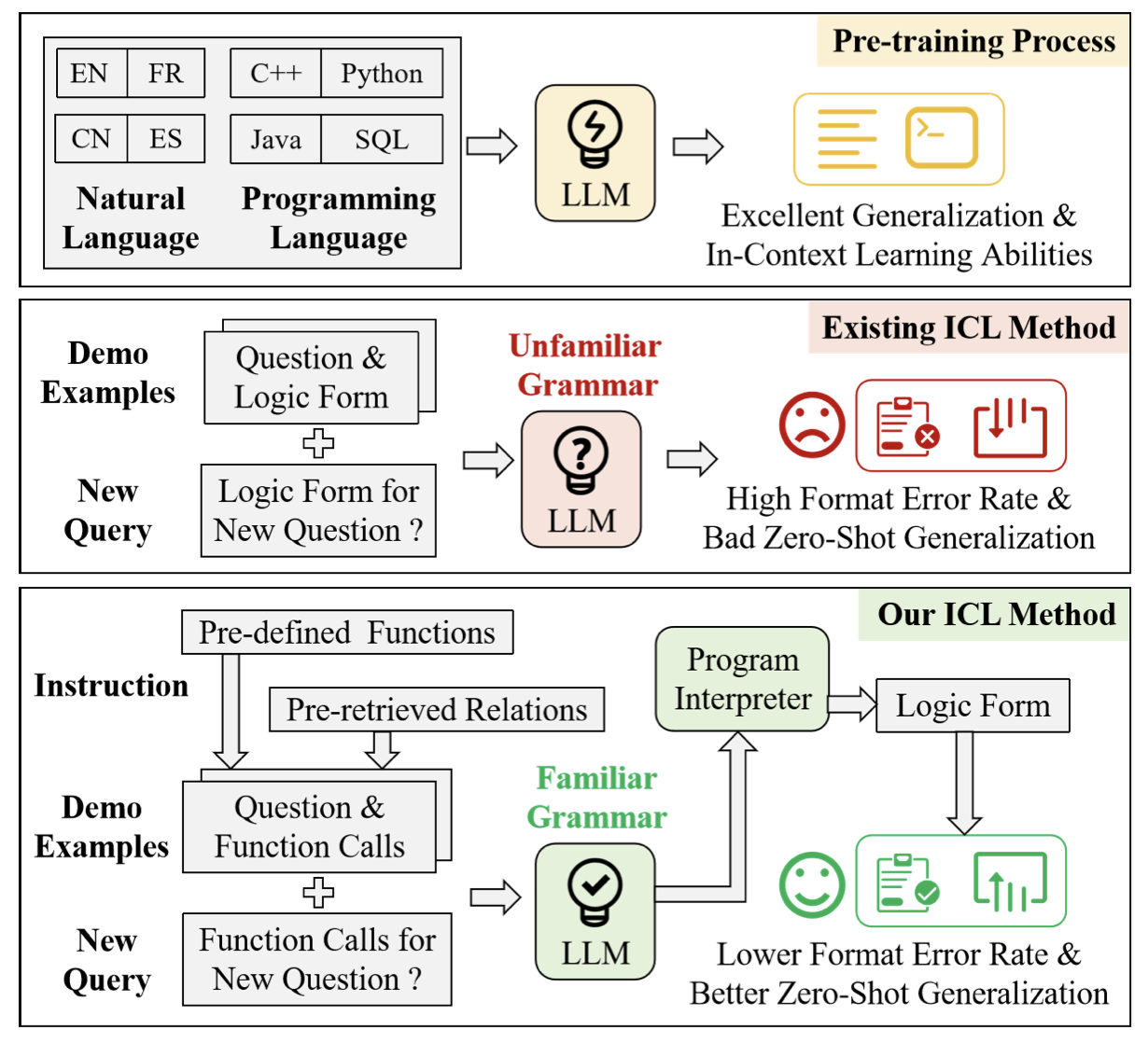
Solution: 作者将logical forms生成转化为生成一连串的python function调用过程,并且是生成了多个候选的调用过程,尽可能利用多步推理来获得最后的结果。
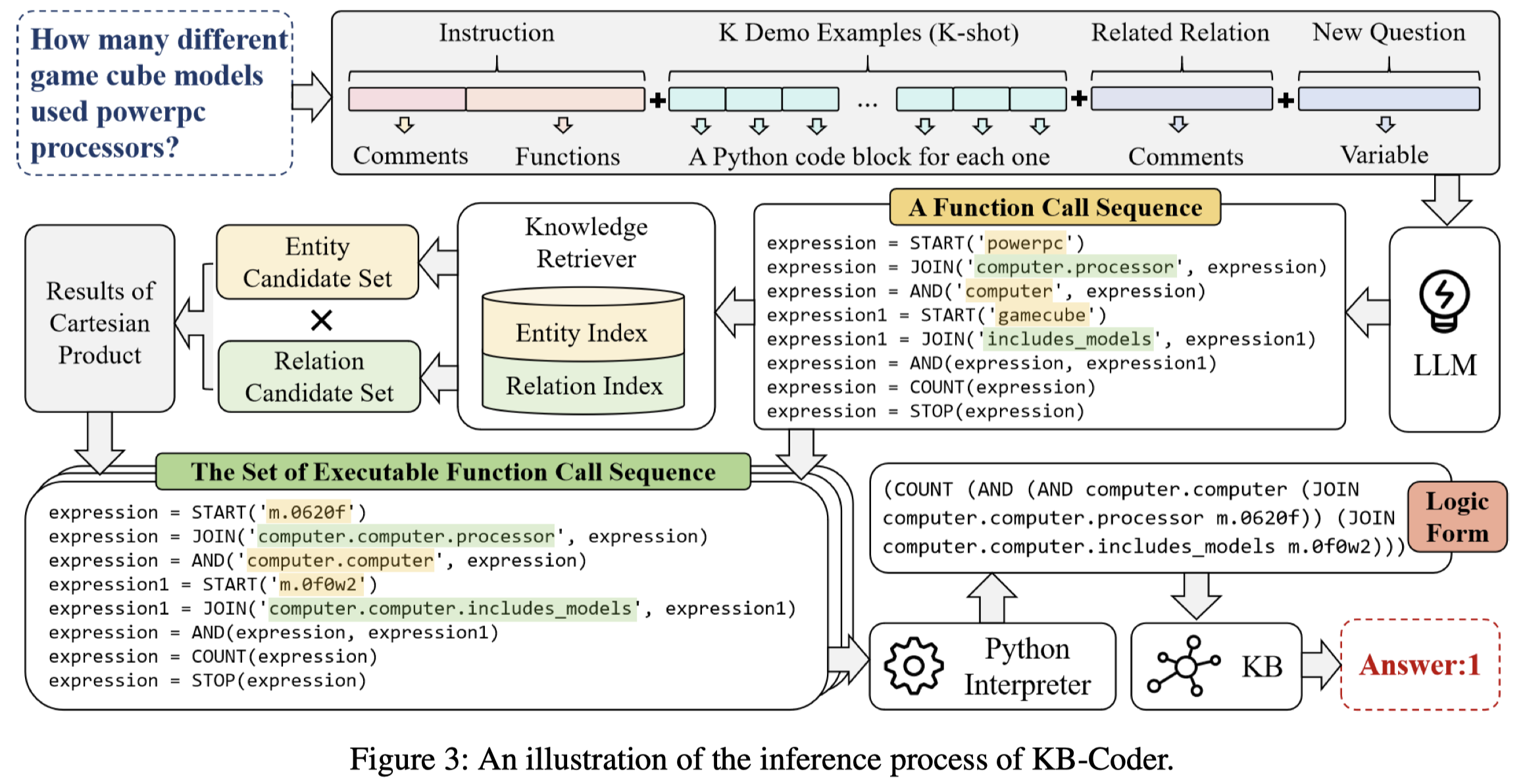
在KBQA中,作者使用S-Expression来描述logical forms:
1 | (COUNT (AND (JOIN nationality m.09c7w0) |
这种形式LLM可能很不熟悉,因此,作者将其转化为函数调用过程。首先人工定义了几个基础的python function,头部的注释作为task instruction:

ICL中的demonstrations格式为:
1 | question = 'how many american presenters in total' |
注意,demonstrations里作者提前把entity/relation id m.03yndmb等替换为了实际的entity name united States of America, profession等。
对于新的query,使用python string类型的变量question=来表示。随后,结合demonstrations,期望LLM能够为query question生成对应python function执行过程。
由于生成的结果将会自动包括了LLM认为的entity/relation的name,这些name并不一定会真的在KB中存在,因此作者使用SimCSE去链接现有KB中name语义上相似的entity/relation,然后替换生成的python function执行过程。这样就得到了一系列的候选function。
这些function执行过程随后可以被转化为真正的S-Expression格式的logical forms,然后放入SPARQL从KB中进行查询,只要能够返回一个最后的查询结果,就终止,作为答案返回。
作者的实验基于gpt-3.5-turbo。
CIRS
When Do Program-of-Thought Works for Reasoning? AAAI 2024. 浙大. 代码.
In the realm of embodied artificial intelligence, the reasoning capabilities of Large Language Models (LLMs) play a pivotal role. Although there are effective methods like program-ofthought prompting for LLMs which uses programming language to tackle complex reasoning tasks, the specific impact of code data on the improvement of reasoning capabilities remains under-explored. To address this gap, we propose complexity-impacted reasoning score (CIRS), which combines structural and logical attributes, to measure the correlation between code and reasoning abilities. Specifically, we use the abstract syntax tree to encode the structural information and calculate logical complexity by considering the difficulty and the cyclomatic complexity. Through an empirical analysis, we find not all code data of complexity can be learned or understood by LLMs. Optimal level of complexity is critical to the improvement of reasoning abilities by program-aided prompting. Then we design an autosynthesizing and stratifying algorithm, and apply it to instruction generation for mathematical reasoning and code data filtering for code generation tasks. Extensive results demonstrates the effectiveness of our proposed approach. Code will be integrated into the EasyInstruct framework.
Issue: LLM的推理能力非常重要,最近一些工作利用code prompting的方法,比如program-of-thought来提升LLM的推理能力。但是,到底什么情况下这种基于code的推理可以起作用?
Solution: 作者提出LLM在训练阶段,code的复杂度与LLM本身的推理能力息息相关。
作者认为用编程语言来作为prompting的两个潜在好处:
- their superior modeling of intricate structures compared to serialized natural language.
- their inherent procedure-oriented logic, which assists in addressing multi-step reasoning problems.
作者提出的考虑code data的复杂度,同时从AST结构复杂度和逻辑复杂度两个角度进行考虑,CIRS指标计算如下:
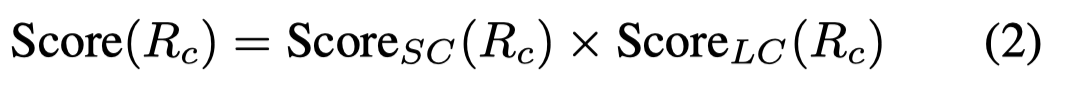
结构复杂度考虑代码抽取语法树的Node Count、Node Types和Tree Depth:

逻辑复杂度考虑代码的Halstead Complexity Metrics (Halstead 1977) and McCabe’s Cyclomatic Complexity (McCabe 1976)圈复杂度:

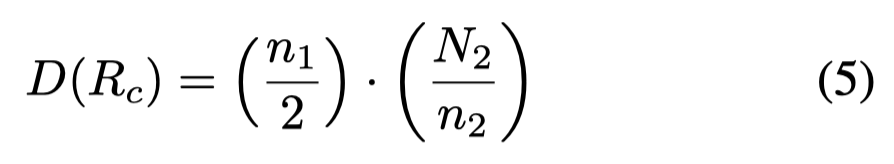

为了进行empirical study,作者利用现有的几个math problem soloving训练集作为seed dataset,然后让gpt-3.5-turbo不断的仿照生成更多的code data以及对应的问题。随后,按照CIRS指标划分出复杂度低、中、高的3个子集,用于训练LLaMA 1。
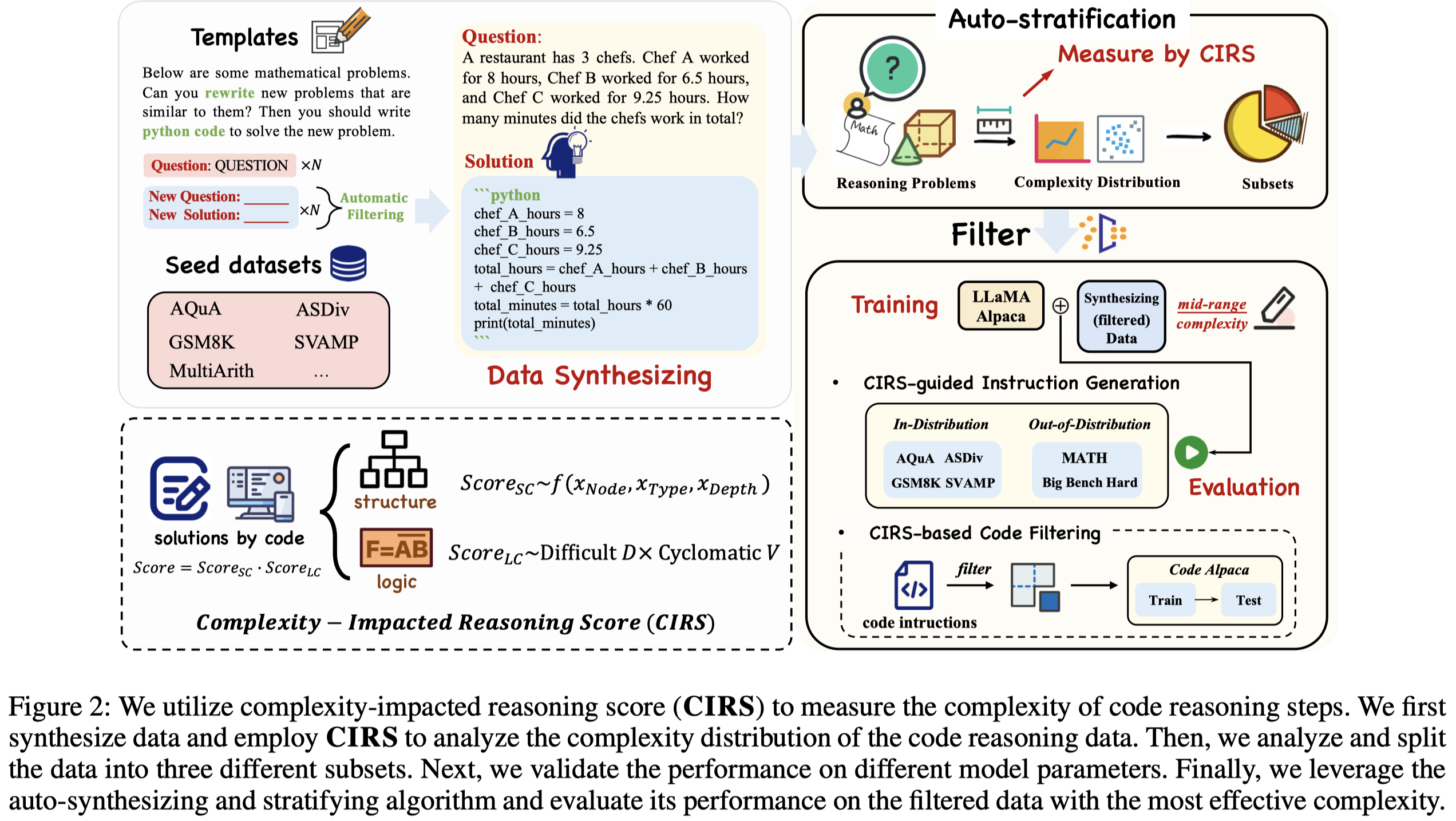
实验结果:
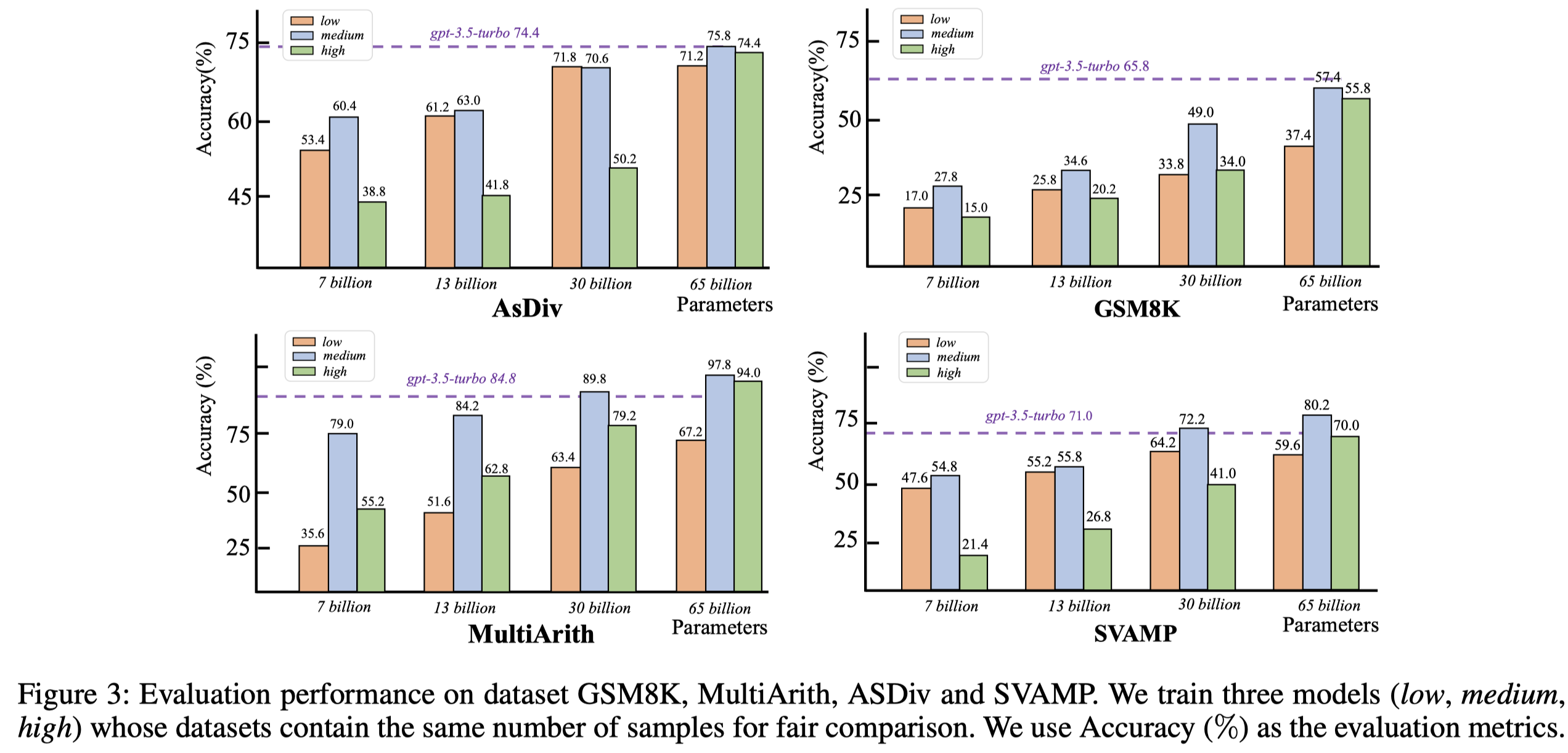
观察:
- 采用中间复杂度的code data训练LLM,效果更好
- 随着参数量增加,LLM越来越能够从复杂的代码中获取足够的好处
- 复杂度过低的code data可能蕴含的知识量太少;而复杂度过高的code data可能对于LLM来说太难理解
CoCoGen
Language Models of Code are Few-Shot Commonsense Learners. EMNLP 2022. CMU. 代码.
We address the general task of structured commonsense reasoning: given a natural language input, the goal is to generate a graph such as an event or a reasoning-graph. To employ large language models (LMs) for this task, existing approaches “serialize” the output graph as a flat list of nodes and edges. Although feasible, these serialized graphs strongly deviate from the natural language corpora that LMs were pre-trained on, hindering LMs from generating them correctly. In this paper, we show that when we instead frame structured commonsense reasoning tasks as code generation tasks, pre-trained LMs of code are better structured commonsense reasoners than LMs of natural language, even when the downstream task does not involve source code at all. We demonstrate our approach across three diverse structured commonsense reasoning tasks. In all these natural language tasks, we show that using our approach, a code generation LM (CODEX) outperforms natural-LMs that are fine-tuned on the target task (e.g., T 5) and other strong LMs such as GPT-3 in the few-shot setting. Our code and data are available at https: //github.com/madaan/CoCoGen .
Issue: 之前的结构化推理structured commonsense reasoning方法为了利用text LLM,是将结构化的输出graph/table等转化/序列化为了文本形式。但是这种转换后的文本形式实际上LLM在训练时可能很少见到,LLM不够熟悉,可能输出不符合要求的形式
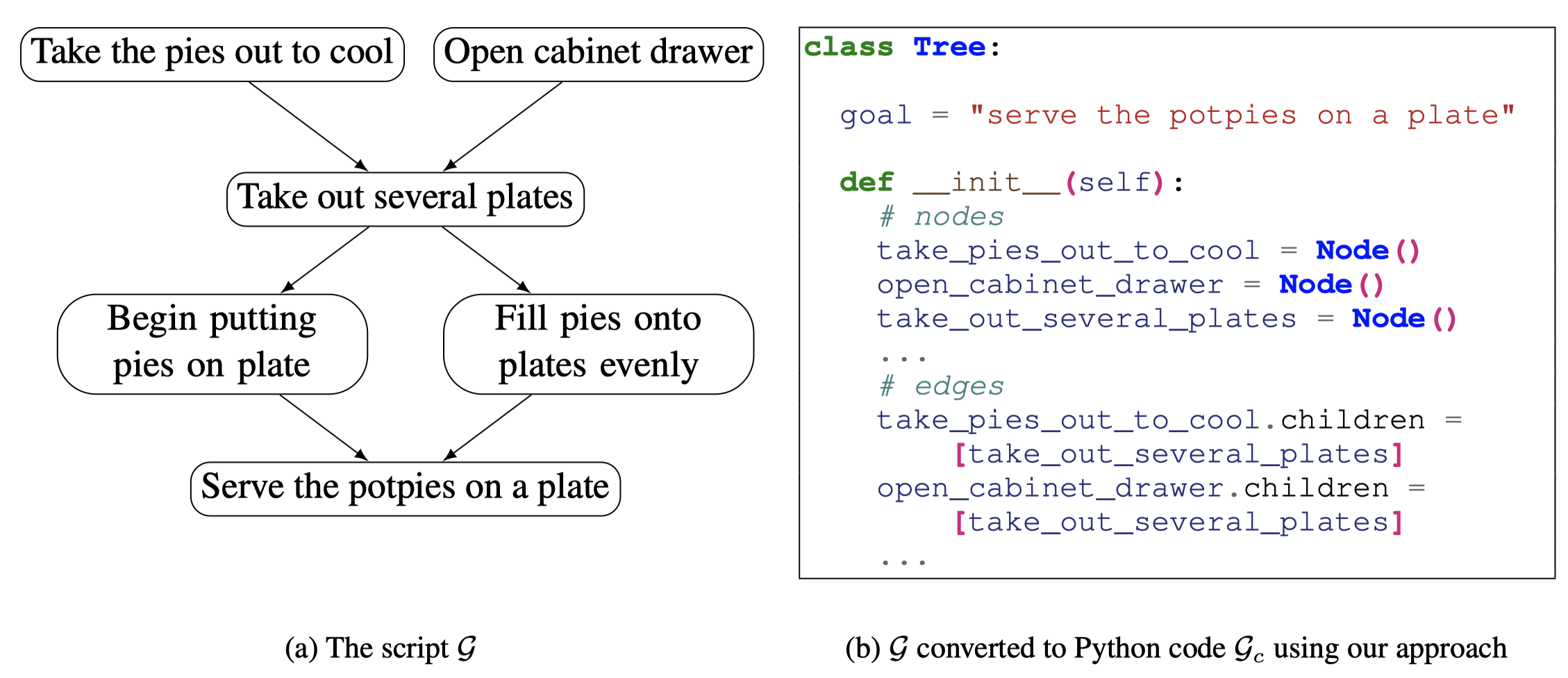
Solution: 作者认为,可以使用编程语言而不是自然语言来更好的描述结构化的输出,减小pretraining和adaptation两个阶段的discrepancy。
比如,对于下面script generation任务,要求给定自然语言的文本,能够自动生成脚本。作者的做法就是利用python这种预训练code data中非常popular的编程语言,定义Tree的数据结构class来进行定义:
entity state tracking:

explanation graph generation:

作者实验主要使用code-davinci-002,在script generation、entity state tracking、explanation graph generation三个结构化推理任务上进行了实验。
ViperGPT
ViperGPT: Visual Inference via Python Execution for Reasoning. ICCV 2023. Columbia University. 代码.
Answering visual queries is a complex task that requires both visual processing and reasoning. End-to-end models, the dominant approach for this task, do not explicitly differentiate between the two, limiting interpretability and generalization. Learning modular programs presents a promising alternative, but has proven challenging due to the difficulty of learning both the programs and modules simultaneously. We introduce ViperGPT, a framework that leverages code-generation models to compose vision-and-language models into subroutines to produce a result for any query. ViperGPT utilizes a provided API to access the available modules, and composes them by generating Python code that is later executed. This simple approach requires no further training, and achieves state-of-the-art results across various complex visual tasks.
Issue: 视觉上的推理可能是分步的,但是目前大多的方法还是end-to-end的,无法进行compositional reasoning。
Solution: 作者创造了一个框架,通过提供给LLM API让LLM利用这些API来组合生成解决问题的程序,每个API通过调研不同的模型(视觉模型GLIP、X-VLM、LLM GPT-3)等实现不同的功能。程序可以用来一步步的组合推理,API可以直接无需训练的利用已有的各种model去解决问题。
NN为什么不适合做多步的推理?比如把NN分为多个modules,然后期望每个module能够执行特定的任务,问题在于这种做法可能依赖于人工的解析器,或者是利用强化学习训练,但这种方法很难优化;另外,多个模块的NN更加难以训练,输出不可预测。
推理与感知分离,然后结合神经-符号方法。尽管思想上是一致的,但是这种方法较难学习和优化。
随后的方法就开始采用了端到端的思路来降低优化难度。最近大模型被加入进来,但是它们都指定了特定的模型。
作者的框架图:
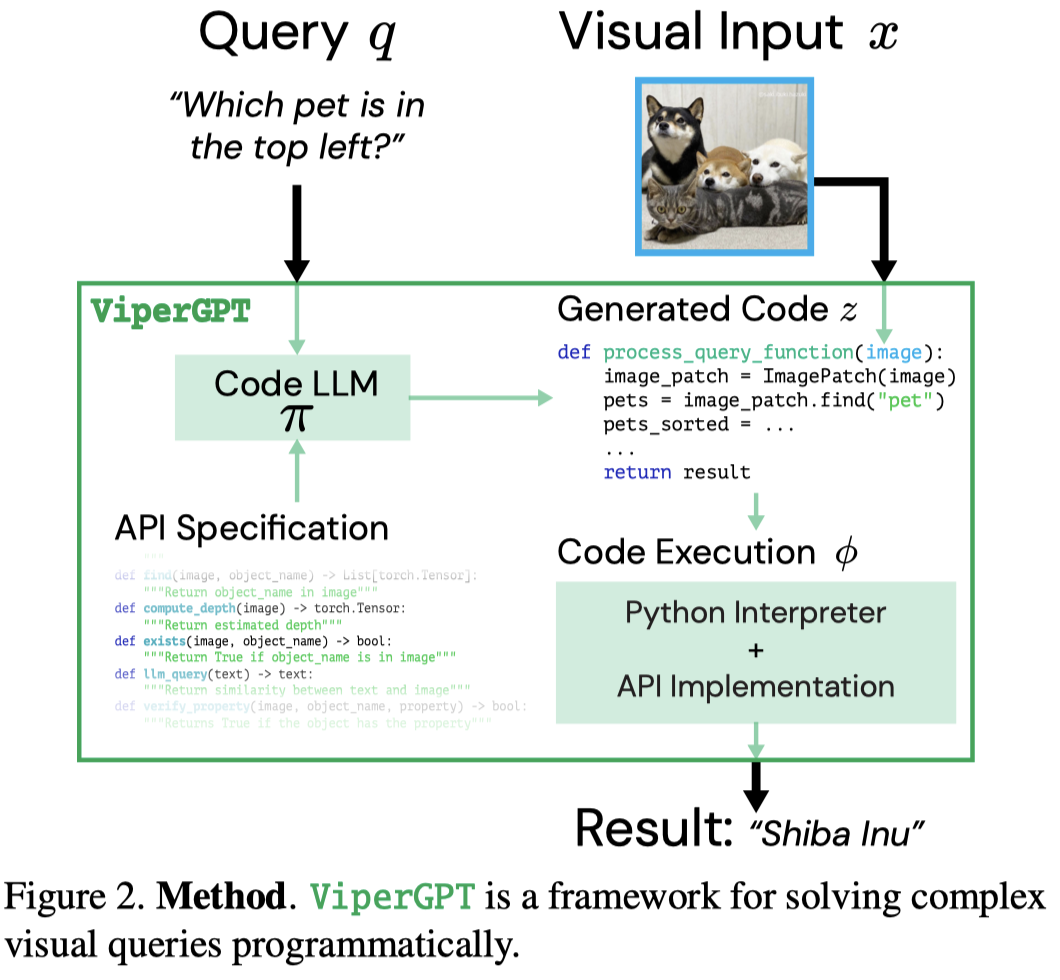
作者的方法可以处理image和video,下面是两个示例:

下面是输入给codex的API prompt,每个class内部的function都有docstring来解释function的目的;然后提供了如何使用这些function的说明示例。输入给Codex的定义没有完整的实现,有两个目的: 1. 完整的代码实现可能过长,超出LLM context window size 2. 抽象的code定义和具体的实现无关,解耦
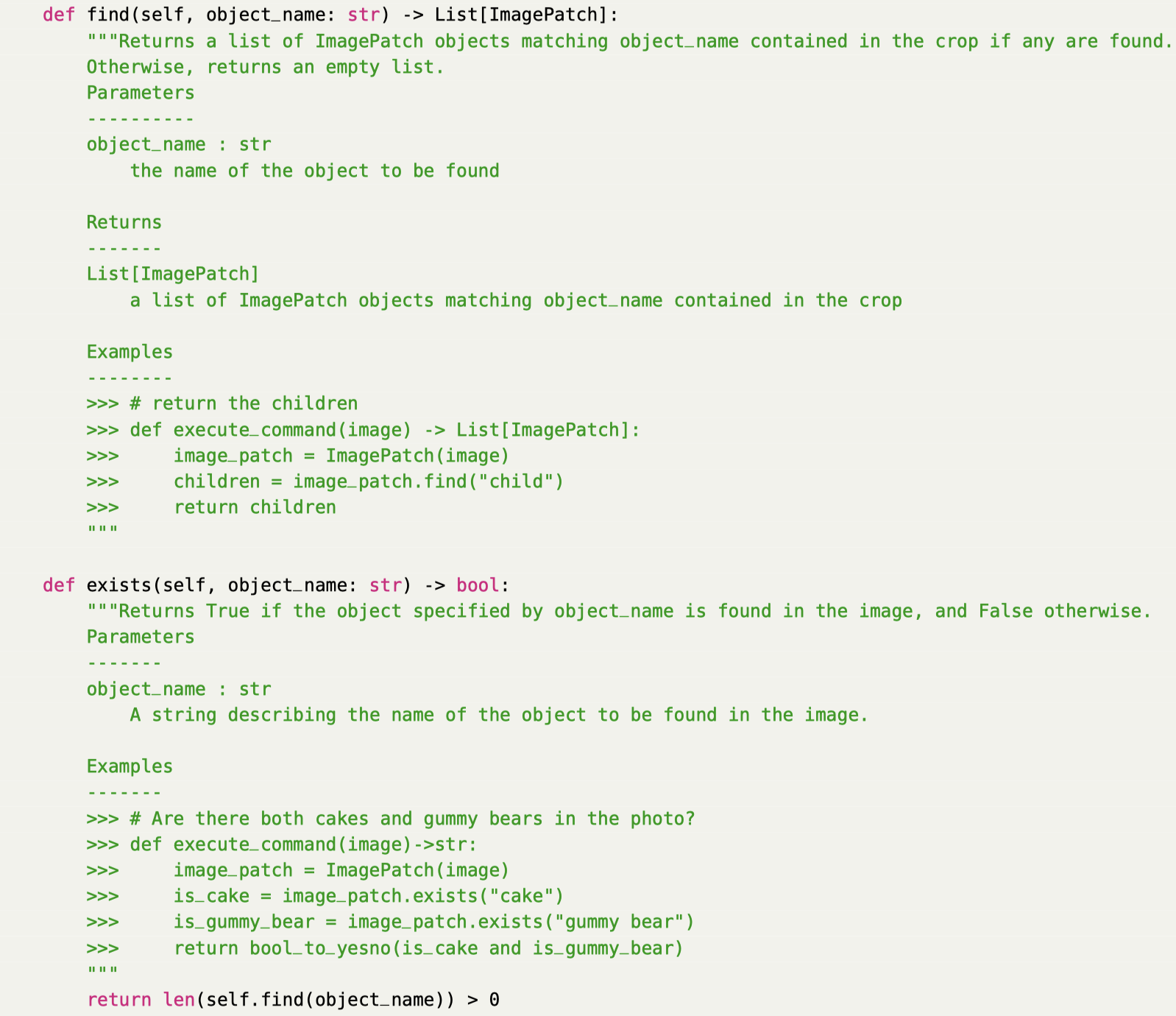

最终执行生成的推理程序的时候,同时结合python解释器以及训练好的其它模型。 1. python解释器的调研可以利用python各种内置的functions,并且可以完整的执行逻辑操作 2. 外部的预训练模型主要负责感知
实验在1) visual grounding, 2) compositional image question answering, 3) external knowledge-dependent image question answering, and 4) video causal and temporal reasoning任务上评估
Code Prompt for Conditional Reasoning
Code Prompting Elicits Conditional Reasoning Abilities in Text+Code LLMs. arXiv 2024. hessian.AI. 代码.
Reasoning is a fundamental component of language understanding. Recent prompting techniques, such as chain of thought, have consistently improved LLMs’ performance on various reasoning tasks. Nevertheless, there is still little understanding of what triggers reasoning abilities in LLMs in the inference stage. In this paper, we introduce code prompting, a chain of prompts that transforms a natural language problem into code and directly prompts the LLM using the generated code without resorting to external code execution. We hypothesize that code prompts can elicit certain reasoning capabilities of LLMs trained on text and code and utilize the proposed method to improve conditional reasoning, the ability to infer different conclusions depending on the fulfillment of certain conditions. We find that code prompting exhibits a high-performance boost for multiple LLMs (up to 22.52 percentage points on GPT3.5, 7.75 on Mixtral, and 16.78 on Mistral) across multiple conditional reasoning datasets. We then conduct comprehensive experiments to understand how code prompts trigger reasoning abilities and which capabilities are elicited in the underlying models. Our analysis of GPT3.5 reveals that the code formatting of the input problem is essential for performance improvement. Furthermore, code prompts improve sample efficiency of in-context learning and facilitate state tracking of variables or entities.
Issue: 之前的工作已经证明了,code+code LLM,对于推理问题,可能比text+text LLM效果好,但是是不是code比text能够在text+code LLM上表现效果好还没有进行过探究。
Solution: 作者进行了详细的empirical study来探究,对于conditional reasoning问题,从logical reasoning维度上,code prompt是否能够比text prompt表现好,并且,到底是哪些原因可能导致了code prompt表现效果更好。
QA可以被看作是语义推理任务。conditional reason的定义是给出满足conditions的conclusions,是self-contained的,无需外部的knowledge,属于logical reason的一部分。
作者的方法很直接,利用LLM先将原来自然语言表达的问题转换为code描述的问题,然后再让LLM来执行对应的code。这一个过程与faithful CoT方法一致。
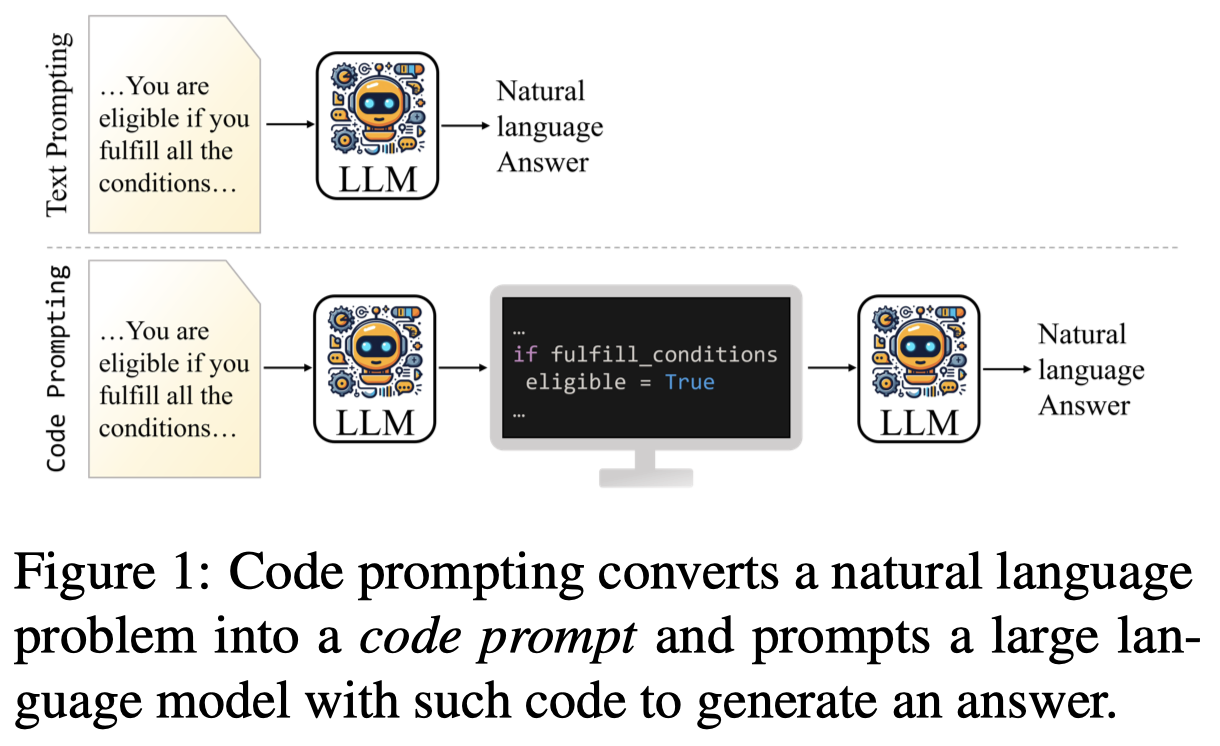
转换后的code,question和doc中的主要entities以局部变量的形式表示,必要满足的条件用if语句来表示,同时原始的question以python comment的方式保存。code prompt和text prompt相比,没有增加任何的新information:

作者的实验主要使用了gpt-35-turbo, Mixtral 7x8B (46.7B), Mistral 7B以及Phi-2 2.7B。在ConditionalQA、BoardgameQA和ShARC三个条件推理数据集上进行了实验。
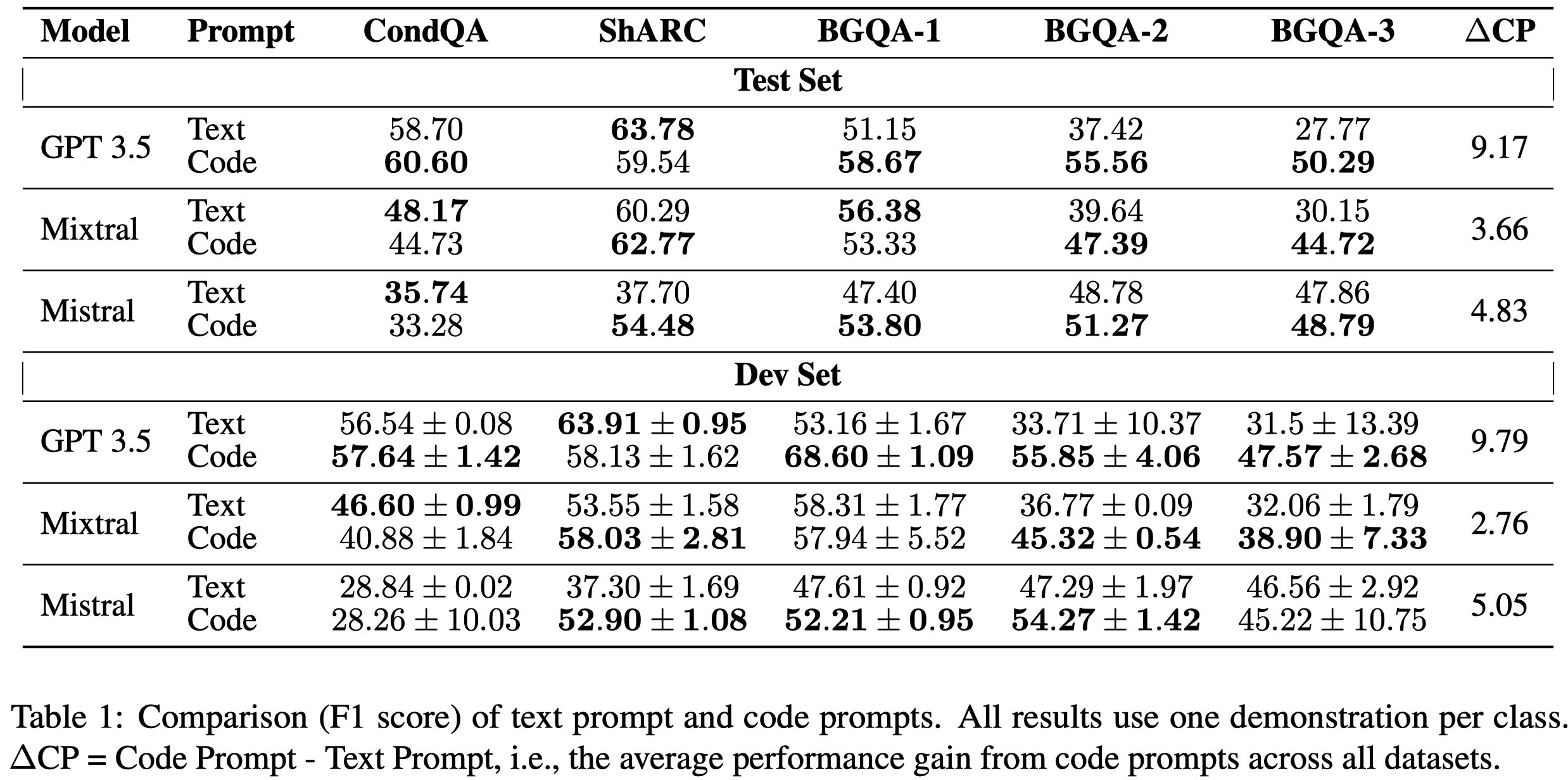
观察与结论:
总体上,code prompt比text prompt表现效果更好
在CondQA这种需要推理能力相对弱一点的数据集上,表现效果提升没有那么大,反而是在BGQA这种需要强推理能力的数据集上表现效果最好。这说明code prompt更加适合于reasoning-intensive的tasks。code prompts elicit conditional reasoning abilities and are most suited for reasoning-intensive tasks
在Phi-2这种小LM上,code prompt效果更好,可能是因为其对于NL问题的推理能力更弱,利用code能够更好的激发推理能力
text prompt的时候,更加不喜欢回答No;而是用code prompt,其更积极的回答No,这可能是因为code prompt更加明确的instruct LLM去跟踪某种状态
作者随后探究了code prompt的syntax是否会与推理性能有影响:
- Atomic Statements:根据FActScore: Fine-grained atomic evaluation of factual precision in long form text generation. EMNLP 2023,将sentence表示为atomic statement,然后append到sentence之后。用来调查是否简化text prompt导致推理能力提升
- Back-Translated Code:把code再度反向翻译回text,用来判断是否是code的semantic,而不是code syntax导致了推理能力提升
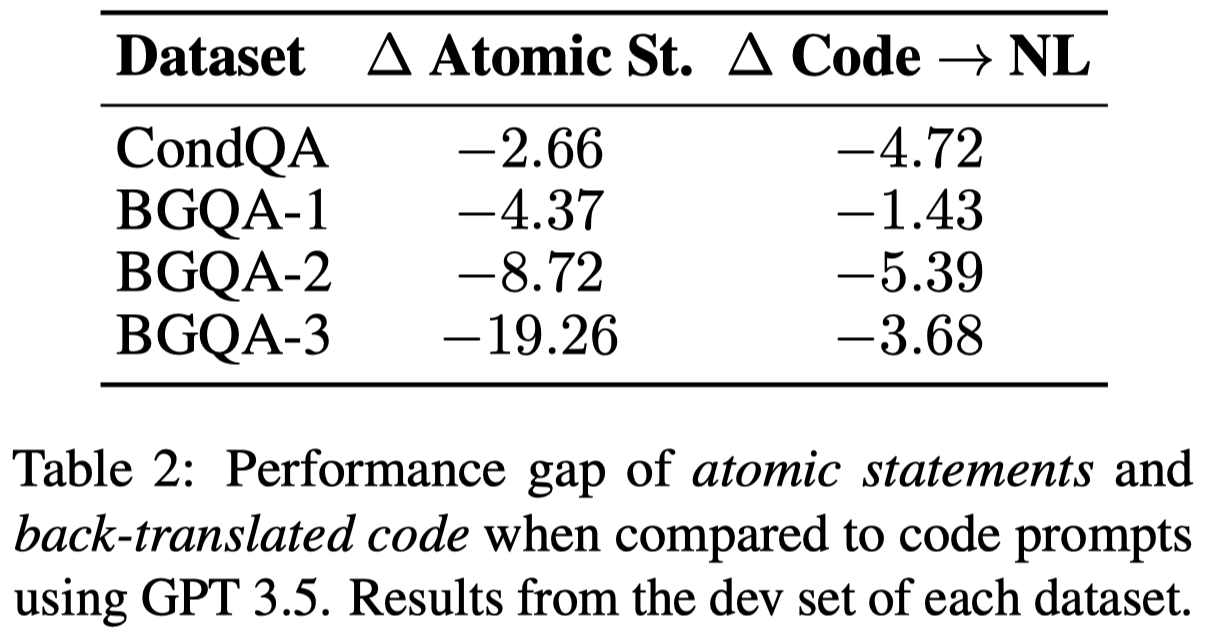
观察:
- code的特定语法,也会对推理能力提升起到作用
然后探究code的semantic是否对效果有影响:
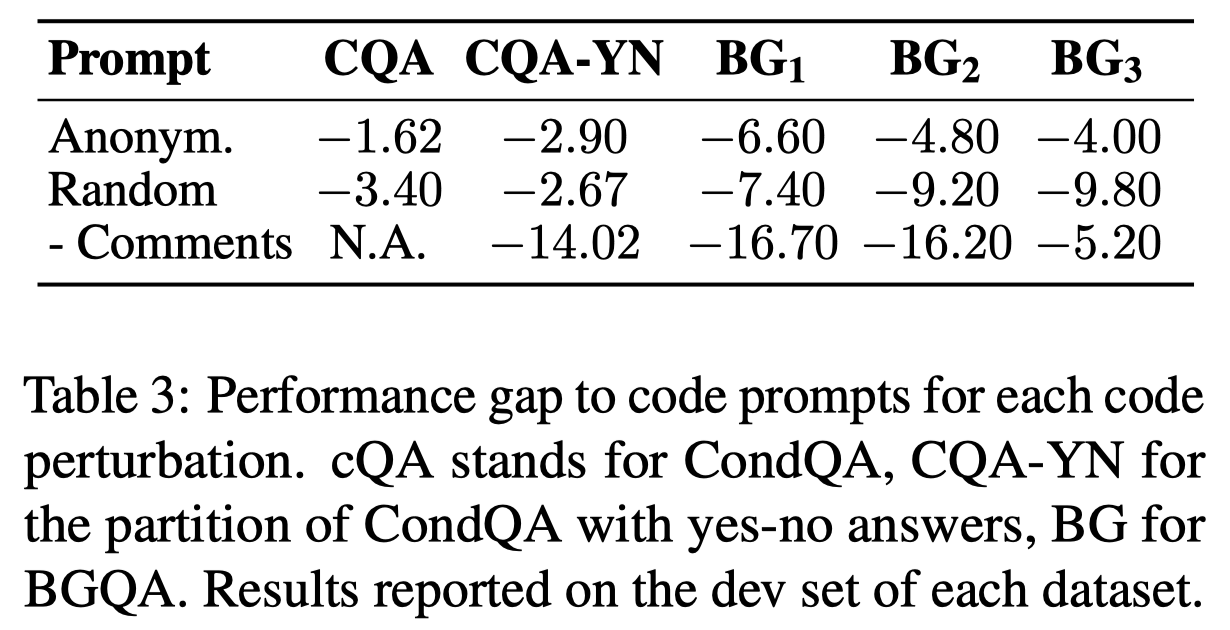
观察:
- code prompt的语义正确也非常关键,特别是应该保留原始的text作为comment
Code Prompts are More Sample-Efficient at Eliciting Reasoning Abilities:
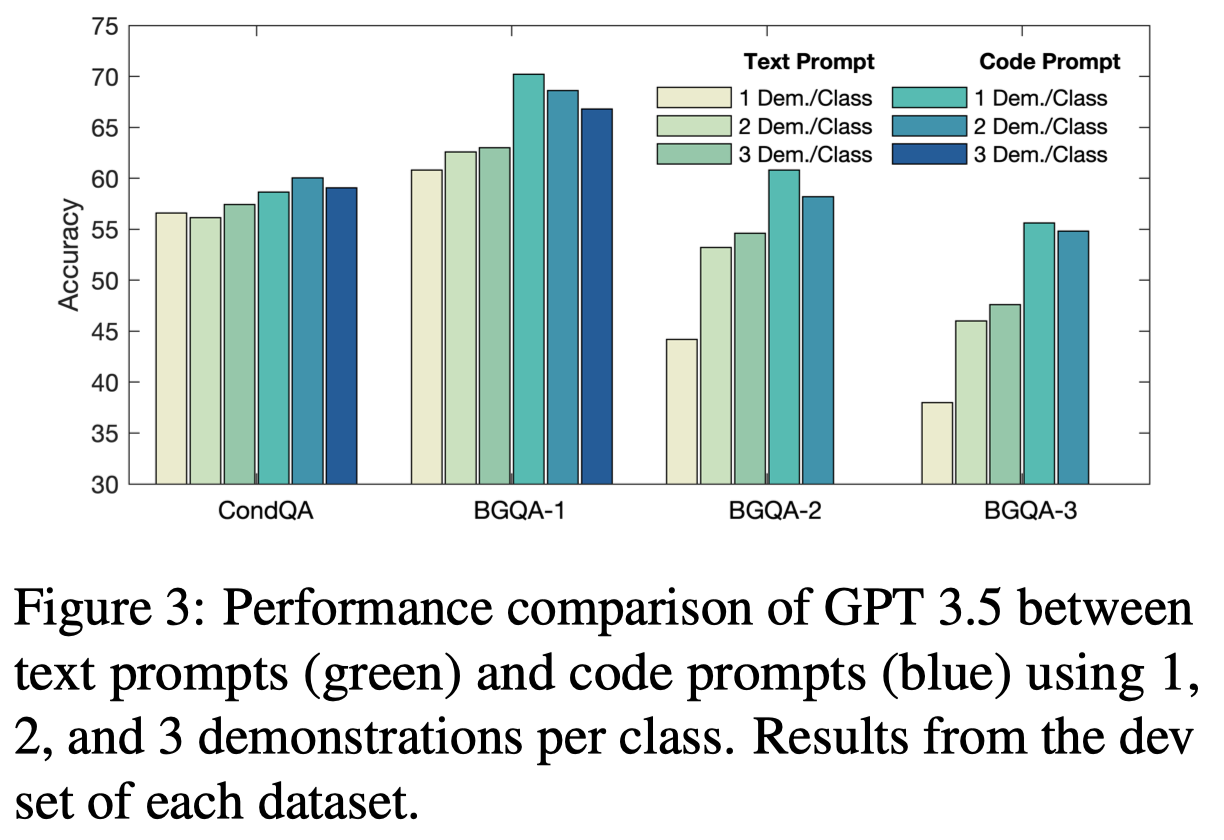
作者推测code prompt的另一个表现好的原因是,它激发了LLM跟踪关键variables/entities的能力。试想一下,如果是纯text,对于预测next token最重要的是周围的local的tokens。但是对于预测code,可能需要参考之前几十行乃至上百行定义的变量。这种跟踪远程entities的能力,对于很多推理问题是重要的。
an improved ability to look for distant co-references caused by training on code can be beneficial for multi-hop reasoning, which is also needed to solve our datasets.
作者通过在LLM输出每一句推理的sentence的时候(以\n结尾),询问LLM在输入中提到的关键key entities,询问其正确还是错误,LLM可以回答True, False, a string, or unknown。
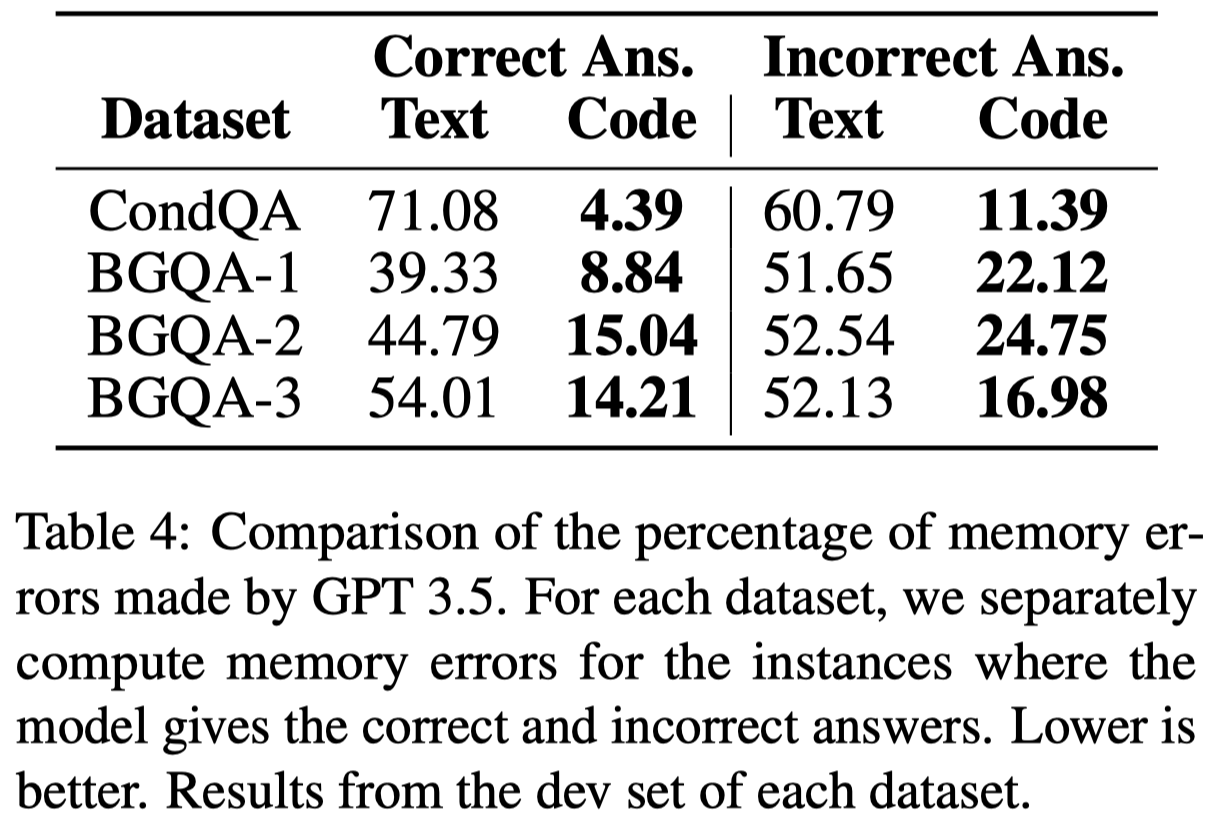
观察:
- Code Prompting improves State Tracking.
Faithful CoT
Faithful Chain-of-Thought Reasoning. IJCNLP 2023. University of Pennsylvania. 代码.
While Chain-of-Thought (CoT) prompting boosts Language Models’ (LM) performance on a gamut of complex reasoning tasks, the generated reasoning chain does not necessarily reflect how the model arrives at the answer (aka. faithfulness). We propose Faithful CoT, a reasoning framework involving two stages: Translation (Natural Language query → symbolic reasoning chain) and Problem Solving (reasoning chain → answer), using an LM and a deterministic solver respectively. This guarantees that the reasoning chain provides a faithful explanation of the final answer. Aside from interpretability, Faithful CoT also improves empirical performance: it outperforms standard CoT on 9 of 10 benchmarks from 4 diverse domains, with a relative accuracy gain of 6.3% on Math Word Problems (MWP), 3.4% on Planning, 5.5% on Multi-hop Question Answering (QA), and 21.4% on Relational Inference. Furthermore, with GPT-4 and Codex, it sets the new state-of-the-art few-shot performance on 7 datasets (with 95.0+ accuracy on 6 of them), showing a strong synergy between faithfulness and accuracy.
Issue: 在CoT被提出的时候[Chain of Thought Prompting Elicits Reasoning in Large Language Models. 2022],被认为provide an interpretable window into the behavior of the model。但是从作者观察到的很多例子来看,CoT和最后的答案互相冲突,即standard CoT不能够解释LLM的思考过程。如:

那么最后这种错误的答案到底是如何得到的,实际上不能够用CoT来解释。
Solution: 作者提出了个两阶段的过程,第一个阶段将原来的自然语言NL问题转化为多个由符号语言描述的子问题,也就是reason chain;第二个阶段,调用外部工具来执行/解决reason chain。那么这样的话,第二个阶段,执行reason chain的过程是faithful的,人们能够明确的知道是什么样的推理过程导致了最终的answer;但是第一个过程不保证是faithful的。
第一个阶段将原来的NL question分为多个子问题,每个子问题被任务特定的符号语言SL来进行解决。由NL comments (\(C_{NL}\))和SL program (\(C_{SL}\))组成。 第二个阶段通过调研外部工具来执行对应子问题的program。
不同的task,作者设计了不同的prompt template,会调用不同的外部工具来解决:
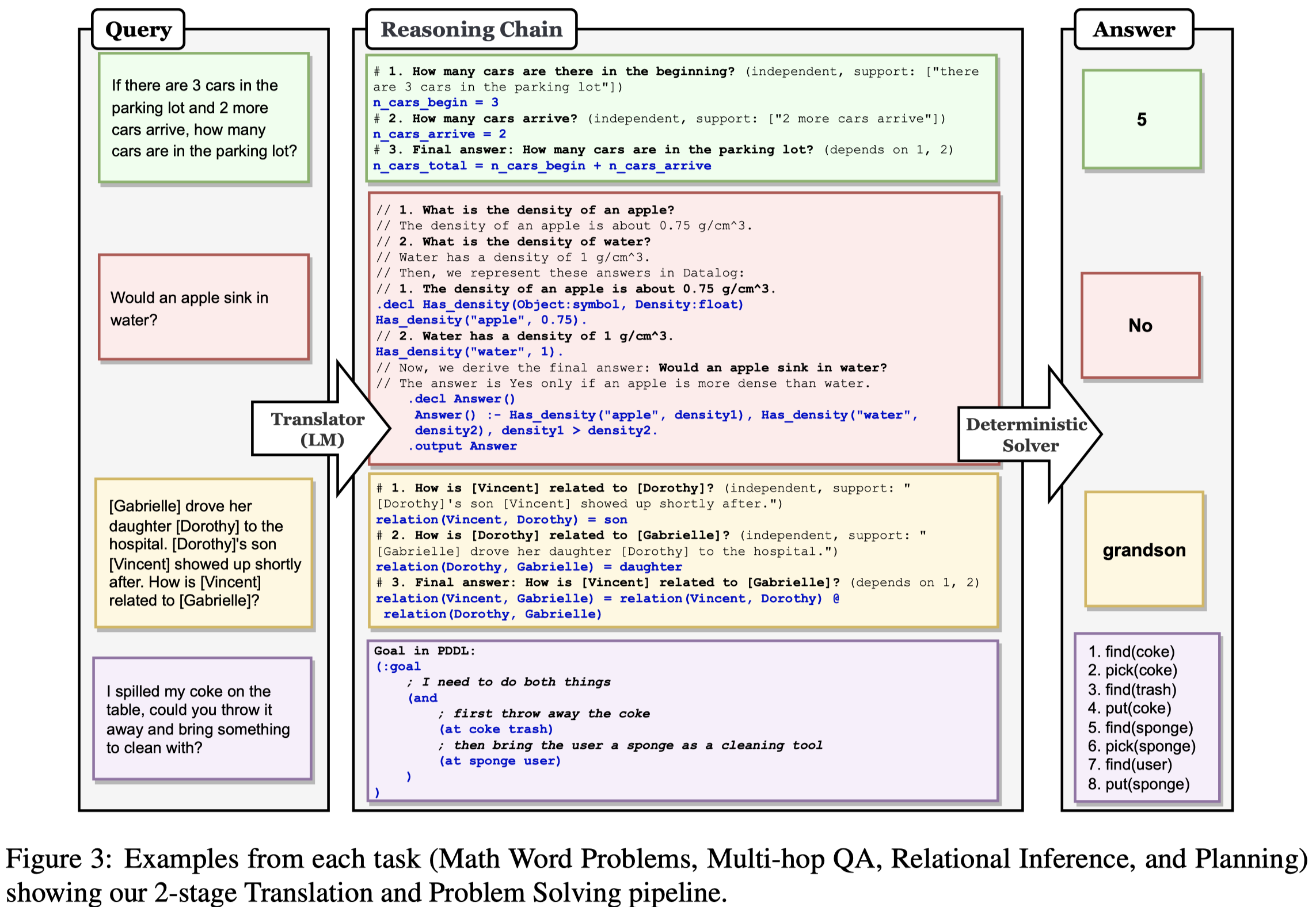
实验主要使用code-davinci-002,在Math Word Problems、Multi-hop QA、Planning、Relational inference上进行了实验。
PoT
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. University of Waterloo. TMLR 2023.
Recently, there has been significant progress in teaching language models to perform step-by-step reasoning to solve complex numerical reasoning tasks. Chain-of-thoughts prompting (CoT) is the state-of-art method for many of these tasks. CoT uses language models to produce text describing reasoning, and computation, and finally the answer to a question. Here we propose ‘Program of Thoughts’ (PoT), which uses language models (mainly Codex) to generate text and programming language statements, and finally an answer. In PoT, the computation can be delegated to a program interpreter, which is used to execute the generated program, thus decoupling complex computation from reasoning and language understanding. We evaluate PoT on five math word problem datasets and three financialQA datasets in both few-shot and zero-shot settings. We find that PoT has an average performance gain over CoT of around 12% across all datasets. By combining PoT with self-consistency decoding, we can achieve extremely strong performance on all the math datasets and financial datasets. All of our data and code will be released.
Issue: standard CoT中,LLM会同时负责reasoning和computation,作者认为LLM并不适合直接计算mathematical expressions:
- LLMs are very prone to arithmetic calculation errors, especially when dealing with large numbers; LLM对数据不敏感,常计算错误
- LLMs cannot solve complex mathematical expressions like polynomial equations or even differential equations; LLM无法解决复杂的数据公式
- LLMs are highly inefficient at expressing iteration, especially when the number of iteration steps is large. LLM无法很好的处理迭代
Solution: 作者提出,应该把计算过程从CoT中分离,让其它的外部工具如Python interpreter来解决。这一思想本质上,和前面提到的PAL、faithful CoT是一样的。
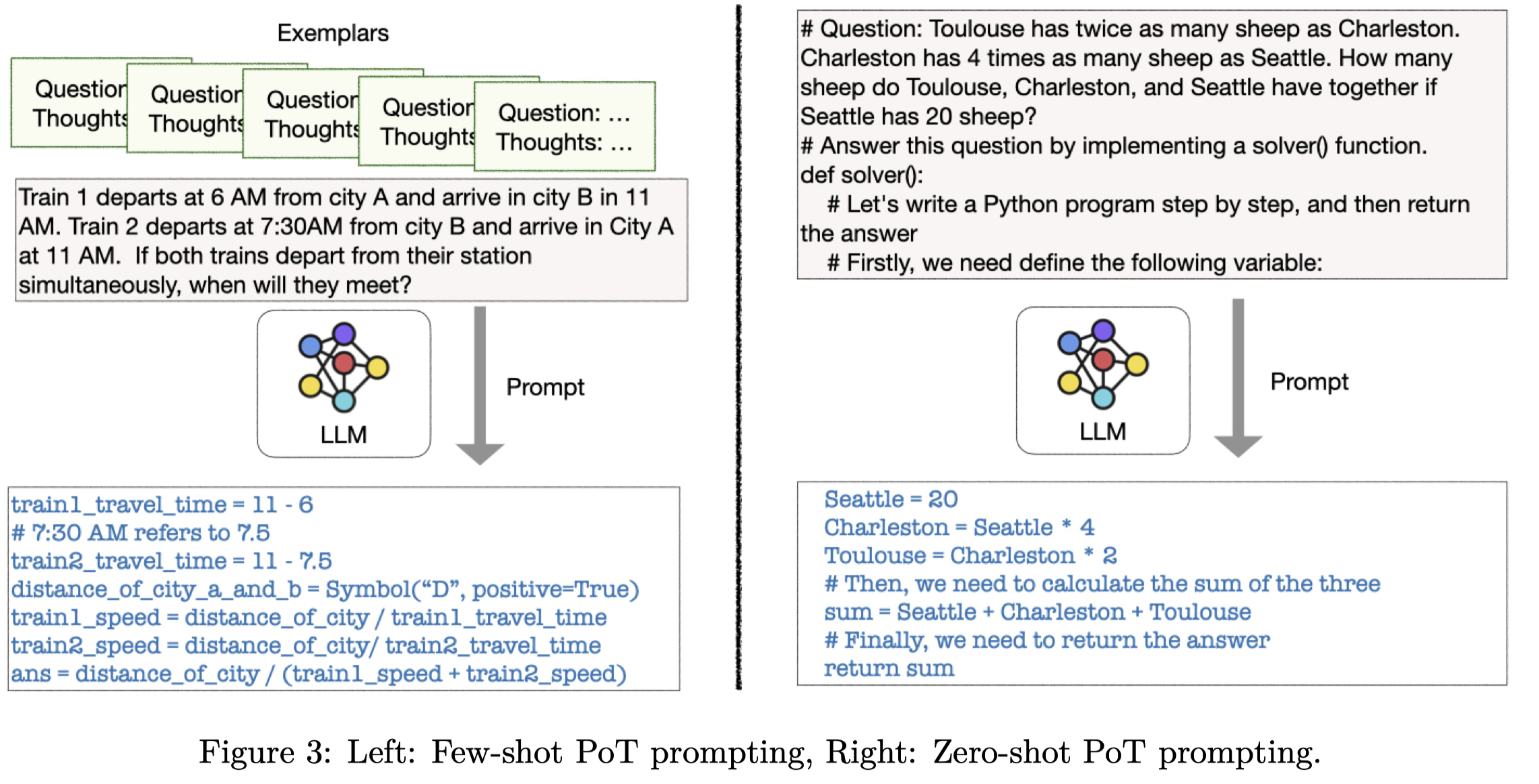
zero-shot PoT利用python comment来诱导LLM生成对应的代码,以及获得答案。和zero-shot CoT相比,可以直接一步获得reason chain以及answer。
PoT也可以作为pipline的中间步骤,再结合CoT来解决问题:
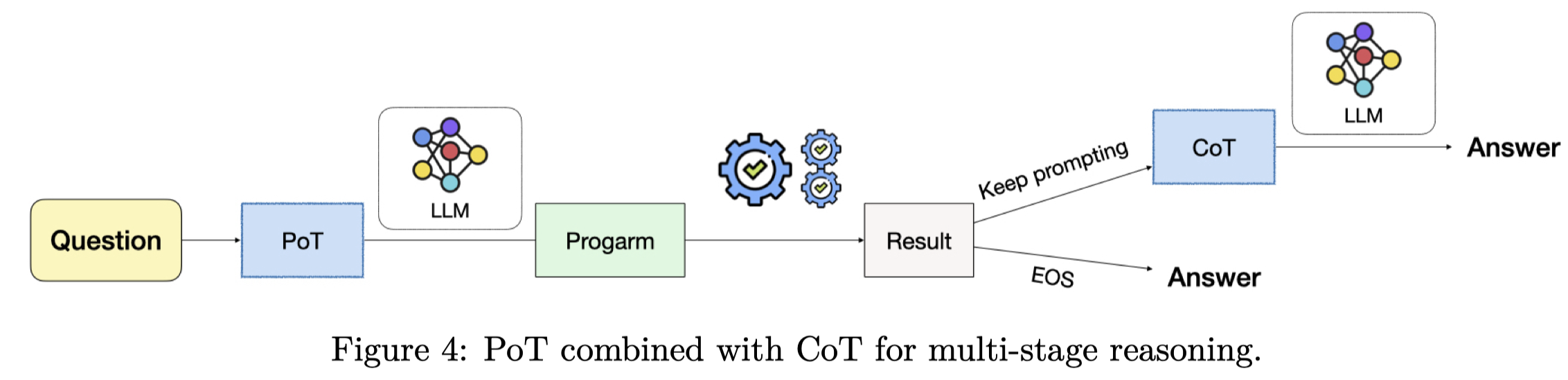
实验部分,作者主要使用code-davinci-002,但同时使用了text-davinci-002, gpt-turbo-3.5, codegen-16B, CodeT5+, Xgen用于消融实验。在在Math Word Problems,QA数据集上进行实验
SatLM
SatLM: Satisfiability-Aided Language Models Using Declarative Prompting. The University of Texas at Austin. NeurIPS 2023. 代码.
Prior work has combined chain-of-thought prompting in large language models (LLMs) with programmatic representations to perform effective and transparent reasoning. While such an approach works well for tasks that only require forward reasoning (e.g., straightforward arithmetic), it is less effective for constraint solving problems that require more sophisticated planning and search. In this paper, we propose a new satisfiability-aided language modeling (SatLM) approach for improving the reasoning capabilities of LLMs. We use an LLM to generate a declarative task specification rather than an imperative program and leverage an off-the-shelf automated theorem prover to derive the final answer. This approach has two key advantages. The declarative specification is closer to the problem description than the reasoning steps are, so the LLM can parse it out of the description more accurately. Furthermore, by offloading the actual reasoning task to an automated theorem prover, our approach can guarantee the correctness of the answer with respect to the parsed specification and avoid planning errors in the solving process. We evaluate SatLM on 8 different datasets and show that it consistently outperforms program-aided LMs in the imperative paradigm. In particular, SatLM outperforms program-aided LMs by 23% on a challenging subset of the GSM arithmetic reasoning dataset; SatLM also achieves a new SoTA on LSAT and BOARDGAMEQA, surpassing previous models that are trained on the respective training sets.
Issue:作者认为的解决复杂推理所需3步:
- parsing a natural language description into a representation of the problem
- deriving a plan to solve the problem
- executing that plan to obtain an answer.
PoT、faithful CoT等方法通过修复execution error来提高推理性能。将CoT表示为program,意味着推理的顺序,就是执行的顺序。这种做法适合于原始question已经隐含了某种解决问题的plan。但是对于解决更加复杂的问题没有帮助,比如存在很多premises,要求能够进行演绎推理,求满足约束的答案的任务。
Solution: 作者的方法,LLM只负责理解question中的各种状态、约束等,然后负责将自然语言NL question转化为逻辑表达式。具体求解通过调用外部solver来解决。

作者认为将推理过程表示为program,属于是命令式。在这篇论文中,作者提出使用声明Declarative的方法。和之前的PoT等program CoT方法比较,作者的方法让LLM进一步只关注如何理解问题即可:
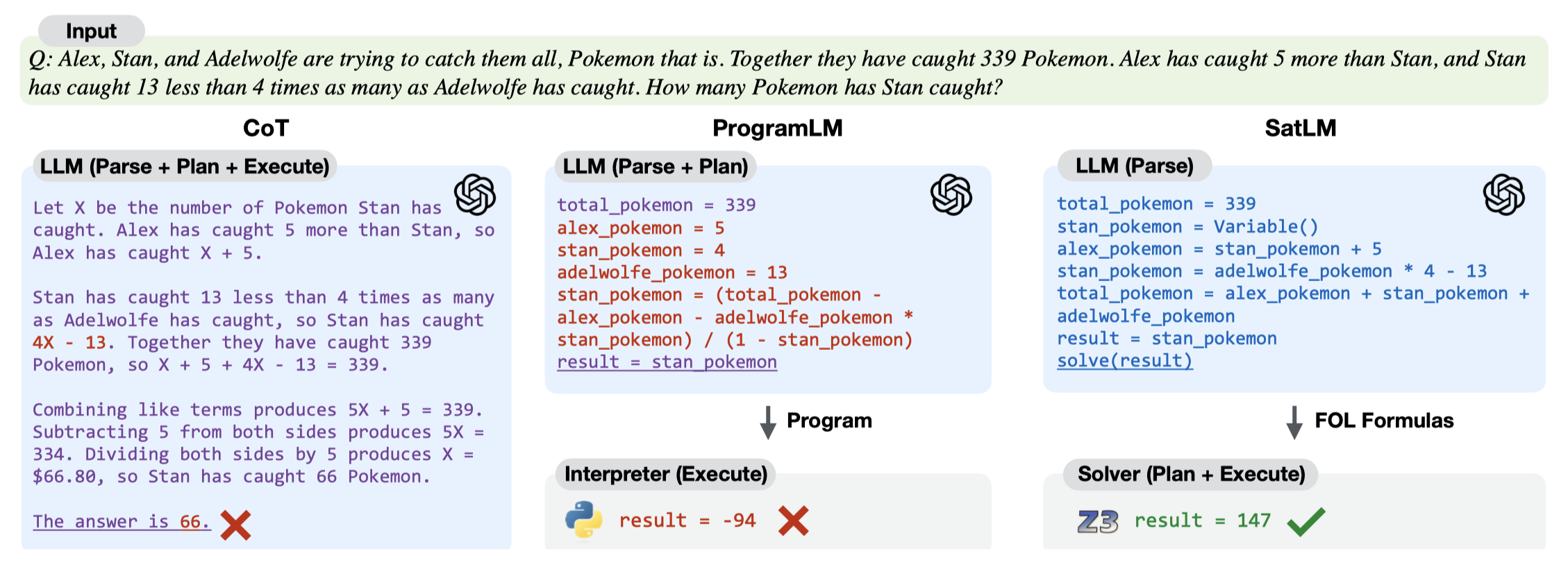
作者人工为几个样例写出对应的SAT问题(SATisfiability problem),然后作为demonstrations,让LLM将原始问题转化为SAT问题。作者定义的SAT问题是\(P=\{ \Phi, \mathcal{T},Q \}\),其中的\(\Phi\)表示set of first-order logic formulas;\(\mathcal{T}\)表示the meaning of some of the symbols used in the formula;\(Q\)表示query。一个简单的SAT实例:

之后调用外部的推理工具来解决该问题,any automated reasoning tool for checking the satisfiability of formulas in formal logic.
利用这种外部solver比单纯的program的好处之一是,它可以返回更多的错误信息,比如存在互相冲突的条件unsatisfiable formulas (UNSAT)、存在多种可行解ambiguous formulas (AMBIG)等。
作者实验基于code-davinci-002,在arithmetic reasoning和logical reasoning tasks任务上进行了实验。